溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何分析Spark中大數據產品的測試方法與實現,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
Spark作為現在主流的分布式計算框架,已經融入到了很多的產品中作為ETL的解決方案。 而我們如果想要去測試這樣的產品就要對分布式計算的原理有個清晰的認知并且也要熟悉分布式計算框架的使用來針對各種ETL場景設計不同的測試數據。 而一般來說我們需要從以下兩個角度來進行測試。
ETL能兼容各種不同的數據(不同的數據規模,數據分布和數據類型)
ETL處理數據的正確性
測試數據兼容
ETL是按一定規則針對數據進行清洗,抽取,轉換等一系列操作的簡寫。那么一般來說他要能夠處理很多種不同的數據類型。 我們在生產上遇見的bug有很大一部分占比是生產環境遇到了比較極端的數據導致我們的ETL程序無法處理。 比如:
數據擁有大量分片
在分布式計算中,一份數據是由多個散落在HDFS上的文件組成的, 這些文件可能散落在不同的機器上, 只不過HDFS會給使用者一個統一的視圖,讓使用者以為自己在操作的是一個文件,而不是很多個文件。 這是HDFS這種分布式文件系統的存儲方式。 而各種分布式計算框架, 比如hadoop的MapReduce,或者是spark。 就會利用這種特性,直接讀取散落在各個機器上文件并保存在那個節點的內存中(理想狀態下,如果資源不夠可能還是會發生數據在節點間遷移)。
而讀取到內存中的數據也是分片的(partition)。 spark默認以128M為單位讀取數據,如果數據小于這個值會按一個分片存儲,如果大于這個值就繼續往上增長分片。 比如一個文件的大小是130M, spark讀取它的時候會在內存中分成兩個partition(1個128M,1個2M)。 如果這個文件特別小,只有10M,那它也會被當做一個partition存在內存中。 所以如果一份數據存放在HDFS中,這個數據是由10個散落在各個節點的文件組成的。 那么spark在讀取的時候,就會至少在內存中有10個partition, 如果每個文件的大小都超過了128M,partition的數量會繼續增加。
而在執行計算的時候,這些存儲在多個節點內存中的數據會并發的執行數據計算任務。 也就是說我們的數據是存放在多個節點中的內存中的, 我們為每一個partition都執行一個計算任務。 所以我們針對一個特別大的數據的計算任務, 會首先把數據按partition讀取到不同節點的不同的內存中, 也就是把數據拆分成很多小的分片放在不同機器的內存中。 然后分別在這些小的分片上執行計算任務。 最后再聚合每個計算任務的結果。 這就是分布式計算的基本原理。
那么這個時候問題就來了, 這種按partition為單位的分布式計算框架。partition的數量決定著并發的數量。 可以理解為,如果數據有100個partition,就會有100個線程針對這份數據做計算任務。所以partition的數量代表著計算的并行程度。 但是不是說partition越多越好,如果明明數據就很小, 我們卻拆分了大量的partition的話,反而是比較慢的。 而且所有分片的計算結果最后是要聚合在一個地方的。 這些都會造成網絡IO的開銷(因為數據是在不同的節點之前傳輸的)。 尤其是在分布式計算中,我們有shuffle這個性能殺手(不熟悉這個概念的同學請看我之前的文章)。 在大量的分片下執行shuffle將會是一個災難,因為大量的網絡IO會導致集群處于很高的負載甚至癱瘓。 我們曾經碰見過只有500M但是卻有7000個分片的數據,那一次的結果是針對這個數據并行執行了多個ETL程序后,整個hadoop集群癱瘓了。 這是在數據預處理的時候忘記做reparation(重新分片)的結果。
數據傾斜
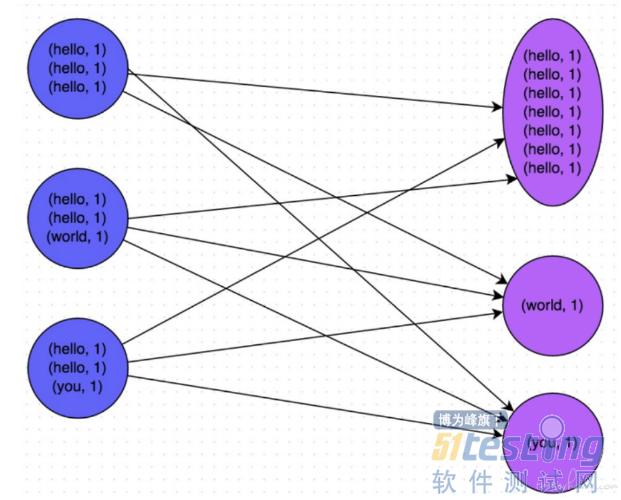
在上面的任務處理中出現了shuffle的操作。shuffle也叫洗牌, 在上面講partition和分布式計算原理的時候,我們知道分布式計算就是把數據劃分很多個數據片存放在很多個不同的節點上, 然后在這些數據片上并發執行同樣的計算任務來達到分布式計算的目的,這些任務互相是獨立的, 比如我們執行一個count操作, 也就是計算這個數據的行數。 實際的操作其實是針對每個數據分片,也就是partition分別執行count的操作。 比如我們有3個分片分別是A,B,C, 那執行count的時候其實是并發3個線程,每個線程去計算一個partition的行數, 他們都計算完畢后,再匯總到driver程序中, 也就是A,B,C這三個計算任務的計算過程是彼此獨立互不干擾的,只在計算完成后進行聚合。
但并不是所有的計算任務都可以這樣獨立的,比如你要執行一個groupby的sql操作。 就像上面的圖中,我要先把數據按單詞分組,之后才能做其他的統計計算, 比如統計詞頻或者其他相關操作。 那么首先spark要做的是根據groupby的字段做哈希,相同值的數據傳送到一個固定的partition上。 這樣就像上圖一樣,我們把數據中擁有相同key值的數分配到一個partition, 這樣從數據分片上就把數據進行分組隔離。
然后我們要統計詞頻的話,只需要才來一個count操作就可以了。 shuffle的出現是為了計算能夠高效的執行下去, 把相似的數據聚合到相同的partition上就可以方便之后的計算任務依然是獨立隔離的并且不會觸發網絡IO。 這是方便后續計算的設計模式,也就是節省了后續一系列計算的開銷。 但代價是shuffle本身的開銷,而且很多情況下shuffle本身的開銷也是很大的。 尤其是shuffle會因為數據傾斜而出現著名的長尾現象。
根據shuffle的理論,相似的數據會聚合到同一個partition上。 但是如果我們的數據分布不均勻會出現什么情況呢? 比如我們要針對職業這個字段做groupby的操作, 但是如果100W行數據中有90W行的數據都是程序員這個職業的話, 會出現什么情況? 你會發現有90W行的數據都跑到了同一個partition上造成一個巨大的partition。這樣就違背了分布式計算的初衷, 分布式計算的初衷就是把數據切分成很多的小數據分布在不同的節點內存中,利用多個節點的并行計算能力來加速計算過程。
但是現在我們絕大部分的數據都匯聚到了一個partition中,這樣就又變成了單點計算。 而且這里還有一個特別大的問題, 就是我們在提交任務到hadoop yarn上的時候,申請的資源是固定且平均分配的。 比如我申請10個container去計算這份數據,那這10個container的資源是相等的,哪個也不多,哪個也不少。 但是我們的數據分片的大小卻是不一樣的, 比如90W行的分片需要5個G的內存,但是其他的數據分片可能1個G就夠了。 所以如果我們不知道有數據傾斜的情況出現而導致申請的資源教少,就會導致任務OOM而掛掉。 而如果我們為了巨大的數據分片為每個container都申請了5G的資源, 那又造成了資源浪費。
數據傾斜和shuffle是業界經典難題,很難處理。 在很多大數據產品中都會有根據數據大小自動調整申請資源的功能。而數據傾斜就是這種功能絕對的天敵。 處理不好的話,要不會變成申請過大資源承包集群,要不會申請過小資源導致任務掛掉。 而我們在測試階段要做的,就是模擬出這種數據傾斜的數據, 然后驗證ETL程序的表現。
寬表
列數太多的表就是寬表。比如我見過的最寬的表是1W列的, 尤其在機器學習系統中, 由于要抽取高維特征, 所以在ETL階段經常會把很多的表拼接成一個很大的寬表。這種寬表是數據可視化的天敵,比如我們的功能是可以隨機預覽一份數據的100行。 那100*1W這樣的數據量要傳輸到前端并渲染就是個很費事的操作了。尤其是預覽本身也是要執行一些計算的。如果加上這份數據本來就有海量分片的話, 要在后臺打開這么多的文件,再加上讀取這么寬的表的數據。 甚至有可能OOM, 實際上我也確實見過因為這個原因OOM的。 所以這個測試點就是我們故意去造這樣的寬表進行測試。
其他的數據類型不一一解釋了, 都跟字面的意思差不多。
造數
之所以也使用spark這種分布式框架來造數,而不是單獨使用parquet或者hdfs的client是因為我們造的數據除了要符合一些極端場景外,也要保證要有足夠的數據量, 畢竟ETL都是面對大數據場景的。 所以利用spark的分布式計算的優勢可以在短時間內創建大量數據。 比如我前兩天造過一個1億行,60個G的數據,只用了20分鐘。
技術細節
RDD是spark的分布式數據結構。 一份數據被spark讀取后會就生成一個RDD,當然RDD就包含了那些partition。 我們創建RDD的方式有兩種, 一種是從一個已有的文件中讀取RDD,當然這不是我們想要的效果。 所以我們使用第二種, 從內存中的一個List中生成RDD。 如下:
public class Demo { public static void main(String[] args) { SparkConf conf = new SparkConf().setAppName("data produce") .setMaster("local"); JavaSparkContext sc = new JavaSparkContext(conf); SparkSession spark = SparkSession .builder() .appName("Java Spark SQL basic example") .getOrCreate(); List data = new XRange(1000); JavaRDD distData = sc.parallelize(data, 100);上面是我寫的一個demo,前面初始化spark conf和spark session的代碼可以先忽略不用管。 主要看最后兩行, XRange是我仿照python的xrange設計的類。 可以幫我用類似生成器的原理創建一個帶有index序列的List。 其實這里我們手動創建一個list也行。 而最后一行就是我們通過spark的API把一個List轉換成一個RDD。sc.parallelize的第一個參數是List,而第二個參數就是你要設置的并行度, 也可以理解為你要生成這個數據的partition的數量。 其實如果我們現在想生成這一千行的只有index的數據的話, 再調用這樣一個API就可以了:distData.saveAsTextFile("path"); 通過這樣一個API就可以直接保存文件了。 當然這樣肯定不是我們想要的,因為里面還沒有我們要的數據。 所以這個時候我們要出動spark的一個高級接口,dataframe。 dataframe是spark仿照pandas的dataframe的設計開發的高級API。 功能跟pandas很像, 我們可以把一個dataframe就當做一個表來看, 而它也有很多好用的API。 最重要的是我們有一個DataframeWriter類專門用來將dataframe保存成各種各樣格式和分區的數據的。 比如可以很方便的保存為scv,txt這種傳統數據, 可以很方便保存成parquet和orc這種列式存儲的文件格式。 也提供partition by的操作來保存成分區表或者是分桶表。總之它能夠幫我們造出各種我們需要的數據。 那么我們如何把一個RDD轉換成我們需要的dataframe并填充進我們需要的數據呢。 往下看:
List fields = new ArrayList<>(); String schemaString = "name,age"; fields.add(DataTypes.createStructField("name", DataTypes.StringType, true)); fields.add(DataTypes.createStructField("age", DataTypes.IntegerType, true)); StructType schema = DataTypes.createStructType(fields); // Convert records of the RDD (people) to Rows JavaRDD rowRDD = distData.map( record ->{ RandomStringField randomStringField = new RandomStringField(); randomStringField.setLength(10); BinaryIntLabelField binaryIntLabelField = new BinaryIntLabelField(); return RowFactory.create(randomStringField.gen(), binaryIntLabelField.gen()); }); Dataset dataset =spark.createDataFrame(rowRDD, schema); dataset.persist(); dataset.show(); DataFrameWriter writer = new DataFrameWriter(dataset); writer.mode(SaveMode.Overwrite).partitionBy("age"). parquet("/Users/sungaofei/gaofei");dataframe中每一個數據都是一行,也就是一個Row對象,而且dataframe對于每一列也就是每個schema有著嚴格的要求。 因為它是一個表么。所以跟數據庫的表或者pandas中的表是一樣的。要規定好每一列的schema以及每一行的數據。 所以首先我們先定義好schema, 定義每個schema的列名和數據類型。 然后通過DataTypes的API創建schema。 這樣我們的列信息就有了。 然后是關鍵的我們如何把一個RDD轉換成dataframe需要的Row并且填充好每一行的數據。 這里我們使用RDD的map方法, 其實dataframe也是一個特殊的RDD, 這個RDD里的每一行都是一個ROW對象而已。 所以我們使用RDD的map方法來填充我們每一行的數據并把這一行數據轉換成Row對象。
JavaRDD rowRDD = distData.map( record ->{ RandomStringField randomStringField = new RandomStringField(); randomStringField.setLength(10); BinaryIntLabelField binaryIntLabelField = new BinaryIntLabelField(); return RowFactory.create(randomStringField.gen(), binaryIntLabelField.gen()); });因為之前定義schema的時候只定義了兩列, 分別是name和age。 所以在這里我分別用一個隨機生成String類型的類和隨機生成int類型的類來填充數據。 最后使用RowFactory.create方法來把這兩個數據生成一個Row。 map方法其實就是讓使用者處理每一行數據的方法, record這個參數就是把行數據作為參數給我們使用。 當然這個例子里原始RDD的每一行都是當初生成List的時候初始化的index序號。 而我們現在不需要它, 所以也就沒有使用。 直接返回隨機字符串和int類型的數。 然后我們有了這個每一行數據都是Row對象的RDD后。 就可以通過調用下面的API來生成dataframe。
Dataset dataset =spark.createDataFrame(rowRDD, schema);
分別把row和schema傳遞進去,生成dataframe的表。 最后利用DataFrameWriter保存數據。
好了, 這就是造數的基本原理了, 其實也是蠻簡單的。 當然要做到嚴格控制數據分布,數據類型,特征維度等等就需要做很多特殊的處理。 這里就不展開細節了。
測試ETL處理的正確性
輸入一份數據,然后判斷輸出的數據是否是正確的。 只不過我們這是在大數據量下的處理和測試,輸入的數據是大數據,ELT輸出的也是大數據, 所以就需要一些新的測試手段。 其實這個測試手段也沒什么新奇的了, 是我們剛才一直在講的技術,也就是spark這種分布式計算框架。 我們以spark任務來測試這些ETL程序,這同樣也是為了測試自身的效率和性能。 如果單純使用hdfs client來讀取文件的話, 掃描那么大的數據量是很耗時的,這是我們不能接受的。 所以我們利用大數據技術來測試大數據功能就成為了必然。 當然也許有些同學會認為我只是測試功能么,又不是測試算法的處理性能,沒必要使用那么大的數據量。 我們用小一點的數據,比如一百行的數據就可以了。 但其實這也是不對的, 因為在分布式計算中, 大數量和小數據量的處理結果可能不是完全一致的, 比如隨機拆分數據這種場景在大數據量下可能才能測試出bug。 而且大數據測試還有另外一種場景就是數據監控, 定期的掃描線上數據,驗證線上數據是否出現異常。 這也是一種測試場景,而且線上的數據一定是海量的。
廢話不多說,直接看下面的代碼片段。
@Features(Feature.ModelIde) @Stories(Story.DataSplit) @Description("使用pyspark驗證隨機拆分中的分層拆分") @Test public void dataRandomFiledTest(){ String script = "# coding: UTF-8\n" + "# input script according to definition of \"run\" interface\n" + "from trailer import logger\n" + "from pyspark import SparkContext\n" + "from pyspark.sql import SQLContext\n" + "\n" + "\n" + "def run(t1, t2, context_string):\n" + " # t2為原始數據, t1為經過數據拆分算子根據字段分層拆分后的數據\n" + " # 由于數據拆分是根據col_20這一列進行的分層拆分, 所以在這里分別\n" + " # 對這2份數據進行分組并統計每一個分組的計數。由于這一列是label\n" + " # 所以其實只有兩個分組,分別是0和1\n" + " t2_row = t2.groupby(t2.col_20).agg({\"*\" : \"count\"}).cache()\n" + " t1_row = t1.groupby(t1.col_20).agg({\"*\" : \"count\"}).cache()\n" + " \n" + " \n" + " t2_0 = t2_row.filter(t2_row.col_20 == 1).collect()[0][\"count(1)\"]\n" + " t2_1 = t2_row.filter(t2_row.col_20 == 0).collect()[0][\"count(1)\"]\n" + " \n" + " t1_0 = t1_row.filter(t1_row.col_20 == 1).collect()[0][\"count(1)\"]\n" + " t1_1 = t1_row.filter(t1_row.col_20 == 0).collect()[0][\"count(1)\"]\n" + " \n" + " # 數據拆分算子是根據字段按照1:1的比例進行拆分的。所以t1和t2的每一個分組\n" + " # 都應該只有原始數據量的一半\n" + " if t2_0/2 - t1_0 >1:\n" + " raise RuntimeError(\"the 0 class is not splited correctly\")\n" + " \n" + " if t2_1/2 - t1_1 >1:\n" + " raise RuntimeError(\"the 1 class is not splited correctly\")\n" + "\n" + " return [t1]";我們用來掃描數據表的API仍然是我們之前提到的dataframe。上面的代碼片段是我們嵌入spark任務的腳本。 里面t1和t2都是dataframe, 分別代表原始數據和經過數據拆分算法拆分后的數據。 測試的功能是分層拆分。 也就是按某一列按比例抽取數據。 比如說100W行的數據,我按job這個字段分層拆分, 我要求的比例是30%。 也即是說每種職業抽取30%的數據出來,相當于這是一個數據采樣的功能。 OK, 所以在測試腳本中,我們分別先把原始表和經過采樣的表按這一列進行分組操作, 也就是groupby(col_20)。 這里我選擇的是按col_20進行分層拆分。 根據剛才講的這樣的分組操作后會觸發shuffle,把有相同職業的數據傳到一個數據分片上。 然后我們做count這種操作統計每一個組的行數。 因為這個算法我是按1:1拆分的,也就是按50%采樣。 所以最后我要驗證拆分后的數據的每一組的行數都是原始數據中該組的一半。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





