溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“在R、Python和Julia中常用的數據可視化技術是什么”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“在R、Python和Julia中常用的數據可視化技術是什么”吧!
對于數據科學和商業分析領域的用戶或研究人員來說,使用各種類型的圖形、餅圖、條形圖以及其他視覺手段展示數據中隱含的潛在趨勢或模式對理解數據至關重要,同時能夠幫助研究人員更好地向觀眾或客戶呈現數據。這樣做主要有以下幾個原因。
第一,語言有時很難描述我們的發現,尤其是存在幾種模式或諸多影響因素時,通過幾個單獨的圖形和一個連接圖則可以更好地理解和解釋復雜的關系。
第二,我們可以使用圖形或圖片來解釋某些算法。
第三,我們也可以使用相對大小來表示不同的含義。在金融領域,一個基本概念叫作貨幣時間價值(Time Value of Money,TVM),意思是“一鳥在手勝過雙鳥在林”。今天的100美元比同等數額的未來現金流更有價值。通過不同尺寸的不同圓圈表示發生在未來不同時間點上的現金流的現值,可以幫助讀者更清楚地理解這個概念。
第四,我們的數據可能非常混亂,所以簡單地展示數據點可能會使讀者更加困惑。如果我們能用一個簡單的圖形來展示它的主要特征、屬性或模式將大有益處。
首先,我們來看R中最簡單的圖形。利用下面一行R代碼,我們畫出了從
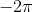
到
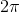
范圍內的余弦函數值:
> plot(cos,-2*pi,2*pi)
對應的圖形如圖4.1所示。
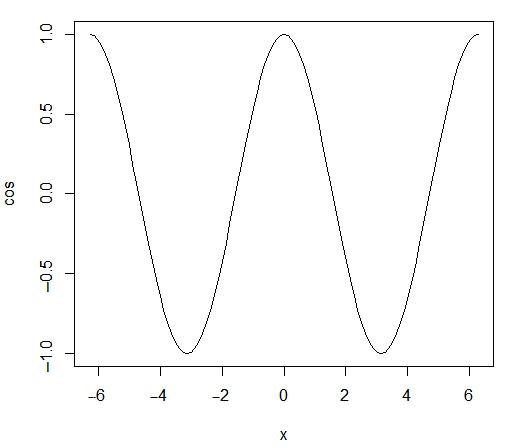
圖4.1 余弦函數圖
直方圖也有助于我們理解數據點的分布。圖4.1就是一個簡單的例子。首先,我們生成一組服從標準正態分布的隨機數。為了便于說明,第一行的set.seed()命令其實是多余的,它的存在將保證所有使用相同seed值(本例中為333)的用戶將得到相同的隨機數集合。
換句話說,在輸入值相同的情況下,直方圖看起來將是一樣的。在下一行中,rnorm(n)函數畫出了n個服從標準正態分布的隨機數。接著,最后一行使用hist()函數生成一個直方圖:
> set.seed(333) > data<-rnorm(5000) > hist(data)
相關直方圖如圖4.2所示。
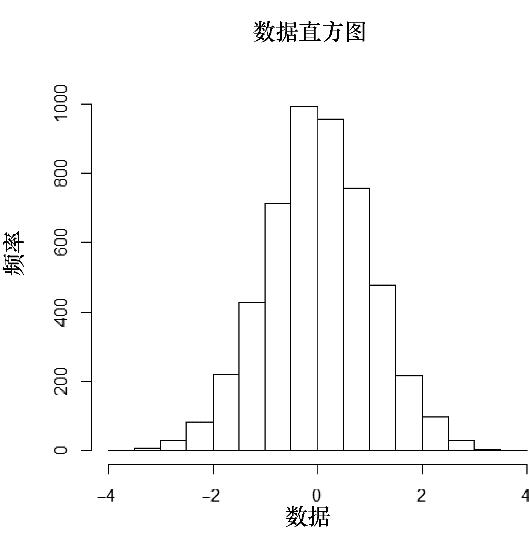
圖4.2 示例直方圖
注意,代碼rnorm(5000)與rnorm(5000,mean=0,sd=1)相同,其中含義為均值的默認值為0,sd的默認值為1。下一個R程序將為標準正態分布左側的尾巴填充陰影:
x<-seq(-3,3,length=100) y<-dnorm(x,mean=0,sd=1) title<-"Area under standard normal dist & x less than -2.33" yLabel<-"standard normal distribution" xLabel<-"x value" plot(x,y,type="l",lwd=3,col="black",main=title,xlab=xLabel,ylab=yLabel) x<-seq(-3,-2.33,length=100) y<-dnorm(x,mean=0,sd=1) polygon(c(-4,x,-2.33),c(0,y,0),col="red")
相關圖形如圖4.3所示。
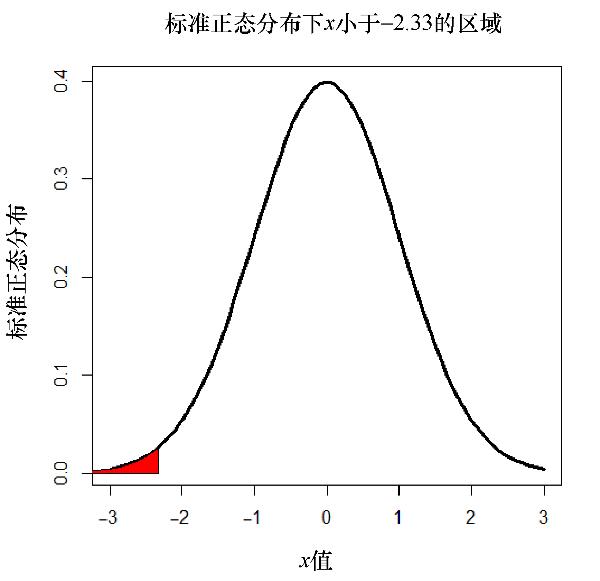
圖4.3 標準正態分布示例圖
注意,根據上面代碼中的最后一行可知,陰影區域為紅色。
在探索各種數據集的屬性方面,R包rattle非常有用。如果rattle包沒有預先安裝,那么我們可以運行以下代碼安裝它:
> install.packages("rattle")然后,運行以下代碼啟動它:
> library(rattle) > rattle()
單擊回車鍵后,可以看到圖4.4中的結果。
圖4.4 Rattle包啟動界面
首先,我們需要導入某些數據集。我們從7種可能的格式中選擇數據源,如文件、 ARFF、ODBC、R數據集和RData文件,并且可以從此處加載數據。
最簡單的方法是使用Library選項,它將列出rattle包中所有內嵌的數據集。單擊Library后,我們可以看到內嵌數據集的列表。假設單擊左上角的Execute后我們選擇了acme:boot:Monthly Excess Returns,那么我們將看到圖4.5中的界面。
圖4.5 導入數據集界面
現在,我們就可以研究數據集的屬性了。點擊Explore后,我們可以使用各種圖形來查看數據集。假設我們選擇Distribution,并勾選Benford復選框,那么我們就可以參考圖4.6來了解更多細節。

圖4.6 查看數據集屬性信息
單擊Execute之后,將彈出圖4.7所示內容。圖4.7上方的紅線顯示了根據本福特定律(Benford Law)算出的1~9每個數字的頻率,而底部的藍線則展示了數據集的屬性。請注意,如果你的計算機系統中還沒有安裝reshape包,則此命令要么無法運行,要么會請求許可將該包安裝到你的計算機上。
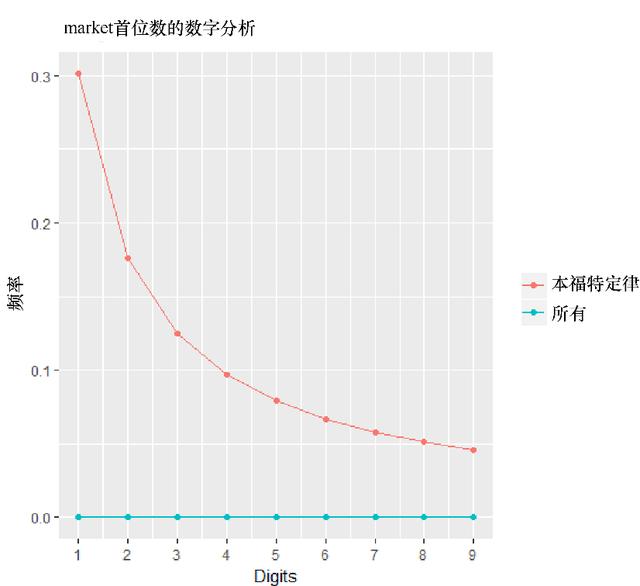
圖4.7 數據集的Benford定律符合情況
在圖4.7中,兩條線之間的巨大差異表明我們的數據不符合本福特定律建議的分布規律。在現實世界中,我們知道很多人、事件和經濟活動是相互關聯的,使用各種圖形來展示這樣一個多節點、相互連接的圖像是一個很好的辦法。如果沒有預裝qgraph包,那么用戶必須運行以下程序來安裝它:
> install.packages("qgraph")下一個程序展示了從a到b、a到c等節點之間的連接:
library(qgraph) stocks<-c("IBM","MSFT","WMT") x<-rep(stocks, each = 3) y<-rep(stocks, 3) correlation<-c(0,10,3,10,0,3,3,3,0) data <- as.matrix(data.frame(from =x, to =y, width =correlation)) qgraph(data, mode = "direct", edge.color = rainbow(9))如果將數據展示出來,該程序的意義就會更加清晰。相關性展示出這些股票之間聯系的緊密程度。注意,所有這些值都是隨機選擇的,并沒有現實意義。
> data from to width [1,] "IBM" "IBM" " 0" [2,] "IBM" "MSFT" "10" [3,] "IBM" "WMT" " 3" [4,] "MSFT" "IBM" "10" [5,] "MSFT" "MSFT" " 0" [6,] "MSFT" "WMT" " 3" [7,] "WMT" "IBM" " 3" [8,] "WMT" "MSFT" " 3" [9,] "WMT" "WMT" " 0"
第3個變量的值越大表明前面兩個變量的相關性越強。例如,IBM與MSFT的相關性更強(值為10),大于IBM與WMT的相關性(值為3)。圖4.8展示了這3只股票的相關性強弱程度。
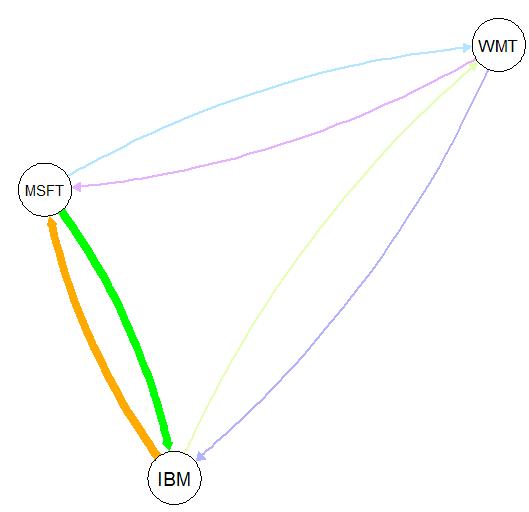
圖4.8 IBM、MSFT和WMT股票的相關性強弱程度
以下程序展示了5個因素之間的關系或相互聯系:
library(qgraph) data(big5) data(big5groups) title("Correlations among 5 factors",line = 2.5) qgraph(cor(big5),minimum = 0.25,cut = 0.4,vsize = 1.5, groups = big5groups,legend = TRUE, borders = FALSE,theme = 'gray')相關圖形如圖4.9所示。
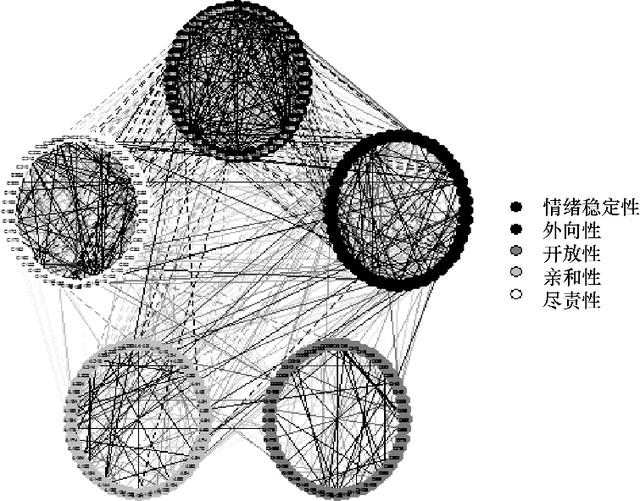
圖4.9 5個因素之間的相互聯系
Python中圖形和圖像方面使用最廣泛的包是matplotlib。下面的程序僅僅包含3行代碼,所以可以看作是最簡單的生成一個圖形的Python程序:
import matplotlib.pyplot as plt plt.plot([2,3,8,12]) plt.show()
第一行命令會上傳一個名為matplotlib.pyplot的Python包,并將其重命名為plt。
注意,我們甚至可以使用其他簡短的名稱,但通常使用plt表示matplotlib包。第二行繪制了4個點,最后一行總結了整個過程。完整圖形如圖4.10所示。
在下一個例子中,我們為x和y添加了標簽,以及一個標題。所使用的函數是余弦函數,其中輸入值范圍為
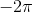
~
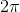
。
import scipy as sp import matplotlib.pyplot as plt x=sp.linspace(-2*sp.pi,2*sp.pi,200,endpoint=True) y=sp.cos(x) plt.plot(x,y) plt.xlabel("x-value") plt.ylabel("Cosine function") plt.title("Cosine curve from -2pi to 2pi") plt.show()
圖4.10 matplotlib包生成的圖形示例
漂亮的余弦曲線如圖4.11所示。
如果我們今天收到100美元,它將比兩年后收到的更有價值,這個概念叫作貨幣時間價值,因為我們現在可以將100美元存入銀行來賺取利息。下面的Python程序使用size來說明此概念。
import matplotlib.pyplot as plt fig = plt.figure(facecolor='white') dd = plt.axes(frameon=False) dd.set_frame_on(False) dd.get_xaxis().tick_bottom() dd.axes.get_yaxis().set_visible(False) x=range(0,11,2) x1=range(len(x),0,-1) y = [0]*len(x); plt.annotate("$100 received today",xy=(0,0),xytext=(2,0.15),arrowprops=dict(facecolor='black',shrink=2)) plt.annotate("$100 received in 2 years",xy=(2,0),xytext=(3.5,0.10),arrowprops=dict(facecolor='black',shrink= 2)) s = [50*2.5**n for n in x1]; plt.title("Time value of money ") plt.xlabel("Time (number of years)") plt.scatter(x,y,s=s); plt.show()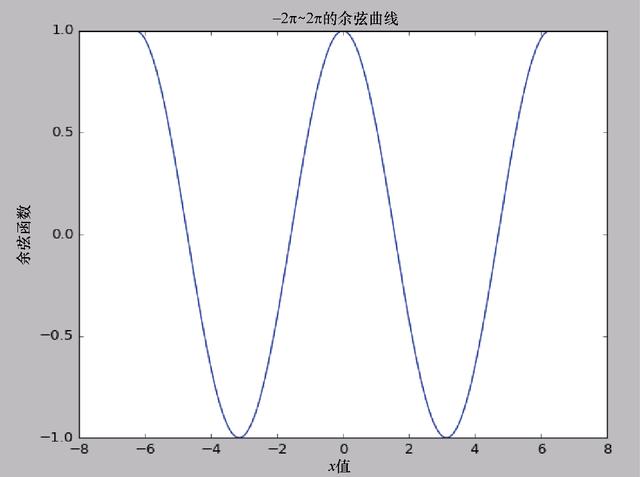
圖4.11 為圖形添加x和y軸標簽及標題
相關的圖形如圖4.12所示。同樣,不同尺寸表示它們現值的相對大小。
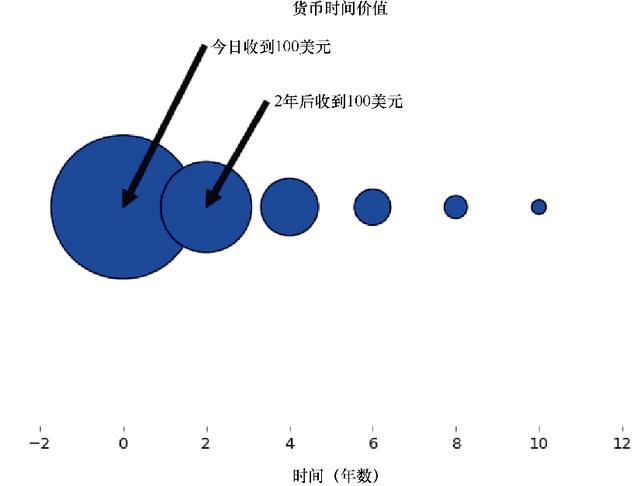
圖4.12 貨幣時間價值概念解釋
對于下面的Julia程序,我們使用了一個名為Plots的包,用于安裝此包的命令為Pkg.add("Plots")。這里,我們通過一個Jupyter notebook運行Julia程序。圖4.13展示了一個Julia程序。
圖4.13 Julia程序
單擊菜單欄上的Kernel項目,然后單擊Restart and Run All,我們得到圖4.14所示的結果。
圖4.14 運行結果圖
同樣地,srand(123)命令保證使用相同隨機種子的任何用戶都會得到相同的隨機數集合。為此,用戶會得到與前面相同的圖形。下一個例子是使用Julia包PyPlot繪制的散點圖。
using PyPlot n=50 srand(333) x = 100*rand(n) y = 100*rand(n) areas = 800*rand(n) fig = figure("pyplot_scatterplot",figsize=(10,10)) ax = axes() scatter(x,y,s=areas,alpha=0.5) title("using PyPlot: Scatter Plot") xlabel("X") ylabel("Y") grid("on")相關圖形如圖4.15所示。
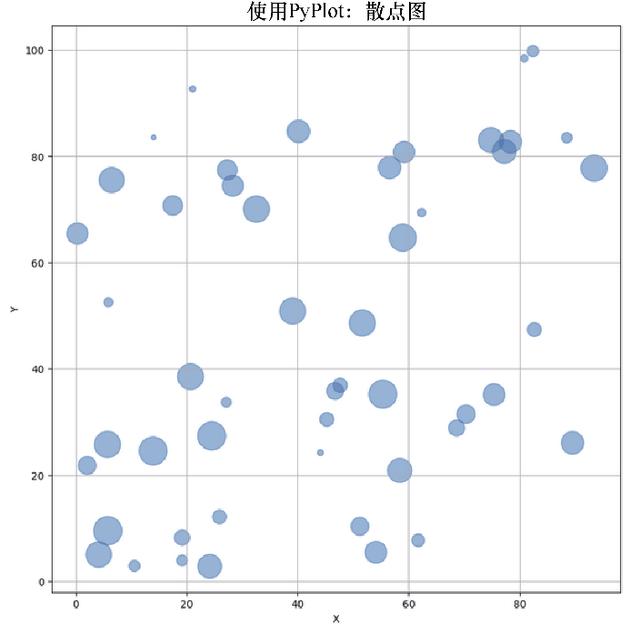
圖4.15 Julia包PyPlot繪制散點圖示例
下一個Julia程序借鑒自Sargent和Stachurski的程序。
using QuantEcon: meshgrid using PyPlot:surf using Plots n = 50 x = linspace(-3, 3, n) y = x z = Array{Float64}(n, n) f(x, y) = cos(x^2 + y^2) / (1 + x^2 + y^2) for i in 1:n for j in 1:n z[j, i] = f(x[i], y[j]) end end xgrid, ygrid = meshgrid(x, y) surf(xgrid, ygrid, z',alpha=0.7)令人印象深刻的圖形如圖4.16所示。
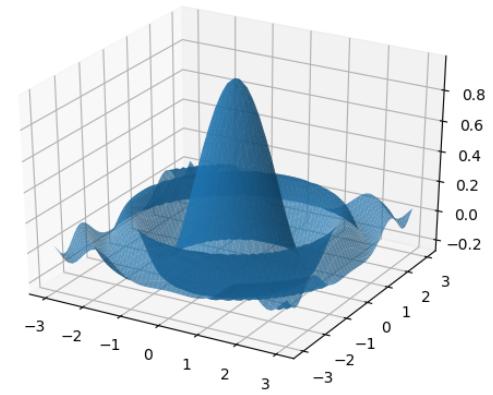
圖4.16 Sargent和Stachurski程序結果圖
感謝各位的閱讀,以上就是“在R、Python和Julia中常用的數據可視化技術是什么”的內容了,經過本文的學習后,相信大家對在R、Python和Julia中常用的數據可視化技術是什么這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





