溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關InnoDB中怎么插入數據,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
表空間/Tablespace
假如,我想成為一名文學家,立志寫一部長篇巨著,那么就需要把文字記錄在紙張上。第一步就是從造紙廠購買兩大卷未做裁切的白紙。相應的,在計算機中,所有數據也需要記錄在磁盤、磁帶、光盤等存儲介質上進行長期保存。
這些介質被劃分成文件,它們是存儲數據的物理空間。
由于我買了兩卷紙,而任何一卷都可以存儲文字,因此每當我開始下筆時,都費勁心思難以抉擇:到底應該記錄到哪一卷中?這對于有選擇困難癥的我來說苦不堪言。
于是,我計劃請一個秘書,把要寫的內容口述給他,通過他幫我文字謄寫到具體的紙卷上,至于到底寫在哪一卷上,我無所謂。
同理,用程序操作文件時,首先也需要指定文件路徑。可是在數據庫中,表是面向開發,而存儲設備是面向運維。開發創建表時,很難確定一張表對應哪個文件。而運維也會根據實際情況動態為數據庫添加文件。
表與文件的緊耦合嚴重制約了數據庫使用的便利性,于是在文件與表之間增加一層表空間便順理成章,它向上對接表,向下對接文件;開發者只需在表空間中操作表,而具體存儲由Innodb存儲引擎根據表空間自動維護。

表空間是InnoDB存儲引擎中邏輯結構的最高層,所有數據邏輯上都存儲在表空間中。
表空間主要包括以下幾種類型:
系統表空間 存儲change buffer, doublewrite buffer以及與innodb相關的所有對象的元數據。如:表空間和數據庫信息,表結構與字段信息等等。mysql8.0中移除了原先用于存儲表結構信息的.frm文件,所有元數據都存儲在此系統表空間中。系統表空間information_schema庫中相關的核心視圖如下:
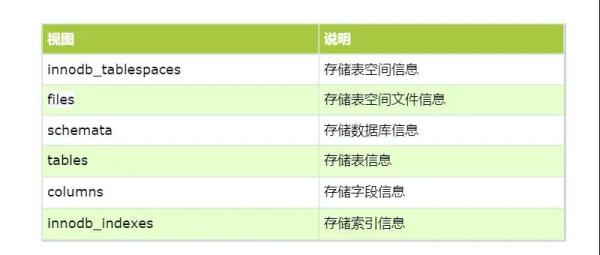
假如數據庫world中有一張對應表user表,測試如下:查詢表所屬表空間信息:select * from information_schema.innodb_tablespace where name='world/user'; (space:表空間id,name:表空間名)

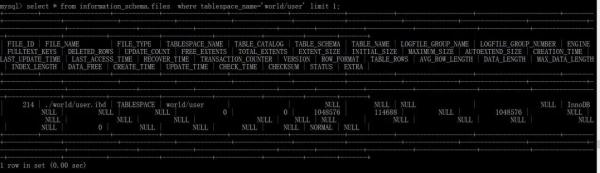
查詢表空間對應的數據文件信息:select * from information_schema.files where tablespace_name='world/user'; (file_name:數據文件相對路徑)
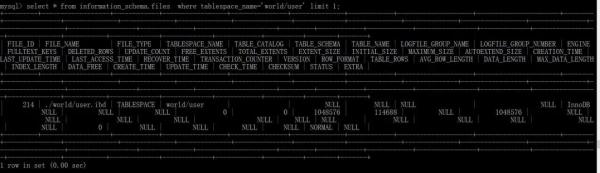
查詢表對應的id: select * from information_schema.innodb_tables where name='world/user';

查詢主鍵索引對應的根節點所在的頁號(root page no) select * from information_schema.innodb_indexes where table_id=1269 and name='primary'; (page_no:B+樹 root page no;name='primary'表示主鍵索引)

系統表空間也有對應的數據文件,這個文件默認為(windows下)xxx\MySQL Server 8.0\Data\ibdata1。只有系統表空間可以指定多個文件,其它類型的表空間都只能指定一個數據文件。
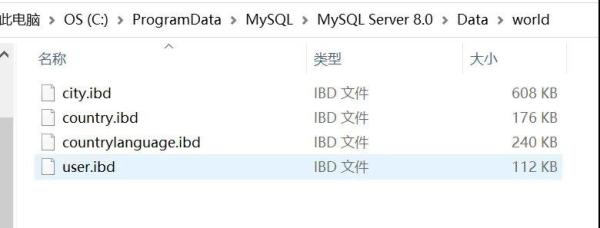
獨立表空間 每張表對應一個獨立的表空間。通過配置my.ini中的參數:innodb_file_per_table=1啟動獨立表空間,否則,默認為系統表空間。5.6.6之后此配置默認開啟,因此默認為獨立表空間。

當創建表時,會自動為表創建一個對應表名的表空間,并在數據庫目錄下生成一個“表名.ibd”的表空間文件。如:在數據庫world中創建user表結果如下
普通表空間 即通過“create tablespace 表空間名” 手動創建的表空間。
臨時表空間 存儲臨時表以及臨時表變化對應的回滾段。默認的臨時文件為(windows下)xxx\MySQL Server 8.0\Data\ibtmp1
區/簇/Extent
由于一卷原始的紙太過于龐大,展開后可能會鋪滿我豪宅地板十幾層,甚至幾十層,非常不方便使用,畢竟我9平米的豪宅還需要留出空間會客。最好的辦法就是把這些紙張切割成一張張A4大小的數據頁。
同理,一個磁盤或文件的容量也是非常可觀,極其不便管理,因此innodb把文件劃分成一個個大小相等的存儲塊,這些塊也被稱為頁;

對于一部文學故事而言,只要通過頁碼就可以依次找到下一頁,從而完整的讀完這個故事。通常我們讀完第一頁時,會馬上接著讀第二頁,但此時對應的書頁如果零散的分布在臥室、廁所、客廳,將使閱讀體驗大大折扣。如果能把這些分散的書頁合訂成本,就可以極大地提高閱讀的便利性。
根據局部性原理,cpu在使用的數據時,下一步也會大概率使用邏輯上相鄰的數據。因此為了提高數據讀操作的性能,innodb把邏輯上相臨的數據盡可能在物理上也存儲在相鄰的頁中;為了實現這一目標,Innodb引入了區/簇的概念;

一個區/簇是物理上連續分配的一段空間,extent又被劃分成連續的頁,以存儲同一邏輯單元的數據(如下面的索引段、數據段)。一個區/簇,默認由64個連續的頁(Page)組成,每個頁默認大小為16K。
實際上,innodb是先把文件劃分成連續的區/簇,然后在區/簇內再劃分出連續的頁,從總體上看:一個文件即是微觀上一系列連續的頁組成,也是宏觀上一系列連續的區/簇組成。知道一個頁的頁號和頁大小就可以計算出此頁在磁盤上的具體位置,同理知道一個頁號就可以計算出一個區/簇的大小以及頁所在的區/簇是第幾個區/簇(它本身沒有編號,但假設第一個區/簇為0號,可以知道它邏輯上是第幾個)。
如果把頁看作現實書本中的頁,那么extent可以看作現實中的書本。
區的目的是為邏輯單元分配連續的空間,同時也用于管理區內的存儲空間狀態(如:區內哪些頁已滿,哪些還未使用,哪些包含碎片)。具體通過不同的區/簇鏈表來指明區本身的空間狀態,以及通過XDES Entry中的XDES_BITMAP指明區內頁的空間狀態)。
###段/Segment
當年大劉寫完三體第一本后,遲遲沒有更新,但由于內容過于精彩,導致奧巴馬又是寫郵件,又是通過外交手段催更。為了避免中美關系受損,大劉如法炮制,又連續寫了兩本。
在邏輯上故事情連貫的這三本書總體上都叫三體,于是我們稱這種具有相關性的多本書為一套。同理,innodb把邏輯上有關聯的區/簇歸屬為一個段。

為了使同一邏輯單元可以在物理上具有連續的存儲空間,Innodb提出的區的概念,但是io的最小操作單元為頁,一次io并不能寫滿一個區,同時數據是可以擦除(刪除)重寫,因此必須記錄區自身以及區內的空間狀態:哪些區已寫滿,哪些區還未使用,哪些區還有碎片空間。
innodb中把這些記錄具有相關性區的存儲空間狀態的管理信息稱為段實體,段實體所管理的區的總和稱為段。段的目的是管理區的使用情況以及為數據分配空間時,提供空間存儲狀態。
段可以類似的看做現實中一套書中的套。
innodb中數據是以B+樹的方式組織,葉子節點存儲關鍵字與行數據,非葉子節點存儲關鍵字(索引數據)與頁號。索引數據與業務行數據分別具有不同的數據結構,因此它們被分開存儲,非葉子節點的索引數據存儲在一個段中,葉子節點的業務數據存儲在另一個段,對應的它們也分別存儲在不同結構的區和頁中。
數據邏輯結構如下:
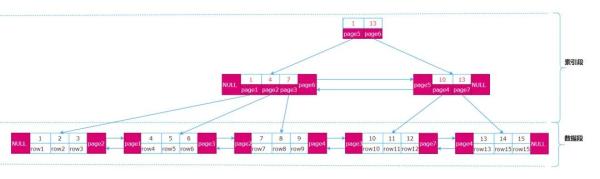
物理存儲結構如下:
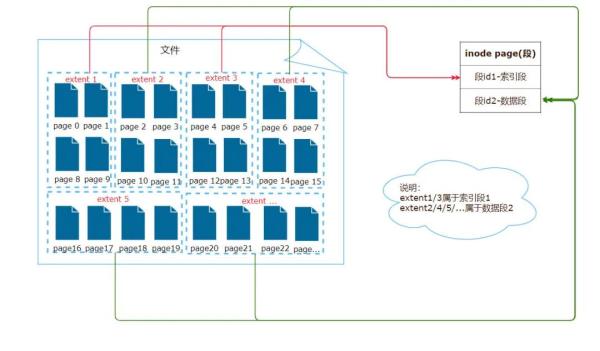
段是表空間的邏輯組成部分,用來存儲具有相同意義的數據,如:B+對中的非葉子節點或B+樹中的葉子節點。常見的段有數據段、索引段、回滾段等。
每創建一個索引就會創建兩個段:一個是數據段(B+樹對應的葉子節點),一個是索引段(非葉子節點)。對于聚集索引(一般是主鍵索引)數據段存儲的是索引關鍵字和業務行(所有字段);對于非聚集索引,數據段存儲的是索引關鍵字和主鍵;如果通過非聚集索引查詢,需要先通過B+樹查出主鍵,再通過主鍵從聚集索引中二次查詢具體的行,這稱為回表。下圖:左邊為二級索引(非聚集索引),右邊為主鍵索引(聚集索引)
表數據是通過聚集索引組織存儲,也即按主鍵索引創建的B+樹存儲數據,因此創建表時應該同時指定一個主鍵。如果沒有指定主鍵,也沒有創建唯一索引,表會默認創建一個自增的隱藏字段:row_id做為聚集索引B+樹的關鍵字段。因為是隱藏字段,所以這個字段只能回表查詢時使用。
頁/Page
正如上面所說,頁就像現實中一本書的書頁一樣,是innodb中io操作的最小單位。innodb中的頁類似于現實中書本的頁。
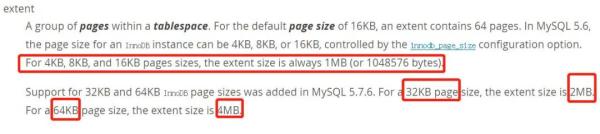
頁的大小默認是16KB;可以通過innodb_page_size參數指定,可選項為:4KB、8KB、16KB、32KB、64KB;當page size為4、8、16KB時,對應一個extent的page數量同步變化,以保證extent(區/簇)大小保持1M不變。當page size為32KB或64KB時,extent內的page數量保證不變,extent同步變為2M和4M;
每個頁都有一個對應的從0開始的編號,這個編號叫做頁號。因為表空間的數據文件會被劃分成大小相等的頁,所以知道頁號,再根據文件的初始位置,就可以計算出頁在磁盤中的準確地址。
同理,一張表對應一個聚集索引,而聚集索引元數據中指定了root page的頁號,因此Innodb引擎可以根據頁號和頁大小計算出索引B+樹root page的準確地址,從而對整個表數據進行操作。
page主要用來存儲業務相關的數據,但是為了管理內存分配而存在的extent和segment信息也需要page存儲。innodb根據page存儲內容不同分以下幾類:
FSP HDR 頁:一個表空間可能對應多個數據文件,每個文件都有自己的編號。表空間是數據庫中最頂層的結構,通過系統表空間中的元數據可以查詢對應的表空間文件等元信息,卻無法查詢當前表空間對應的段、區等信息,因此也無法獲取表空間中頁的存儲狀態。
為了使表空間的物理存儲有一個對外訪問的入口,規定表空間中的0號文件的0號page頁中存儲表空間信息以及當前表空間所擁有的段鏈表的指針。
任何一個頁都由頁頭、頁身和頁尾組成。
一個page默認16KB,而段和區對應的指針數據量并不大,因此只需要部分頭信息就可以維護。而剩下的大部分空間,則用來存儲當前表空間擁有的部分發區實體信息。

頁頭:指明當前頁號、類型和所屬表空間。頁尾:主要用于數據的校驗。頁身:這是頁中用來存儲數據的主要部分。
頁身又分為表空間首頁頭信息區和業務數據區。FSP HEADER:(1):表空間信息:對應空間id、表空間總頁數等 (2):段信息:已寫滿數據的段實體所在頁的鏈表指針、未寫滿數據的段實體所在頁的鏈表指針(指向的不是段實體而是段實體所在的頁,一頁存儲85個段實體)。(3):碎片區/簇信息:空閑的碎片區/簇(XDES實體本身,不是XEDS實體所在的頁)鏈表指針、未寫滿的碎片區鏈表指針、已寫滿的碎片區鏈表。這些區/簇信息不屬于任何段,而屬于表空間,用于給段下次申請空間時分配。
理論上一個區/簇會完整的分配給一個段,但一些區/簇創建后直接歸屬表空間,用做碎片區。為了減少浪費,只會把這些區中的部分頁分配給一個指定的段。
例如:當你豪言萬丈的宣布要寫一部曠世巨著,并要求秘書給你五百頁紙時,秘書很可能已經看透了一切,一面是是是的回應你,一面只會給你取3頁紙,因為他認為你很可能7天憋不出6個字。同理,innodb給某一個新創建的段分配空間時,并不是一開始就分配一個區/簇,而是從碎片區中先分配32頁,只有這32頁使用完,innodb才認為這個段是一個大數據段,從而正式開始為其分配一個完整的區/簇。
數據部分:
FSP HEADER中指向了段鏈表和碎片區鏈表,但這些只是鏈表指針,真正的區信息節點則存放在當前頁的數據區。一個區/簇信息實體稱為一個XDES Entry(eXtent DEScript);一頁存儲256個XDES Entry。
XDES Entry如上面圖示,包含了段id(如果分配給一個段)、碎片區鏈表中的下一個節點指針等。它不包含頁信息,因為區/簇有對應的物理空間,它空間內的頁就是擁有的頁,因此無需在entry中指明。
細心的朋友會發現,XDES Entry雖然是描述區/簇,但卻沒有指定區/簇的編號或地址,那么它到底對應物理空間中哪塊區/簇呢?
區/簇本身沒有編號,但區/簇像頁一樣,也是從文件第一個字節開始連續分配的。同時,每隔256個區/簇的第一個區的第一頁就是這256個區/簇的索引頁,即XDES page。
而XDES page有page No,因此就可以計算出此XDES page的地址,也即此page所有的區/簇的地址。緊接著的255個區/簇都有一個對應的XDES Entry存儲在XDES page中,這些XDES Entry在此page中位置的偏移量,即為后面255個區/簇的偏移量,從當前XDES page所有區/簇位置以及對應的偏移量就可以計算出一個XDES Entry對應的區/簇的物理位置。
FSP HDR頁就像一個表空間的封面頁,是整個表空間的入口頁。
XDES 頁:XDES 頁即eXtent DEScript 區/簇描述頁的縮寫,用來存儲區/簇信息實體的頁,即存儲XDES Entry的頁。它除了與FSP頁中FSP HEADER不同外,其它內容一模一樣。本質上首頁也是一個XDES頁,只是首頁是整個表空間的第一頁,因此它又兼職記錄了表空間信息。
XDES Entry:存儲了區自身信息的邏輯塊。
因為一頁XDES只能存儲256個entry,對應256個區,因此邏輯上每隔256個區,就需要一個xdex頁來存儲下一系列256個區的信息。
INODE 頁:同區/簇對應的Entry信息一樣,表空間只是指向了各種狀態的段頁(非段實體)鏈表,而未存儲段信息本身。inode頁就是用來存儲描述段信息 inode entry的頁。

一個inode頁默認存儲85條段實體,每個實體又指向了本段對應的不同狀態的區/簇鏈表:未使用的區/簇鏈表、已寫滿的區/簇鏈表、未寫滿的區/簇鏈表。
Index 頁 以上的頁均是存儲物理空間使用狀態,并用于管理區/簇和段本身的頁。index頁則是用于最終存儲業務數據。innodb中表數據是通過聚集索引組織存儲的,而葉子節點存儲在一個段中,非葉子節點存儲在另一個段中,但最終都會存儲在Index類型的頁中。
index頁詳細項如下圖:

index頁頁內存儲結構如下圖:
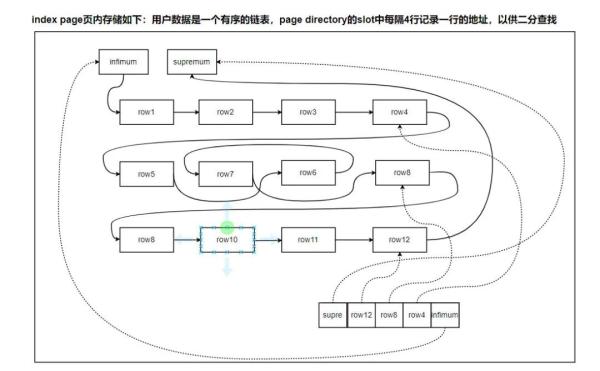
頁內的業務數據是一個邏輯上按順序排列的單向鏈表。頁內有兩條虛擬行,會別代表整個頁中索引值最小的行和最大的行,即鏈表中第一行和最后一行,用來界定鏈表的范圍。
另外,對于索引段,一頁大概有16250B用來存儲用戶數據。一行包含一個4字節的int類型key,一個指向葉子節點占6字節的頁號,大概6字節的row header,總共大概16字節。那么一頁粗略的計算可以存儲16250/16約為1000條。為了優化查詢,每隔4-8行數據把這幾行數據的第一行地址在存放在一個稱為slot的2字節空間中,這些slot一起組成一個稱為Page directory的數組中。
如圖:數組最后一個slot存儲第一行infimum,倒數據第二個slot存儲row4,正序第一個slot存儲最后一行數據supremum。這樣page directory數組就是一個有序的數組,可以通過一次二分查找算法快速定位數據塊,然后在這個塊中遍歷找到最終符合要求的數據。
注意:由于用戶行與頁尾之間有空閑空間,而slot個數受頁內行數影響而不固定,即page dirctory數組長度不固定,因此通過逆序向前追加的方式分配slot。
整體結構
以上是表空間中不同對象各自的結構和數據信息,下面從整體的角度看一看各個組件是如何關聯的。
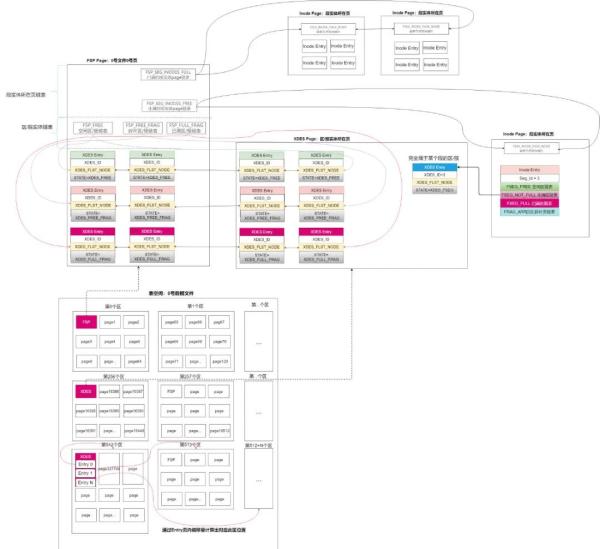
微觀上,表空間文件從物理上分隔為大小相等且連續的頁。
宏觀上,表空間文件從物理上分隔為大水相乘且連續的區/簇。
0號文件的0號頁稱為FSP頁,即首頁,可以假定為表空間的封面頁。它存儲了整個表空間其它組件的鏈表指針,是整個表空間的入口頁。
從邏輯上,FSP頁通過兩條線指向不同組件。(1):通過FSP_SEG_INODES_FULL(已寫滿的段頁鏈表)和FSP_SEG_INODES_FREE(未寫滿的段頁鏈表),指向段信息。段實體又通過FSEG_FREE(空閑的區/簇鏈表)、FSEG_FULL(寫滿的區/簇)、FSEG_NOT_FULL(未寫滿的區/簇),指向屬于本段的區/簇。(2):通過FSP_FREE(空閑的區/簇鏈表)、FSP_FREE_FRAG(未寫滿的碎片區/簇)、FSP_FULL_FRAG(已寫滿的碎片區/簇),指向不屬于任何段的區/簇。
每256個區/簇的第一個區/簇的第一頁存儲這256個區/簇的管理信息。0號頁因為特殊叫做FSP頁,其它叫做XDES頁。通過這個頁號以及存儲在其中的Entry位置偏移量,可以很容易的計算出這256個區在磁盤上的位置。因此即使XDES Entry中沒有記錄區/簇的編號或地址,也可以知道每個Entry管理的是哪個區/簇。
當index頁中插入一條數據時,如果本頁已滿,則需要向此頁所在的區/簇申請空間,如果此區/簇也滿了,則向所在的段申請,如果段也滿了,則會向表空間申請,表空間會通過操作系統向磁盤申請3個區/簇,并加入到FSP中的FSP_FREE鏈表中。然后再一級級分配,存儲到其對應的鏈表中。
行/Row
以上介紹的所有對象都是為了給業務數據分配一塊用來存儲的物理空間,到此終于可以在指定的頁中記錄業務數據。而innodb是基于行進行存儲,下面簡單的看一看行Compact格式的存儲結構。
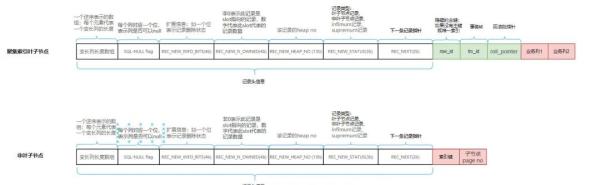
每條記錄都包含一系列頭信息,描述當前記錄的存儲狀態如圖。但是除了頭信息外,則根據記錄所在節點不同存儲的數據也有所不同。
聚集索葉子節點,記錄存儲的是表中的業務行,除行數據本身外,還包含了事務id,回滾段指針,以及在沒有指定主鍵和唯一索引時還包含一個隱藏的row_id。
非葉子節點針對的是B+樹搜索,因此記錄的是子節點的最小記錄值以及子節點的頁號。
B+樹節點與page的關系
Innodb page只是物理上的存儲空間,相當于一本書的一頁,僅僅是數據的載體。B+樹節點是數據的邏輯結構,理論上它們沒有必然的關系。可以在一個page頁內存儲一棵完整的B+樹,也可以多個page頁一起存儲一棵完整的B+樹,甚至可以把page頁與B+樹中的節點一一對應。
實際上Innodb中為了實現簡單,B+樹節點與page頁是一一對應,以下是其簡單的擴展過程。
假設有一個聚集索引B+樹開始的樣子如下:
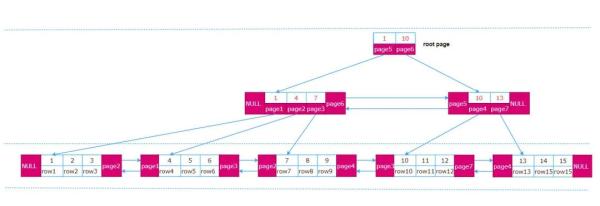
向B+樹中插入16、17、18三行數據如下(綠色部分):
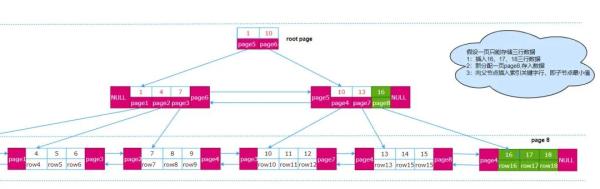
向B+樹繼續插入19一行數據,原先的空間已滿擴展如下(藍色部分):

如果聚集索引使用的是自增的主鍵,那么數據是以追加的方式存儲在每一頁中,如果頁已經存滿,只需要重新分配一頁空間繼續追加即可。
如果聚集索引使用的是無順序的列如uuid,由于B+是一個邏輯上有序的集合,那么向B+樹中插入數據就很可能插入到原先已經滿了的page頁中,就會導致原來的頁進行分裂。會像向數組中插入數據一樣先進行移動,為新數據騰出空間。因此建議使用有序的列做聚集索引。
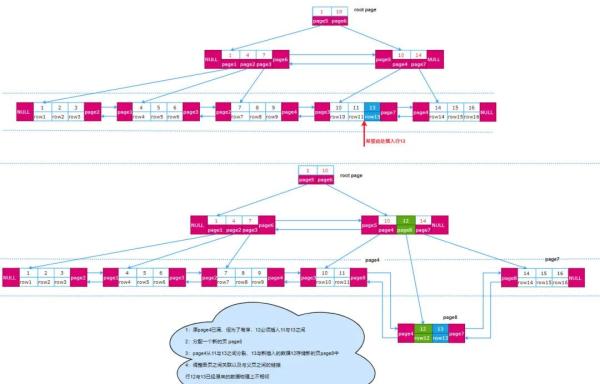
如何一步步存儲一條數據
經歷了千辛萬苦,終于可以從頭到尾插入一條數據,一探innodb如何一步步把數據存儲到文件中。妹妹們估計已經聽的如癡如醉,想想都開心,我可真是個小機靈鬼。
伸伸懶腰,甜甜的望向妹妹們。
哎,人呢?我是穿越到平等空間了嗎?
算了,善始善終,我就講給自己聽,迷倒不了別人,我還不信迷倒不了自己。
在數據庫world中創建表user
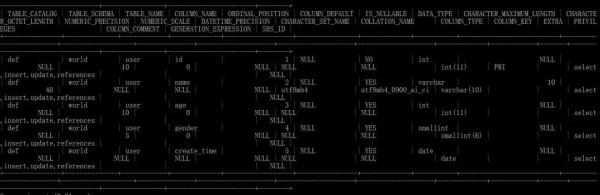
CREATE TABLE user ( id int(11) NOT NULL AUTO_INCREMENT, name varchar(10) DEFAULT NULL, age int(11) DEFAULT NULL, gender smallint(6) DEFAULT NULL, create_time date DEFAULT NULL, PRIMARY KEY (id) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
innodb向系統表空間的information_schema庫的tables和columns中存入表結構信息

創建表空間 同時創建獨立表空間world/user以及對應的數據文件world/user.ibd,并更新到information_schema.innodb_tablespaces中

同步更新表空間所對應的文件信息到information_schema.files中
規定表空間0號文件即world/user.ibd文件的0號頁為表空間的封面頁。
創建聚集索引 如果指定的主鍵或唯一索引,則使用指定的列創建聚集索引,否則使用隱藏列row_id創建聚集索引,并存儲到information_schema.innodb_indexes中

為索引創建兩個段:索引段(非葉子節點)和數據段(葉子節點),并把段信息存儲到表空間封面頁的段鏈表中。
為索引創建第一頁即Root Page,把段信息記錄在Root Page的段鏈表中,從而管理本B+樹的段信息。同時把Root PageNo記錄到information_schema.innodb_indexes中,如上圖。從頁使邏輯表與物理存儲關聯起來,這個Root Page相當于索引的封面。
插入數據 向表中插入一條數據如下
insert into world.user(name,age,gender,create_time) values('木葉瀟瀟',18,1,now())從sql中提取數據庫名和表名,從information_schema.innodb_tables中查出表id

根據表id,從information_schema.innodb_indexes中查出表對應的聚集索引的Root Page No 為4。

通過Root Page No 4計算出Root Page的物理地址。根據Root Page中指定的段信息,向Root Page中插入索引數據,向數據段對應的頁中插入數據行,并關聯兩種類型的頁。
如果一頁空間不足,會計算出當前頁所在的區/簇并向其申請空間,區/簇則會根據 XDES Entry中的bitmap查詢空閑的頁并進行分配。如果區/簇也沒有空閑空間,則會一級一級向上面的段、表空間、操作系統申請所需空間。
申請到的表空間會存儲在各自對應的鏈表中(如:表空間申請到的空間會存儲在對應的FSP_FREE鏈表中)。
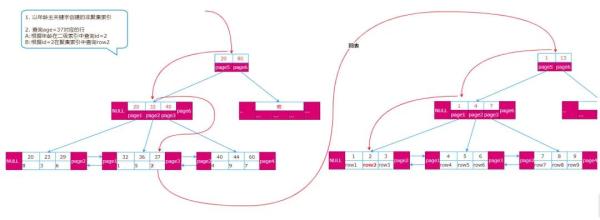
在頁分配或擴展時,為了保證通過innodb_indexes中的Root Page No能找到它,Root Page物理空間與B+樹對應的Root 節點保持不變,即頁號不變,永遠是頁號為4的那塊空間。
當B+對應的物理頁不斷變化時,為了保證樹的平衡,會產生新的Root節點,為了保持Root頁不變,innodb是通過交換的方式,把新的Root節點數據復制交換到原來的Root Page頁,這樣就可以保證Root Page永遠不變,即保證表與物理空間的關聯永遠不會斷開。
總結
表空間是數據庫中的邏輯結構,它解耦了表、索引等與文件的關聯。
段也是一個邏輯結構,它讓具有具體相同邏輯含義和相同存儲結構的數據歸為一組,方便管理。
區是物理存儲結構,對應大磁盤中真實的物理空間。它從文件第一個字節開始按相同大小劃分,并通過XDES Entry在邏輯上把區串聯起來。通過XDES Entry所在頁以及頁內偏量可以計算出XDES Entry與它管理的物理空間區的關系。
頁是物理存儲IO操作的最小單元。它也是從文件第一個字節開始按相同大小劃分。表是通過索引的方式組織數據,聚集索引元數據中存儲了此表對就的Root page No。頁是有編號的,通過編號就可與物理空間建立關聯。
段、區都是為了管理空間的存儲狀態,為頁分配空間服務,真正的查詢只需要通過Page No和B+樹中各級節點的關聯關系就可以操作整個表物理空間上的數據。
行是最終存儲業務數據的物理單元。默認一頁16K,可以存儲大概1000多行索引數據(非葉子節點),或者20行甚至更多的業務數據(葉子節點)。頁之間通過B+樹的“二分找查(假設為多分)”算法快速定位數據,頁內則通過 Page Directory,把多行分一組,一組對應Page Directory有序數組中的一個slot,這樣可以在頁內進行一次“二分查找”優化。
為了記錄行本身的狀態,一條記錄innodb會增加額外的記錄頭信息。如果是葉子節點,還會增加:row_id(隱藏的主鍵)、trx_id(事務id)、回滾指針等附加字段。
以上就是InnoDB中怎么插入數據,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





