溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“數據庫中group by的用法是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
前段時間面試的時候碰到這樣一個面試題,因為很久沒接觸sql竟然沒寫出來。
如圖有這樣一張成績表:
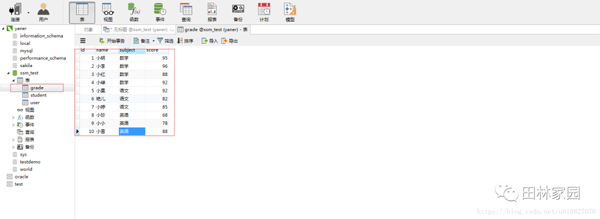
首先要理解group by 含義:“Group By”從字面意義上理解就是根據“By”指定的規則對數據進行分組,所謂的分組就是將一個“數據集”劃分成若干個“小區域”,然后針對若干個“小區域”進行數據處理。
先來看這樣一條sql語句:select subject,max(score) from grade GROUP BY subject
結果是:
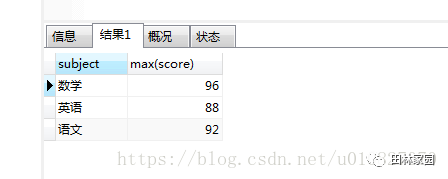
這樣正確的得出了每一科的最高分以及科目的名稱。那是不是再在后面加個name就可以得出對應的學生的名字呢?我們可以試試:select subject,max(score),name from grade GROUP BY subject
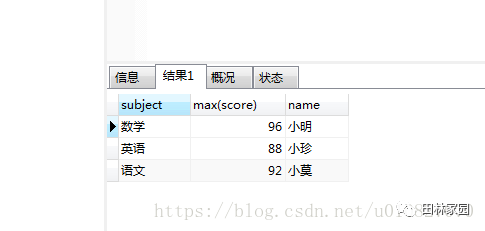
一看有結果以為成功了,但是對比數據后發現是錯的,學生姓名和分數沒對應上。如果你認為是成功的是因為對group by理解的不夠,我也不知道這樣查詢為什么能出來結果,我使用的mysql數據庫,如果是oracle的話就會報錯。
注意:因為在select指定的字段要么就要包含在Group By語句的后面,作為分組的依據;要么就要被包含在聚合函數中。
所以這樣是錯誤的。
group by語句中select指定的字段必須是“分組依據字段”,其他字段若想出現在select中則必須包含在聚合函數中,常見的聚合函數如下表:
| 函數 | 作用 | 支持性 |
|---|---|---|
| sum(列名) | 求和 | |
| max(列名) | 最大值 | |
| min(列名) | 最小值 | |
| avg(列名) | 平均值 | |
| first(列名) | 第一條記錄 | 僅Access支持 |
| last(列名) | 最后一條記錄 | 僅Access支持 |
| count(列名) | 統計記錄數 | 注意和count(*)的區別 |
我們還是分析要求,通過要求來寫sql語句。
這里提供幾種方法:
我們已經通過group by分組來獲得每一科的最高分以及科目名稱,把它作為第一句sql,,然后再查詢一下score表,找到學科和分數都相同的記錄:(子sql語句作為主sql語句的一部分)
#a.* 表示a表中所有的字段,b.*表示b表中所有的字段
select b.* from (select subject,max(score) m from grade GROUP BY subject) t,grade b where t.subject=b.subject and t.m=b.score
結果如下:
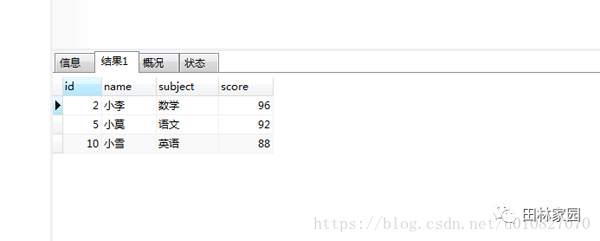
對比發現數據是對的。
拓展問法:用一句SQL查出所有課程成績最高和最低的學生及其分數。
首先,通過分組獲得每個學科的最高分以及最低分:
select subject,max(score),MIN(score) from grade GROUP BY subject
結果如下:
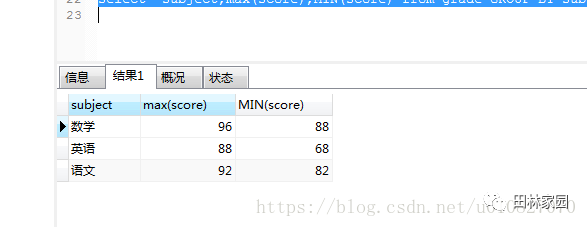
那我們如何把最高分對應的學生名字和最低分對應的名字放入呢,而且要求的數據展示是最高分一行,最低分一行。所以這樣行不通。
通過上面的第一個問題得出的思路:
select b.* from (select subject,max(score) m from grade GROUP BY subject) t,grade b where t.subject=b.subject and t.m=b.score
這樣既然能得到每個學科的最高分,學生名字,學科名,那同樣把max(score)改成min(score)不就可以獲得最低分,學生名字,學科名字了嗎?現在重點是如何把兩條sql語句查詢出來的結果整合到一起。
select b.* from (select subject,min(score) m from grade GROUP BY subject) t,grade b where t.subject=b.subject and t.m=b.score
此時想到了sql的關鍵字 : UNION的定義
UNION 操作符用于合并兩個或多個 SELECT 語句的結果集。
請注意,UNION 內部的 SELECT 語句必須擁有相同數量的列。列也必須擁有相似的數據類型。同時,每條 SELECT 語句中的列的順序必須相同。注釋:默認地,UNION 操作符選取不同的值。如果允許重復的值,請使用 UNION ALL。另外,UNION 結果集中的列名總是等于 UNION 中第一個 SELECT 語句中的列名。
所以得出的sql是這樣的:
select b.* from (select subject,max(score) m from grade GROUP BY subject) t,grade b where t.subject=b.subject and t.m=b.score UNION
select b.* from (select subject,min(score) m from grade GROUP BY subject) t,grade b where t.subject=b.subject and t.m=b.score
得出的結果是:
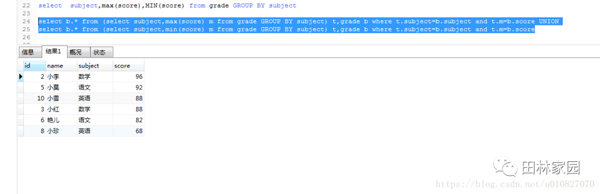
這樣就ok了。如果還想添加一些東西。例如添加一列說明這個分數是最低分或者最高分。
select b.*,"最高分" from (select subject,max(score) m from grade GROUP BY subject) t,grade b where t.subject=b.subject and t.m=b.score
UNION
select b.*,"最低分" from (select subject,min(score) m from grade GROUP BY subject) t,grade b where t.subject=b.subject and t.m=b.score
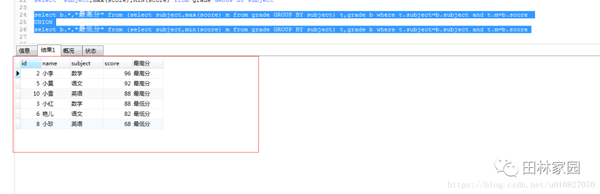
“數據庫中group by的用法是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





