溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Serverless架構下怎么用Python搞定圖像分類和預測”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Serverless架構下怎么用Python搞定圖像分類和預測”吧!
本文將會通過一個有趣的 Python 庫,快速將圖像分類的功能搭建在云函數上,并且和 API 網關結合,對外提供 API 功能,實現一個 Serverless 架構的“圖像分類 API”。
首先和大家介紹一下需要的依賴庫:ImageAI。通過該依賴的官方文檔我們可以看到這樣的描述:
ImageAI 是一個 python 庫,旨在使開發人員能夠使用簡單的幾行代碼構建具有包含深度學習和計算機視覺功能的應用程序和系統。
ImageAI 本著簡潔的原則,支持最先進的機器學習算法,用于圖像預測、自定義圖像預測、物體檢測、視頻檢測、視頻對象跟蹤和圖像預測訓練。ImageAI 目前支持使用在 ImageNet-1000 數據集上訓練的 4 種不同機器學習算法進行圖像預測和訓練。ImageAI 還支持使用在 COCO 數據集上訓練的 RetinaNet 進行對象檢測、視頻檢測和對象跟蹤。最終,ImageAI 將為計算機視覺提供更廣泛和更專業化的支持,包括但不限于特殊環境和特殊領域的圖像識別。
也就是說這個依賴庫,可以幫助我們完成基本的圖像識別和視頻的目標提取,雖然他給了一些數據集和模型,但是我們也可以根據自身需要對其進行額外的訓練,進行定制化拓展。通過官方給的代碼,我們可以看到一個簡單的 Demo:
# -*- coding: utf-8 -*- from imageai.Prediction import ImagePrediction # 模型加載 prediction = ImagePrediction() prediction.setModelTypeAsResNet() prediction.setModelPath("resnet50_weights_tf_dim_ordering_tf_kernels.h6") prediction.loadModel() predictions, probabilities = prediction.predictImage("./picture.jpg", result_count=5 ) for eachPrediction, eachProbability in zip(predictions, probabilities): print(str(eachPrediction) + " : " + str(eachProbability))(左右滑動查看)
當我們指定的 picture.jpg 圖片為:

我們在執行之后的結果是:
laptop : 71.43893241882324 notebook : 16.265612840652466 modem : 4.899394512176514 hard_disc : 4.007557779550552 mouse : 1.2981942854821682
如果在使用過程中覺得模型
resnet50_weights_tf_dim_ordering_tf_kernels.h6 過大,耗時過長,可以按需求選擇模型:
SqueezeNet(文件大小:4.82 MB,預測時間最短,精準度適中)
ResNet50 by Microsoft Research (文件大小:98 MB,預測時間較快,精準度高)
InceptionV3 by Google Brain team (文件大小:91.6 MB,預測時間慢,精度更高)
DenseNet121 by Facebook AI Research (文件大小:31.6 MB,預測時間較慢,精度最高)
模型下載地址可參考 Github 地址:https://github.com/OlafenwaMoses/ImageAI/releases/tag/1.0
或者參考 ImageAI 官方文檔:https://imageai-cn.readthedocs.io/zh_CN/latest/ImageAI_Image_Prediction.html
項目 Serverless 化
將項目按照函數計算的需求,編寫好入口方法,以及做好項目初始化,同時在當前項目下創建文件夾 model,并將模型文件拷貝到該文件夾:

項目整體流程:
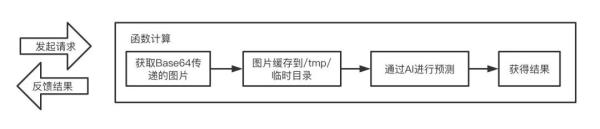
實現代碼:
# -*- coding: utf-8 -*- from imageai.Prediction import ImagePrediction import json import uuid import base64 import random # Response class Response: def __init__(self, start_response, response, errorCode=None): self.start = start_response responseBody = { 'Error': {"Code": errorCode, "Message": response}, } if errorCode else { 'Response': response } # 默認增加uuid,便于后期定位 responseBody['ResponseId'] = str(uuid.uuid1()) print("Response: ", json.dumps(responseBody)) self.response = json.dumps(responseBody) def __iter__(self): status = '200' response_headers = [('Content-type', 'application/json; charset=UTF-8')] self.start(status, response_headers) yield self.response.encode("utf-8") # 隨機字符串 randomStr = lambda num=5: "".join(random.sample('abcdefghijklmnopqrstuvwxyz', num)) # 模型加載 print("Init model") prediction = ImagePrediction() prediction.setModelTypeAsResNet() print("Load model") prediction.setModelPath("/mnt/auto/model/resnet50_weights_tf_dim_ordering_tf_kernels.h6") prediction.loadModel() print("Load complete") def handler(environ, start_response): try: request_body_size = int(environ.get('CONTENT_LENGTH', 0)) except (ValueError): request_body_size = 0 requestBody = json.loads(environ['wsgi.input'].read(request_body_size).decode("utf-8")) # 圖片獲取 print("Get pucture") imageName = randomStr(10) imageData = base64.b64decode(requestBody["image"]) imagePath = "/tmp/" + imageName with open(imagePath, 'wb') as f: f.write(imageData) # 內容預測 print("Predicting ... ") result = {} predictions, probabilities = prediction.predictImage(imagePath, result_count=5) print(zip(predictions, probabilities)) for eachPrediction, eachProbability in zip(predictions, probabilities): result[str(eachPrediction)] = str(eachProbability) return Response(start_response, result)所需要的依賴:
tensorflow==1.13.1 numpy==1.19.4 scipy==1.5.4 opencv-python==4.4.0.46 pillow==8.0.1 matplotlib==3.3.3 h6py==3.1.0 keras==2.4.3 imageai==2.1.5
編寫部署所需要的配置文件:
ServerlessBookImageAIDemo: Component: fc Provider: alibaba Access: release Properties: Region: cn-beijing Service: Name: ServerlessBook Description: Serverless圖書案例 Log: Auto Nas: Auto Function: Name: serverless_imageAI Description: 圖片目標檢測 CodeUri: Src: ./src Excludes: - src/.fun - src/model Handler: index.handler Environment: - Key: PYTHONUSERBASE Value: /mnt/auto/.fun/python MemorySize: 3072 Runtime: python3 Timeout: 60 Triggers: - Name: ImageAI Type: HTTP Parameters: AuthType: ANONYMOUS Methods: - GET - POST - PUT Domains: - Domain: Auto
在代碼與配置中,可以看到有目錄:/mnt/auto/ 的存在,該部分實際上是 nas 掛載之后的地址,只需提前寫入到代碼中即可,下一個環節會進行 nas 的創建以及掛載點配置的具體操作。
項目部署與測試
在完成上述步驟之后,可以通過:
s deploy
進行項目部署,部署完成可以看到結果:
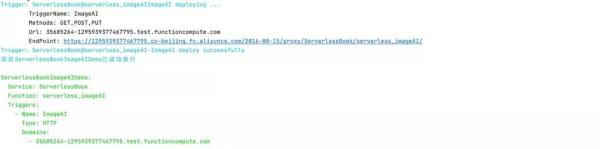
完成部署之后,可以通過:
s install docker
進行依賴的安裝:

依賴安裝完成可以看到在目錄下生成了 .fun 的目錄,該目錄就是通過 docker 打包出來的依賴文件,這些依賴正是我們在 requirements.txt 文件中聲明的依賴內容。
完成之后,我們通過:
s nas sync ./src/.fun
將依賴目錄打包上傳到 nas,成功之后再將 model 目錄打包上傳:
s nas sync ./src/model
完成之后可以通過:
s nas ls --all
查看目錄詳情:

完成之后,我們可以編寫腳本進行測試,同樣適用剛才的測試圖片,通過代碼:
import json import urllib.request import base64 import time with open("picture.jpg", 'rb') as f: data = base64.b64encode(f.read()).decode() url = 'http://35685264-1295939377467795.test.functioncompute.com/' timeStart = time.time() print(urllib.request.urlopen(urllib.request.Request( url=url, data=json.dumps({'image': data}).encode("utf-8") )).read().decode("utf-8")) print("Time: ", time.time() - timeStart)可以看到結果:
{"Response": {"laptop": "71.43893837928772", "notebook": "16.265614330768585", "modem": "4.899385944008827", "hard_disc": "4.007565602660179", "mouse": "1.2981869280338287"}, "ResponseId": "1d74ae7e-298a-11eb-8374-024215000701"} Time: 29.16020894050598可以看到,函數計算順利地返回了預期結果,但是整體耗時卻超乎想象,有近 30s,此時我們再次執行一下測試腳本:
{"Response": {"laptop": "71.43893837928772", "notebook": "16.265614330768585", "modem": "4.899385944008827", "hard_disc": "4.007565602660179", "mouse": "1.2981869280338287"}, "ResponseId": "4b8be48a-298a-11eb-ba97-024215000501"} Time: 1.1511380672454834可以看到,再次執行的時間僅有 1.15 秒,比上次整整提升了 28 秒之多。
項目優化
在上一輪的測試中可以看到,項目首次啟動和二次啟動的耗時差距,其實這個時間差,主要是函數在加載模型的時候浪費了極長的時間。
即使在本地,我們也可以簡單測試:
# -*- coding: utf-8 -*- import time timeStart = time.time() # 模型加載 from imageai.Prediction import ImagePrediction prediction = ImagePrediction() prediction.setModelTypeAsResNet() prediction.setModelPath("resnet50_weights_tf_dim_ordering_tf_kernels.h6") prediction.loadModel() print("Load Time: ", time.time() - timeStart) timeStart = time.time() predictions, probabilities = prediction.predictImage("./picture.jpg", result_count=5) for eachPrediction, eachProbability in zip(predictions, probabilities): print(str(eachPrediction) + " : " + str(eachProbability)) print("Predict Time: ", time.time() - timeStart)執行結果:
Load Time: 5.549695014953613 laptop : 71.43893241882324 notebook : 16.265612840652466 modem : 4.899394512176514 hard_disc : 4.007557779550552 mouse : 1.2981942854821682 Predict Time: 0.8137111663818359
可以看到,在加載 imageAI 模塊以及加載模型文件的過程中,一共耗時 5.5 秒,在預測部分僅有不到 1 秒鐘的時間。而在函數計算中,機器性能本身就沒有我本地的性能高,此時為了避免每次裝載模型導致的響應時間過長,在部署的代碼中,可以看到模型裝載過程實際上是被放在了入口方法之外。這樣做的一個好處是,項目每次執行的時候,不一定會有冷啟動,也就是說在某些復用的前提下是可以復用一些對象的,即無需每次都重新加載模型、導入依賴等。
所以在實際項目中,為了避免頻繁請求,實例重復裝載、創建某些資源,我們可以將部分資源放在初始化的時候進行。這樣可以大幅度提高項目的整體性能,同時配合廠商所提供的預留能力,可以基本上杜絕函數冷啟動帶來的負面影響。
感謝各位的閱讀,以上就是“Serverless架構下怎么用Python搞定圖像分類和預測”的內容了,經過本文的學習后,相信大家對Serverless架構下怎么用Python搞定圖像分類和預測這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





