溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關如何進行LinkedIn架構演化歷史的分析,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
LinkedIn 創建于 2003 年,主要目標是連接你的個人人脈以得到更好的的工作機會。上線***周只有 2700 個會員,之后幾年,LinkedIn 的產品、會員、服務器負載都增長非常快。
今天,LinkedIn 全球用戶已經超過 3.5 億。我們每天每秒有上萬個頁面被訪問,移動端流量已占到 50% 以上。所有這些接口請求都從后臺獲取,達到每秒上***。
那么,我們是怎么做到的呢?
早些年 – Leo
LinedIn 開始跟很多網站一樣,只有一臺應用服務做了全部工作。這個應用我們給它取名叫“Leo”。它包含了所有的網站頁面(JAVA Servlets),還包含了業務邏輯,同時連接了一個輕量的 LinkedIn 數據庫。
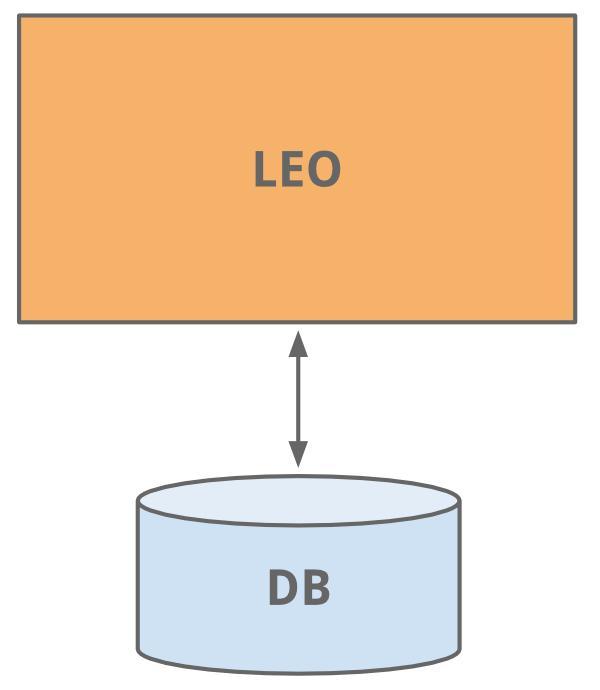
哈!早年網站的形態-簡單實用
會員圖表
***件要做的是管理會員與會員間的社交網絡。我們需要一個系統來圖形化遍歷用戶之間連接的數據,同時又駐留內存以達到有效和高性能。從這個不同的需 求來看,很明顯我們需要可以獨立可擴展的 Leo。一個獨立的會員圖示化系統,叫“云”的服務誕生了 – LinkedIn 的***個服務。為了讓圖表服務獨立于 Leo,我們使用了 Java RPC 用來通訊。
也大概在這期間我們也有搜索服務的需求了,同時會員圖表服務也在給搜索引擎-Lucene 提供數據。
復制只讀數據庫
當站點繼續增長,Leo 也在增長,增加了角色和職責,同時自然也增加了復雜度。負載均衡的多實例 Leo 運轉起來了。但新增的負載也影響了 LinkedIn 的其它關鍵系統,如會員信息數據庫。
一個通常的解決方案是做垂直擴展 – 即增加更多的 CPU 和內存!雖然換取了時間,但我們以后還要擴展。會員信息數據庫受理了讀和寫請求,為了擴展,一個復制的從數據庫出現了,這個復制從庫, 是會員主庫的一個拷貝,用早期的 databus 來保證數據的同步(現在開源了)。從庫接管了所有的讀請求,同時添加了保證從庫與主庫一致的邏輯。
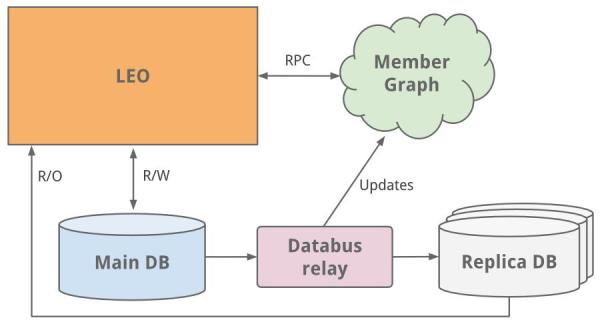
當主-從架構工作了一段時間后,我們轉向了數據庫分區
當網站開始看起來越來越多流量,我們的應用服務 Leo 在生產環境經常宕機,排查和恢復都很困難,發布新代碼也很困難,高可用性對 LinkedIn 至關重要,很明顯我們要“干掉”Leo,然后把它拆分成多個小功能塊和無狀態服務。
面向服務的架構 – SOA
工程師從分解負擔 API 接口和業務邏輯的微服務開始,如搜索、個人信息、通訊及群組平臺,然后是展示層分解,如招募功能和公共介紹頁。新產品和新服務都放在 Leo 之外了,不久,每個功能區的垂直服務棧完成了。
我們構建了從不同域抓取數據模型的前端服務器,用于表現層展示,如生成 HTML(通過 JSPs)。我們還構建了中間層服務提供 API 接口訪問數據模型及提供數據庫一致性訪問的后端數據服務。到 2010 年,我們已經有超過 150 個單獨的服務,今天,我們已經有超過 750 個服務。
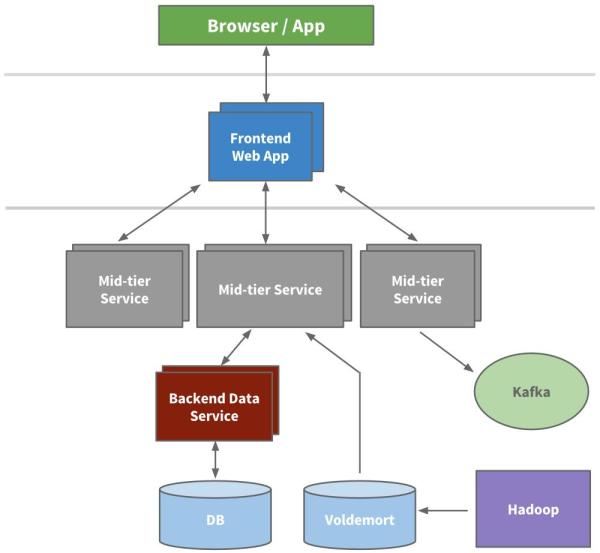
因為無狀態,可以直接堆疊新服務實例及用硬件負載均衡實現擴展。我們給每個服務都畫了警戒紅線,以便知道它的負載,從而制定早期對策和性能監控。
緩存
LinkedIn 可預見的增長,所以還需要進一步擴展。我們知道通過添加更多緩存可以減少集中壓力的訪問。很多應用開始使用如 memcached/couchbase 的中間層緩存,同時在數據層也加了緩存,某些場景開始使用 useVoldemort 提供預結果生成。
又過一了段時間,我們實際上去掉了很多中間層緩存,中間層緩存數據往往來自多個域,但緩存只是開始時對減少負載有用,但更新緩存的復雜度和生成圖表變得更難于把控。保持緩存最接近數據層將降低潛在的不可控影響,同時還允許水平擴展,降低分析的負載。
Kafka
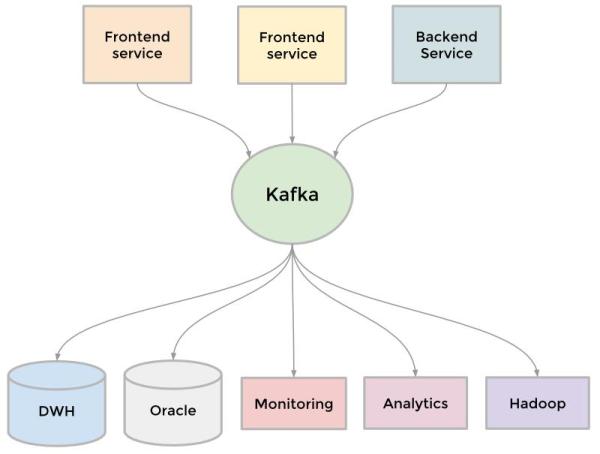
為了收集不斷增長的數據,LinkedIn 開始了很多自定義的數據管道來流化和隊列化數據,例如,我們需要把數據保存到數據倉庫、我們需要發送批量數據到 Hadoop 工作流以分析、我們從每個服務聚合了大量日志、我們跟蹤了很多用戶行為,如頁面點擊、我們需要隊例化 InMail 消息服務、我們要保障當用戶更新個人資料后搜索的數據是***的等等。
當站點還在增長,更多定制化管道服務出現了,因網站需要可擴展,單獨的管道也要可擴展,有些時候很難取舍。解決方案是使用 kafka,我們的分布式發布-訂閱消息平臺。Kafka 成為一個統一的管道服務,根據提交的日志生成摘要,同時一開始就很快速和具有可擴展性。它可以接近于實時的訪問所有數據源,驅動了 Hadoop 任務,允許我們構建實時的分析,廣泛的提升了我們站點監控和告警的能力,同時支持將調用可視化。今天,Kafka 每天處理超過 5 億個事件。
反轉
擴展可從多個維度來衡量,包括組織結構。2011 年晚些時候,LinkedIn 內部開始一個創新,叫”反轉”(Inversion)。我們暫停了新功能開發,允許所有的開發部門集中注意力提升工具和布署、基礎架構及實用性開發。這對 于今天敏捷開發新的可擴展性產品很有幫助。
近幾年 – Rest.li
當我們從 Leao 轉向面向服務的架構后,之前基于 JAVA 的 RPC 接口,在團隊中已經開始分裂了,并且跟表現層綁得太死,這,只會變得更壞。為了搞定這個問題,我們開發了一套新的 API 模型,叫 Rest.li,它是一套以數據為中心的架構,同時保證在整個公司業務的數據一致性且無狀態的 Restful API。
基于 HTTP 的 JSON 數據傳遞,我們新的 API 最終很容易支持到非 java 編寫的客戶端,LinkedIn 今天依然主要用 Java,但同時根據已有的技術分布也利用了 Python、Ruby、Node.js 和C++。脫離了 RPC,同時也讓我們從前端表現層及后端兼容問題解耦,另外, 使用了基于動態發現技術(D2)的 Rest.li,我們每個服務層 API 獲得了自動負載均衡、發現和擴展的能力。
今天,LinkedIn 所有數據中心每天已經有超過 975 個 Rest.li 資源和超過千億級 Rest.li 調用。
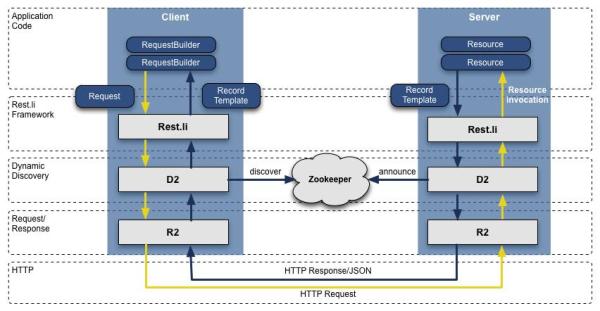
Rest.li R2/D2 技術棧
超級塊
面向服務的架構對于域解耦和服務獨立擴展性很有幫助,但弊端是,大都我們的應用都需要很多不同類型的數據,按序會產品數百個延伸的調用。這就是通常 說的“調用線路圖”,或伴隨著這么多延伸調用的“扇出”(fan-out)。例如,任何個人信息頁都包含了遠不止于相冊、連接、群組、訂閱、關注、博客、 人脈維度、推薦這些。調用圖表可能會很難管理,而且只會把事件搞得越來越不規則。
我們使用了”超級塊”的概念 – 一個只有單一 API 接口的群組化后臺服務。這樣可以允許一個小組去優化一個“塊”,同時保證每個客戶端的調用情況可控。
多數據中心
作為一個會員快速增長的全球化公司,我們需要將數據中心進行擴展,我們努力了幾年來解決這個問題,首先,從兩個數據中心(洛杉磯和芝加哥)提供了公 共個人信息,這表明,我們已經可以提供增強的服務用來數據復制、不同源的遠程調用、單獨數據復制事件、將用戶分配到地理位置更近的數據中心。
我們大多的數據庫運行在 Espresso(一個新的內部多用戶數據倉庫)。Espresso 支持多個數據中心,提供了主-主的支持,及支持復雜的數據復制。
多個數據中心對于高可用性具有不可思議的重要性,你要避免因單點故障不僅只導致某個服務失效,更要擔心整個站點失效。今天,LinkedIn 運行了 3 個主數據中心,同時還有全球化的 PoPs 服務。
我們還做了哪些工作?
當然,我們的擴展故事永遠不止這么簡單。我們的工程師和運維團隊這些年做了不計其數的工作,主要包括這些大的初創性的:
這些年大多關鍵系統都有自己的豐富的擴展演化歷史,包括會員圖表服務(Leo 之外的***個服務),搜索(第二個服務),新聞種子,通訊平臺及會員資料后臺。
我們還構建了數據基礎平臺支持很長一段時間的增長,這是 Databus 和 Kafka 的***次實戰,后來用 Samza 做數據流服務,Espresso 和 Voldemort 作存儲解決方案,Pinot 用來分析系統,以及其它自定義解決方案。另外,我們的工具也進步了,如工程師可自動化布署這些基礎架構。
我們還使用 Hadoop 和 Voldemort 數據開發了大量的離線工作流,用以智能分析,如“你可能認識的人”,“相似經歷”,“感覺興趣的校友”及“個人簡歷瀏覽地圖”。
我們重新考慮了前端的方法,加了客戶端模板到混合頁面(個人中心、我的大學頁面),這樣應用可以更加可交互,只要請求 JSON 或部分 JSON 數據。還有,模板頁面通過 CDN 和瀏覽器緩存。我們也開始使用了 BigPipe 和 Play 框架,把我們的模型從線程化的服務器變成非阻塞異步的。
在代碼之外,我們使用了 Apache 的多層代理和用 HAProxy 做負載均衡,數據中心,安全,智能路由,服務端渲染,等等。
最后,我們繼續提升服務器的性能,包含優化硬件,內存和系統的高級優化,利用新的 JRE。
看完上述內容,你們對如何進行LinkedIn架構演化歷史的分析有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





