溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了Java 中怎么實現一個多線程爬蟲,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
維護待采集的 URL
多線程爬蟲程序就不能像單線程那樣,每個線程獨自維護這自己的待采集 URL,如果這樣的話,那么每個線程采集的網頁將是一樣的,你這就不是多線程采集啦,你這是將一個頁面采集的多次。基于這個原因我們就需要將待采集的 URL 統一維護,每個線程從統一 URL 維護處領取采集 URL ,完成采集任務,如果在頁面上發現新的 URL 鏈接則添加到 統一 URL 維護的容器中。下面是幾種適合用作統一 URL 維護的容器:
URL 的去重
URL 的去重也是多線程采集的關鍵一步,因為如果不去重的話,那么我們將采集到大量重復的 URL,這樣并沒有提升我們的采集效率,比如一個分頁的新聞列表,我們在采集第一頁的時候可以得到 2、3、4、5 頁的鏈接,在采集第二頁的時候又會得到 1、3、4、5 頁的鏈接,待采集的 URL 隊列中將存在大量的列表頁鏈接,這樣就會重復采集甚至進入到一個死循環當中,所以就需要 URL 去重。URL 去重的方法就非常多啦,下面是幾種常用的 URL 去重方式:
將 URL 保存到數據庫進行去重,比如 redis、MongoDB
將 URL 放到哈希表中去重,例如 hashset
將 URL 經過 MD5 之后保存到哈希表中去重,相比于上面一種,能夠節約空間
使用 布隆過濾器(Bloom Filter)去重,這種方式能夠節約大量的空間,就是不那么準確。
關于多線程爬蟲的兩個核心知識點我們都知道啦,下面我畫了一個簡單的多線程爬蟲架構圖,如下圖所示:
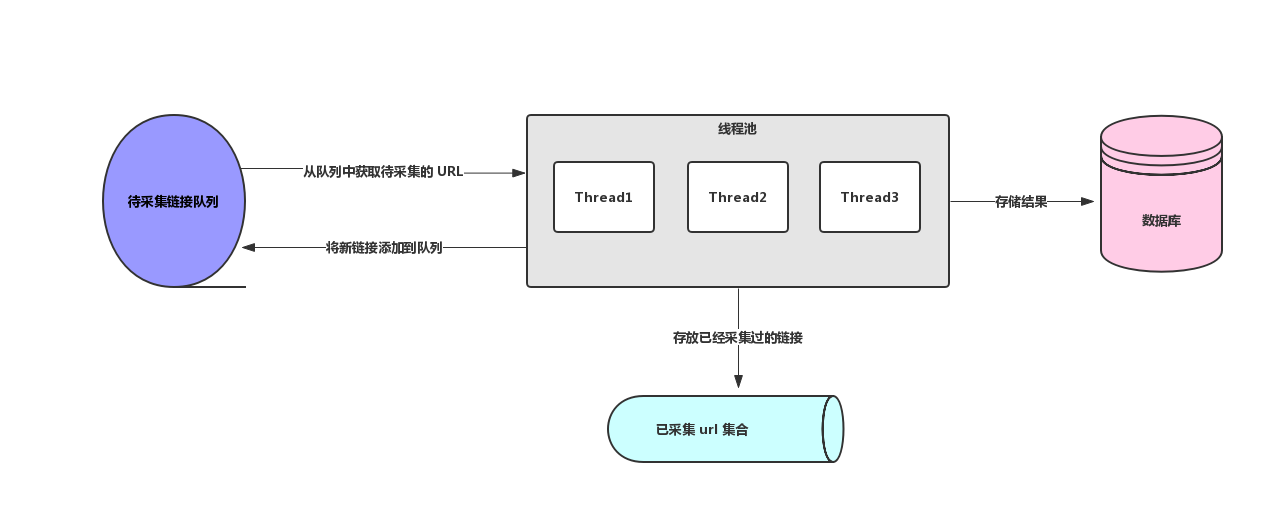
多線程爬蟲架構圖
上面我們主要了解了多線程爬蟲的架構設計,接下來我們不妨來試試 Java 多線程爬蟲,我們以采集虎撲新聞為例來實戰一下 Java 多線程爬蟲,Java 多線程爬蟲中設計到了 待采集 URL 的維護和 URL 去重,由于我們這里只是演示,所以我們就使用 JDK 內置的容器來完成,我們使用 LinkedBlockingQueue 作為待采集 URL 維護容器,HashSet 作為 URL 去重容器。下面是 Java 多線程爬蟲核心代碼,詳細代碼以上傳 GitHub,地址在文末:
/** * 多線程爬蟲 */ public class ThreadCrawler implements Runnable { // 采集的文章數 private final AtomicLong pageCount = new AtomicLong(0); // 列表頁鏈接正則表達式 public static final String URL_LIST = "https://voice.hupu.com/nba"; protected Logger logger = LoggerFactory.getLogger(getClass()); // 待采集的隊列 LinkedBlockingQueue<String> taskQueue; // 采集過的鏈接列表 HashSet<String> visited; // 線程池 CountableThreadPool threadPool; /** * * @param url 起始頁 * @param threadNum 線程數 * @throws InterruptedException */ public ThreadCrawler(String url, int threadNum) throws InterruptedException { this.taskQueue = new LinkedBlockingQueue<>(); this.threadPool = new CountableThreadPool(threadNum); this.visited = new HashSet<>(); // 將起始頁添加到待采集隊列中 this.taskQueue.put(url); } @Override public void run() { logger.info("Spider started!"); while (!Thread.currentThread().isInterrupted()) { // 從隊列中獲取待采集 URL final String request = taskQueue.poll(); // 如果獲取 request 為空,并且當前的線程采已經沒有線程在運行 if (request == null) { if (threadPool.getThreadAlive() == 0) { break; } } else { // 執行采集任務 threadPool.execute(new Runnable() { @Override public void run() { try { processRequest(request); } catch (Exception e) { logger.error("process request " + request + " error", e); } finally { // 采集頁面 +1 pageCount.incrementAndGet(); } } }); } } threadPool.shutdown(); logger.info("Spider closed! {} pages downloaded.", pageCount.get()); } /** * 處理采集請求 * @param url */ protected void processRequest(String url) { // 判斷是否為列表頁 if (url.matches(URL_LIST)) { // 列表頁解析出詳情頁鏈接添加到待采集URL隊列中 processTaskQueue(url); } else { // 解析網頁 processPage(url); } } /** * 處理鏈接采集 * 處理列表頁,將 url 添加到隊列中 * * @param url */ protected void processTaskQueue(String url) { try { Document doc = Jsoup.connect(url).get(); // 詳情頁鏈接 Elements elements = doc.select(" div.news-list > ul > li > div.list-hd > h5 > a"); elements.stream().forEach((element -> { String request = element.attr("href"); // 判斷該鏈接是否存在隊列或者已采集的 set 中,不存在則添加到隊列中 if (!visited.contains(request) && !taskQueue.contains(request)) { try { taskQueue.put(request); } catch (InterruptedException e) { e.printStackTrace(); } } })); // 列表頁鏈接 Elements list_urls = doc.select("div.voice-paging > a"); list_urls.stream().forEach((element -> { String request = element.absUrl("href"); // 判斷是否符合要提取的列表鏈接要求 if (request.matches(URL_LIST)) { // 判斷該鏈接是否存在隊列或者已采集的 set 中,不存在則添加到隊列中 if (!visited.contains(request) && !taskQueue.contains(request)) { try { taskQueue.put(request); } catch (InterruptedException e) { e.printStackTrace(); } } } })); } catch (Exception e) { e.printStackTrace(); } } /** * 解析頁面 * * @param url */ protected void processPage(String url) { try { Document doc = Jsoup.connect(url).get(); String title = doc.select("body > div.hp-wrap > div.voice-main > div.artical-title > h2").first().ownText(); System.out.println(Thread.currentThread().getName() + " 在 " + new Date() + " 采集了虎撲新聞 " + title); // 將采集完的 url 存入到已經采集的 set 中 visited.add(url); } catch (IOException e) { e.printStackTrace(); } } public static void main(String[] args) { try { new ThreadCrawler("https://voice.hupu.com/nba", 5).run(); } catch (InterruptedException e) { e.printStackTrace(); } } }我們用 5 個線程去采集虎撲新聞列表頁看看效果如果?運行該程序,得到如下結果:

多線程采集結果
結果中可以看出,我們啟動了 5 個線程采集了 61 頁頁面,一共耗時 2 秒鐘,可以說效果還是不錯的,我們來跟單線程對比一下,看看差距有多大?我們將線程數設置為 1 ,再次啟動程序,得到如下結果:

單線程運行結果
可以看出單線程采集虎撲 61 條新聞花費了 7 秒鐘,耗時差不多是多線程的 4 倍,你想想這可只是 61 個頁面,頁面更多的話,差距會越來越大,所以多線程爬蟲效率還是非常高的。
上述內容就是Java 中怎么實現一個多線程爬蟲,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





