溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“ElasticSearch平臺架構升級分析”,在日常操作中,相信很多人在ElasticSearch平臺架構升級分析問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”ElasticSearch平臺架構升級分析”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
背景:推石頭的西西弗斯
滴滴 ElasticSearch 團隊從 2016 年開始建設 ElasticSearch 平臺,在 2016 年 6 月份的時候開始對外提供服務,當時選擇了 ElasticSearch 最新的 2.3 版本。
如今三年過去了,ElasticSearch 生態經歷了飛速的增長,Elastic 公司完成了上市,ElasticSearch 在 db-engines 的分數從 88 上漲到 148,排名從 11 名上升到第 7 名。
這期間 ES 發布了 3 個大版本,幾十個中版本,而最近 ElasticSearch 已經發布了 7.x 版本。
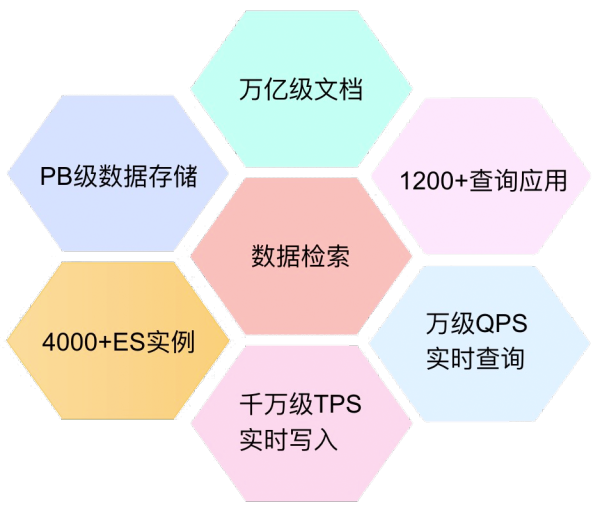
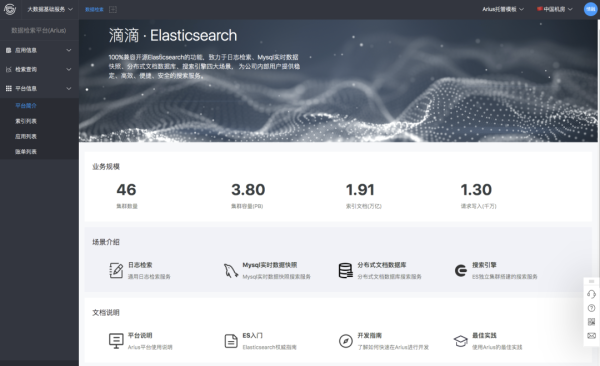
在這三年中滴滴 Elasticsearch 平臺基于 ElasticSearch 推出了日志檢索、MySQL 實時數據庫快照、分布式文檔數據庫、搜索引擎等四大服務,四大業務均快速發展。
目前滴滴 ElasticSearch 平臺服務了集團里面 1200 個應用,其中:訂單、客服、金融、把脈、新政等業務核心實時場景也運行在 Elasticsearch 之上,運維 ES 集群 30+,寫入 TPS 峰值到達 1500W,查詢 QPS 達到 2W。
業務的快速發展既是滴滴 ElasticSearch 團隊工作的肯定,但隨之而來也有巨大的挑戰和壓力,其中版本過低是未來 ElasticSearch 平臺發展最大制約因素,其中主要有以下幾點。
①社區不再維護老版本:ElasticSearch 2.3.3 版本過于陳舊,ES 社區早已不再進行維護,在 2.x 上遇到的問題社區不解決,提交的 issue 也不處理,提交代碼也不被接收。
基于 2.3.3 我們也解決了很多 ES 自身的問題,如:Master 更新元數據超時導致內存泄露、TCP 協議字段溢出等。
由于無法和社區互動,團隊同學的價值也得不到社區的認可,長此以往只會和 ES 生態越來越遠,我們在 ES 技術圈中的聲音也會越來越弱。
②新版本特性很難被使用:最近 3 年是 ES 生態大發展的 3 年,ES 自身在功能、性能上都有非常大提升。
如:默認使用 BM25 評分算法,效果更佳;lucene docvalues 稀疏區域改進,更節約磁盤空間;新增 Frozen indices 能力,可以顯著降低 ES 內存開銷。
很多特性也非常適合 ElasticSearch 平臺的場景,但是版本差距過大一直制約著我們,無法享受技術進步的紅利。
一邊是業務快速發展要求更豐富的功能、更強大的性能、更低的成本、更穩定的服務;一邊離最新的業內技術越來越遠,團隊價值越來越弱,逐漸淪為一支只能做業務的偽引擎團隊,整個團隊的現狀就如同推石頭的西西弗斯。
要么我們迎難而上,克服困難,一口氣把整個集群升級到最新的版本,把石頭推過山頂,再輕裝前行;要么就是繼續獨自勉力支撐,在業務和引擎的雙重壓力下蹣跚而行。
滴滴 ElasticSearch 團隊最終選擇對滴滴 ElasticSearch 平臺進行重構并將維護的所有 ES 集群升級到最新版本。
困難:拔劍四顧心茫然
理想很豐滿,現實很骨感,下決心很容易,然而實際執行很困難:
2.3.3 和 6.6.1 協議不兼容啊,6.6.1 都不支持 TCP 協議了,那些通過 TCP 查的用戶怎么辦,讓他們一個一個改代碼,那要改到什么時候?
2.3.3 和 6.6.1 有些返回的字段都不一樣了,有些查詢語法也不兼容,怎么做到對用戶的透明,還是直接強迫用戶接受改變?
2.3.3 和 6.6.1 lucene 文件格式都不一樣,沒辦法原地直接升級,要再搞個集群全部雙寫一遍。
2.3.3 和 6.6.1 的 Mapping 格式不統一,6.6.1 不支持多 type,現有的那些數據搬遷都沒辦法搬。
滴滴 ElasticSearch 平臺現在不支持索引多版本同時查詢,用戶查詢習慣也千奇百怪,很多帶*查詢你根本控制不了。
用戶那么多,使用差異很大,怎么和用戶進行溝通和宣導,怎么屏蔽用戶影響和管理用于預期?
就算是要搬遷升級,哪里去找那么多機器,現在還要機房裁撤,還要往外拿機器。
幾十個集群,幾千個節點都要部署、搭建、重啟,還要騰挪上千臺機器。慢點搞,這得搞到什么時候,快點搞,萬一出問題怎么辦?
就算是雙寫升級了,怎么知道中間有沒有問題,數據有沒有丟失,用戶的查詢是不是一致的,功能和性能有沒有達到預期,這個怎么驗證?
這么多數據,這么多人在用,這么點資源,業務穩定壓力又大,估計今年一年都搞不完。
…………
在剛開始決定進行跨版本升級之后,我們面臨的問題就撲面而來,其中任何一條不解決,都會極大的阻礙升級的進程。
思考:天生我材必有用
在起步階段有很多問題雜糅在一起,需要理清楚每個問題的重要性、緊急程度、影響層面、相互依賴關系,通過分析歸納我們將其總結為四大問題域:
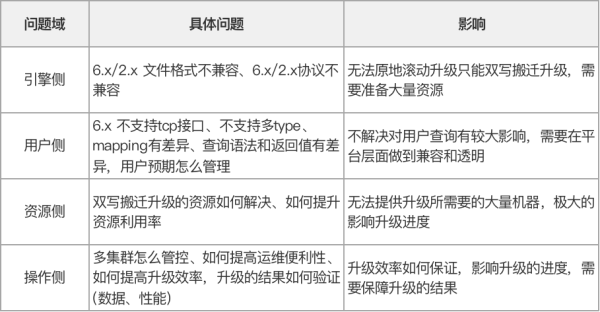
在對問題域進行歸總之后,我們討論了具體的實施方案和步驟,將其歸納以下四個可以實際推進的環節:

首先進行架構升級:解決引擎側 2.x/6.x 的不兼容問題,所有的協議、查詢語法、Mapping 等不兼容處理在平臺側進行處理。
同時我們開發了一個 ES java SDK 用來解決 6.x 不支持 TCP 接口的問題,使用方式和原有的 es java client 完全一致,用戶只要修改 pom 即可。
具體包括:Arius 平臺多版本支持、Gateway 的多版本兼容、用戶 SDK 開發、AMS 數據采集等,具體見后續詳細說明。
其次解決運維問題:解決運維操作過程中多集群搭建、部署、重啟的管控問題,提升操作的便利性,提升升級的操作效率,具體見后續詳細說明。
再次解決資源問題:解決搬遷升級所需要的大量機器資源問題,為大量集群升級做充足準備,同時還要滿足機房裁撤歸還機器的要求。
具體包括:索引存儲周期優化、冷熱數據分離、Mapping 優化、fastIndex 等,具體見后續詳細說明。
最后開始實際推進:在做好前期的所有準備工作之后,開始實際推進升級過程。具體包括:性能壓測、資源評估、批量雙寫、查詢回放,其中還有一些意想不到的采坑和填坑的過程,具體見后續詳細說明。
實戰:白沙戰場碎鐵衣
在理清了整個升級過程中的各個環節的依賴關系、資源消耗、瓶頸點之后,針對架構、資源、實操等三個方面的問題,我們都設計了對應的解決方案,主要如下:

架構
①滴滴 ElasticSearch 平臺 ES 多版本支持的架構改造
首先我們在滴滴 ElasticSearch 平臺上完成了 ES 多版本支持的架構升級,其中重點有:
Arius Gateway 對跨版本查詢差異的兼容,以及多集群下索引跨高低版本集群訪問,使得在升級過程中對用戶查詢結果透明。
Elasticsearch-didi-interanl-client SDK 開發,對用戶屏蔽 ES TCP/HTTP 查詢差異,解決 ES 6.x 版本不支持 TCP 接口的問題,原有 2.x 的用戶只要修改一行 pom 就可以切換到高版本訪問。
滴滴 ElasticSearch 平臺架構梳理以及 Arius admin 多版本支持。
②基于彈性云的 ES 多集群管控方案
目前滴滴 ElasticSearch 團隊運維 30 多個 ES 集群,5000+ 的 ES 節點,集群規模大,場景復雜,運維管控成本比較高。
為此我們設計開發了 ECM(ElasticSearch Cluster Manager)系統用于 ES 集群的部署、重啟、擴容、配置管控等一系列操作。
并且我們 80% 的 ES 節點運行在彈性云上,結合彈性云靈活高效的特點,使得我們在進行搬遷升級的過程更加高效。
③ES 服務元數據體系建設
我們構建了一套 AMS(Arius MetaData Service)服務,用于采集和分析 ES 所有集群、節點、索引的各種數據。
包括:容量信息(集群、節點、模板、索引、租戶)、TPS/QPS 信息(集群、節點、模板、索引、租戶)、運行信息、查詢語句、查詢模板信息、查詢結果和命中率的分析信息等等。
在這些基礎的指標數據基礎上,我們構建了全面的 ES 運行指標系統,可以全面的了解和監控集群、節點、索引、租戶級別的運行信息。
詳盡的數據為后續的 ES 的成本優化提供了基礎,具體見 —— 基于數據驅動的 ES 分級存儲體系,分級存儲體系的構建使得我們構建了一套體系化的ES成本節約的系統。
詳盡的數據為后續升級時做查詢的流量回放對比提供了基礎,具體見——基于 ES 服務元數據的查詢流量回放對比系統,使得我們在升級過程中可以快速驗證升級結果,提升升級效率和穩定性。
同時 AMS 還對數據的可靠性負責,保證產生的數據是及時并且準確的,這樣依賴 AMS 的數據分析服務。
如:分級存儲、容量規劃、回放系統、成本賬單、集群健康檢查、索引健康分等,只用專注自身的邏輯的實現即可。
資源
在解決架構和兼容性問題之后,我們已經有信心將一個集群在線升級到新版本。
然而由于版本跨度太大無法在原集群上直接進行滾動升級,必須要進行數據雙寫的搬遷升級,這樣升級所需要的 buff 資源就成為制約整個升級進度最重要的因素,因此接下來我們把精力放在節省資源提高資源利用率上。
通過內外挖潛和技術改造,不僅支持了版本升級所需要的機器資源(高峰時 3 個集群同時升級),最終還歸還了近 400 臺機器,節約成本 80W+ /月。
①基于數據驅動的 ES 分級存儲體系
基于 AMS 對應索引的大小、數據量、查詢量、查詢條件、查詢時間、返回結果的統計和分析,我們能精確的分析出來每個索引被使用的場景以及被查詢的方式。
如:索引的高頻查詢時間區間、索引被檢索的字段等,在數據分析基礎上我們針對每個索引進行了 Mapping 優化、存儲周期優化、冷熱數據存儲優化。
在不影響用戶使用需求的前提下,累計節省數據 1PB,搬遷冷數據 700TB,不僅保障了升級過程中有充足的 buff 機器,還歸還了近 400 臺物理機,節省成本 70W+ /月。
②ES FastIndex 離線數據導入體系
ES FastIndex 的初衷是為了解決集團標簽系統的離線導入的效率和資源問題,集團標簽系統每天有 30 多 TB 的數據需要在短時間內同步到 ES 中,否則將會影響當天的業務結果,之前方案為了滿足效率采用了大量的機器資源。
采用基于 Hadoop 的 ES fastIndex 離線數據導入系統之后,同樣的數據導入時間由原來的 8 個小時下降到 2 個小時。
機器成本由原來的 40 臺物理機 (ES 27 臺、Kafka 3 臺、Dsink 10 臺) 下降到 30 臺彈性云節點(10 臺物理機),單單在標簽場景就節約成本 7W+ 每月。
③基于資源 Quota 管控的 ES 集群容量規劃方案
提升 ES 集群資源使用率也是滴滴 ElasticSearch 團隊一直面臨和致力于解決的問題。
滴滴 ElasticSearch 團隊維護的 ES 機器總容量將近 5PB,提升 10% 的資源使用率即可節約 500TB 的空間,或者用于歸還機器,或者用于服務新的需求。
當前 ES 集群整體磁盤使用率在 50% 左右,高峰期曾經達到 60%,日志集群磁盤使用率達到 69.5% (2019.05.01),但是這個時候集群資源非常不均,磁盤告警也很嚴重,運維壓力非常大,偶爾還會出現丟數據的問題。
為此我們在原有的 ES 機器容量規劃算法上,加入了資源 Qutoa 管控,并深入引擎,在引擎層面完善 ES 節點的容量規劃和資源均勻,期望將 ES 集群的磁盤整體使用率再提升 10%,日均達到 60%,高峰達到 70%,并且沒有磁盤告警和穩定性問題。
實操
在前期準備工作都完成之后,集群升級就成為一個按部就班的過程,雖然期間也遇到了一些意想不到的情況,踩了一些坑,但整體的過程還是進行的比較順利。
①基于 ES 服務元數據的查詢流量回放對比系統
在前期構建的 AMS(Arius Meta Service)系統上,我們對用戶查詢條件、查詢結果進行記錄和分析。
在雙寫搬遷升級過程中,我們將用戶的查詢條件分別在高低版本的集群上進行回放,將查詢返回的結果、性能參數進行對比分析。
只有對比一致,并且性能無太大差異的情況下,我們才認為升級有效,這樣做到心中有底。
②基于 ECM 的 ES 多集群升級過程
由于需要進行雙寫搬遷升級,在實際的升級過程中,需要密集的進行集群搭建、搬遷、重啟等操作,得益于 ECM 的集群管控能力,彈性云靈活的特性,我們和運維同學密切配合才能在短時間內完成多個集群的升級工作。
③ES 新版本特性以及升級性能分析
ES 6.6.1 提供了很多新的特性,在查詢寫入性能上也有很大的提升,我們升級完成的一些案列也得到了驗證,我們會這些特性和性能提升進行一個詳細的分析并分享給大家。
④ES 版本升級采坑分析
在升級的過程中我們也踩了一些坑,如:高版本 SDK 堆外內存無限制使用導致 OOM 的問題,我們把遇到的問題都詳細記錄下來進行并分享給大家。
收獲:長風破浪會有時
經過近半年的開發和重構,在將國內集群升級到高版本的過程中,我們也在架構、產品、成本、性能、特性、自身能力上都有了很大的提升。
架構更清晰
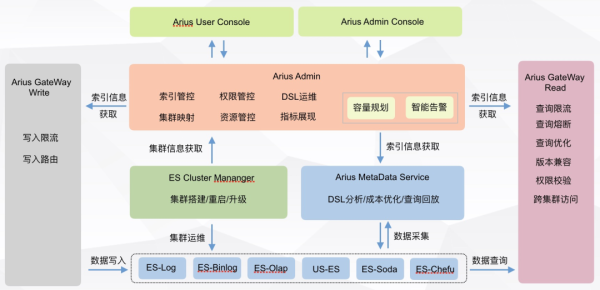
重構之后整個滴滴 ElasticSearch 平臺的服務體系變得更清晰,主要收斂為四大塊應用:
Gateway 負責查詢寫入請求的接入,用戶的限流、權限校驗、版本兼容在此完成。
ECM 負責所有集群的管控,集群搭建、升級、重啟、集群級別監控和運維分析在此完成。
AMS 負責所有集群、節點、索引的運行時信息采集與分析,保障數據質量,并支持其他數據分析應用,分級存儲、索引健康分、集群健康檢查、查詢回放等在此完成。
Arius Admin 負責索引、權限、資源管控等核心能力。依賴 Admin 的核心能力以及 AMS 的數據采集能力,還提供了容量規劃和智能告警兩個設計良好并且可插拔的擴展服務。
四個應用完成功能抽象、依賴解耦和服務化改造,相比之前下線了 arius-watch、arius-dsl、arius-tools、arius-monitor、arius-mark 等五個小應用,重構之后整體開發效率和可運維性得到了很大的提高。
產品更易用
我們基于 ES 6.5.1 版本,完全重構了滴滴 ElasticSearch 用戶控制臺,其中將用戶的一些高頻操作,如:Mapping 設置/變更、數據清理、索引擴容縮容、索引轉讓、成本賬單等開放給用戶,提升用戶的自助操作性。
未來我們還會對滴滴 ElasticSearch 用戶控制臺中的 Kibana 升級到最新版本并進行定制化開發,提供更豐富和更強大的功能給用戶使用。
成本更低廉
之前滴滴 ElasticSearch 平臺有一套基于索引創建規則的容量規劃算法,相比完全沒有規劃,老版容量規劃算法可以將整體的集群資源使用率由 30% 提升到 50% 左右。
但是也存在著一些問題,如:資源分布不均、熱點無法快速發現、動態自適應能力低、規劃算法抽象不夠無法在索引集群生效、運維便利性差。
下圖展現了一個日志集群新老容量規劃的磁盤使用率對比,上線新的容量規劃之后,集群資源會向著兩個方向發展:
正在使用的資源更加聚攏,節點之間資源使用率更平均,整體的資源使用率也更高。
空閑資源完全釋放,基于彈性云部署,可以做到快速從集群摘除,加入后備資源池或者加入其它資源緊張的集群中。
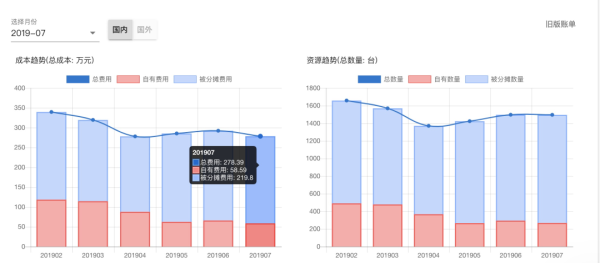
經過一系列的存儲優化和資源使用率改造的完成,在滿足集群升級和業務需要增長的基礎上,國內 ES 的資源成本從 2019 年 2 月的 339w 下降到 2019 年 6 月的 259w,機器數也從 1658 臺下降到 1321 臺。
隨著國內集群升級逐漸全部完成,Ceph 冷存的完善,還會逐步歸還更多的機器,滴滴 ElasticSearch 平臺的使用成本也會一步一步下降,在定價上我們也會考慮進一步的進行降價。
性能更強大
新版本升級之后帶來的性能主要體現在以下兩點:
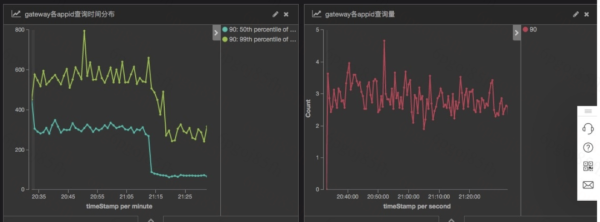
①查詢性能提升
下圖是客服訂單列表查詢語句升級前后的對比,50 分位耗時從 300ms 下降到 50ms。99 分位從 600ms 下降到 300ms。
性能提升的詳細分析見:ES 新版本特性以及升級性能分析。
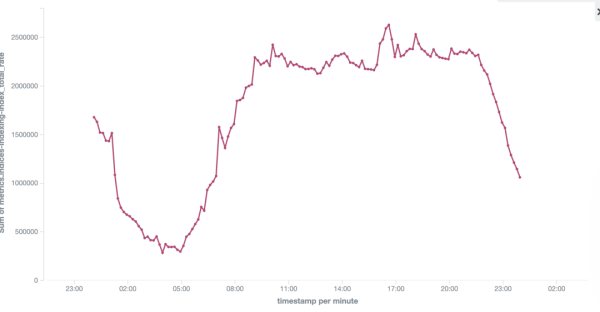
②集群寫入性能提升
升級到高版本只會,ES 6.6.1 集群相對于 ES 2.3.3 集群同等資源消耗下,整個集群的寫入能力提升了 30%。
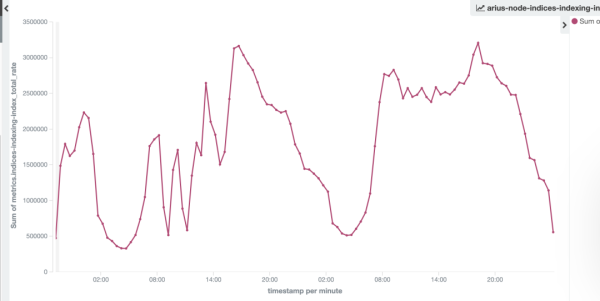
如下圖日志集群的寫入 TPS 前后對比,集群寫入能力從 240w/s 提升到320w/s。
展望:直掛云帆濟滄海
至此,滴滴 ElasticSearch 團隊已經完成了國內全部日志集群、90% 的 vip 集群的升級,整個滴滴 ElasticSearch 平臺的架構也得以重構和升級,從而在 ES 引擎層面也有了更大的發展空間。
未來我們將更加專注于引擎建設,更多的從根本上解決目前遇到的問題。未來我們將在以下幾個方向持續努力:
①更大的集群
在日志場景下嘗試突破 ES 單集群支持的最大節點數限制,提升單個集群能支持的節點數量,從目前的單集群支持的 200 個節點提升到 1000 個節點。
期待在大集群下能降低我們的集群數量提升運維效率,同時更大的集群能更方便和更靈活的提升資源使用率,解決流量突增和資源熱點問題。
②更低的成本
降低 ES 的使用成本,提升資源使用率一直是我們追求的目標,上半年我們在完成集群升級以及服務好業務的同時也完成節約成本 80w 每月,ES 整體成本下降約 25%,下半年爭取再下降成本 10%。
ES 6.6.1 提供的一些新特性如:Frozen 機制、Indexing sort 都將會進一步降低資源消耗。
③更快的迭代
ES 集群內多租戶查詢之間的相互影響一直也是滴滴 ElasticSearch 團隊面臨的一個比較難解決的問題,之前更多的是在平臺層面通過物理資源隔離,查詢審核和限流來解決,資源利用率不高和人為運維成本太大。
后續我們將構建一套 ES 自身的查詢優化器,類似 MySQL 的 Explain,可以在查詢語句級別進行性能分析和查詢優化,并在引擎層面通過索引模板級別的查詢資源隔離、一般 query 和 heavy query 的分離來保障查詢的穩定。
④更緊密的聯系
在 ES 新版的基礎上,我們將和社區保持更緊密的聯系,積極的跟進社區提供的新特性和發展方向,并引入滴滴供大家使用。
也會更積極的參與社區建設,將我們在滴滴內部遇到和解決的問題反饋給社區,貢獻更多的 PR 和產生更多的 ES Contributor。
到此,關于“ElasticSearch平臺架構升級分析”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





