溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹OpenStack是什么意思,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
1. OpenStack是什么
OpenStack既是一個社區,也是一個項目和一個開源軟件,它提供了一個部署云的操作平臺或工具集。其宗旨在于,幫助組織運行為虛擬計算或存儲服務的云,為公有云、私有云,也為大云、小云提供可擴展的、靈活的云計算。
OpenStack旗下包含了一組由社區維護的開源項目,他們分別是OpenStackCompute(Nova),OpenStackObjectStorage(Swift),以及OpenStackImageService(Glance)。
OpenStackCompute[1],為云組織的控制器,它提供一個工具來部署云,包括運行實例、管理網絡以及控制用戶和其他項目對云的訪問(thecloudthroughusersandprojects)。它底層的開源項目名稱是Nova,其提供的軟件能控制IaaS云計算平臺,類似于AmazonEC2和RackspaceCloudServers。實際上它定義的是,與運行在主機操作系統上潛在的虛擬化機制交互的驅動,暴露基于WebAPI的功能。
OpenStackObjectStorage[2],是一個可擴展的對象存儲系統。對象存儲支持多種應用,比如復制和存檔數據,圖像或視頻服務,存儲次級靜態數據,開發數據存儲整合的新應用,存儲容量難以估計的數據,為Web應用創建基于云的彈性存儲。
OpenStackImageService[1],是一個虛擬機鏡像的存儲、查詢和檢索系統,服務包括的RESTfulAPI允許用戶通過HTTP請求查詢VM鏡像元數據,以及檢索實際的鏡像。VM鏡像有四種配置方式:簡單的文件系統,類似OpenStackObjectStorage的對象存儲系統,直接用Amazon'sSimpleStorageSolution(S3)存儲,用帶有ObjectStore的S3間接訪問S3。
三個項目的基本關系如下圖1-1所示:
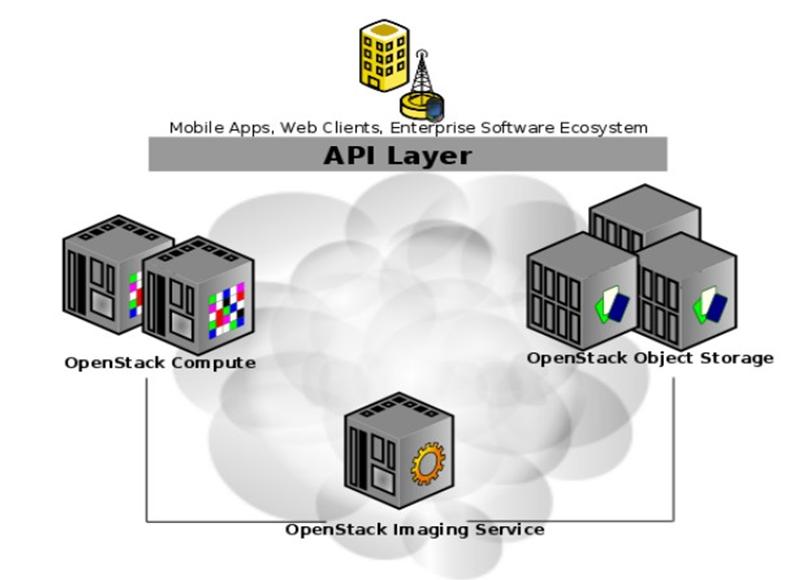
1-1 OpenStack三個組件的關系
2. 云服務提供商的概念架構
OpenStack能幫我們建立自己的IaaS,提供類似AmazonWebService的服務給客戶。為實現這一點,我們需要提供幾個高級特性:
a)允許應用擁有者注冊云服務,查看運用和計費情況;
b)允許Developers/DevOpsfolks創建和存儲他們應用的自定義鏡像;
c)允許他們啟動、監控和終止實例;
d)允許CloudOperator配置和操作基礎架構
這四點都直擊提供IaaS的核心,現在假設你同意了這四個特性,現在就可以將它們放進如下所示的概念架構2-1中。
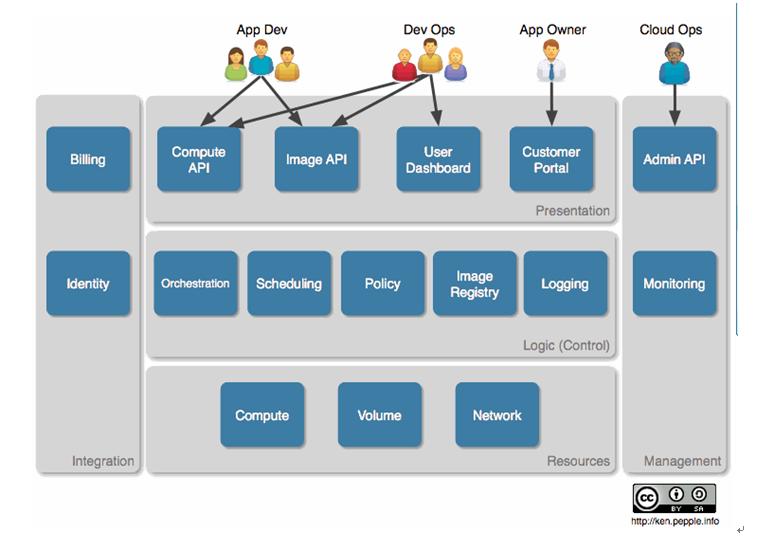
2-1 OpenStack 概念架構
在此模型中,作者假設了需要與云交互的四個用戶集:developers,devops,ownersandoperators,并為每類用戶劃分了他們所需要的功能。該架構采用的是非常普通的分層方法(presentation,logicandresources),它帶有兩個正交區域。
展示層,組件與用戶交互,接受和呈現信息。Webportals為非開發者提供圖形界面,為開發者提供API端點。如果是更復雜的結構,負載均衡,控制代理,安全和名稱服務也都會在這層。
邏輯層為云提供邏輯(intelligence)和控制功能。這層包括部署(復雜任務的工作流),調度(作業到資源的映射),策略(配額等等),鏡像注冊imageregistry(實例鏡像的元數據),日志(事件和計量)。
假設絕大多數服務提供者已經有客戶身份和計費系統。任何云架構都需要整合這些系統。
在任何復雜的環境下,我們都將需要一個management層來操作這個環境。它應該包括一個API訪問云管理特性以及一些監控形式(forms)。很可能,監控功能將以整合的形式加入一個已存在的工具中。當前的架構中已經為我們虛擬的服務提供商加入了monitoring和adminAPI,在更完全的架構中,你將見到一系列的支持功能,比如provisioning和configurationmanagement。
最后,資源層。既然這是一個compute云,我們就需要實際的compute、network和storage資源,以供應給我們的客戶。該層提供這些服務,無論他們是服務器,網絡交換機,NAS(networkattachedstorage)還是其他的一些資源。
3. OpenStack Compute架構
3.1 OpenStack Compute邏輯架構
OpenStack Compute邏輯架構中,組件中的絕大多數可分為兩種自定義編寫的Python守護進程(custom written python daemons)。
a) 接收和協調API調用的WSGI應用(nova-api, glance-api, etc)
b) 執行部署任務的Worker守護進程(nova-compute, nova-network, nova-schedule, etc.)
然而,邏輯架構中有兩個重要的部分,既不是自定義編寫,也不是基于Python,它們是消息隊列和數據庫。二者簡化了復雜任務(通過消息傳遞和信息共享的任務)的異步部署。
邏輯架構圖3-1如下所示:
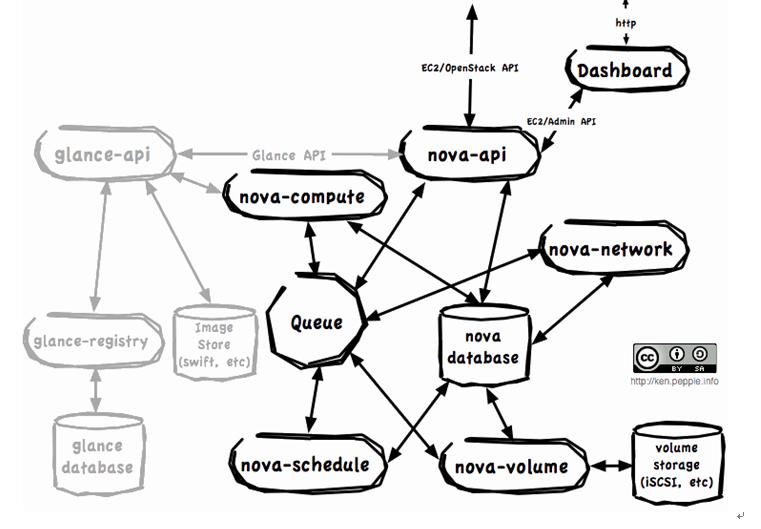
3-1 OpenStack Compute邏輯架構
從圖中,我們可以總結出三點:
a) 終端用戶(DevOps, Developers 和其他的 OpenStack 組件)通過和nova-api對話來與OpenStack Compute交互。
b) OpenStack Compute守護進程之間通過隊列(行為)和數據庫(信息)來交換信息,以執行API請求。
c) OpenStack Glance基本上是獨立的基礎架構,OpenStack Compute通過Glance API來和它交互。
其各個組件的情況如下:
a) nova-api守護進程是OpenStack Compute的中心。它為所有API查詢(OpenStack API 或 EC2 API)提供端點,初始化絕大多數部署活動(比如運行實例),以及實施一些策略(絕大多數的配額檢查)。
b) nova-compute進程主要是一個創建和終止虛擬機實例的Worker守護進程。其過程相當復雜,但是基本原理很簡單:從隊列中接收行為,然后在更新數據庫的狀態時,執行一系列的系統命令執行他們。
c) nova-volume管理映射到計算機實例的卷的創建、附加和取消。這些卷可以來自很多提供商,比如,ISCSI和AoE。
d) Nova-network worker守護進程類似于nova-compute和nova-volume。它從隊列中接收網絡任務,然后執行任務以操控網絡,比如創建bridging interfaces或改變iptables rules。
e) Queue提供中心hub,為守護進程傳遞消息。當前用RabbitMQ實現。但是理論上能是python ampqlib支持的任何AMPQ消息隊列。
f) SQL database存儲云基礎架構中的絕大多數編譯時和運行時狀態。這包括了可用的實例類型,在用的實例,可用的網絡和項目。理論上,OpenStack Compute能支持SQL-Alchemy支持的任何數據庫,但是當前廣泛使用的數據庫是sqlite3(僅適合測試和開發工作),MySQL和PostgreSQL。
g) OpenStack Glance,是一個單獨的項目,它是一個compute架構中可選的部分,分為三個部分:glance-api, glance-registry and the image store. 其中,glance-api接受API調用,glance-registry負責存儲和檢索鏡像的元數據,實際的Image Blob存儲在Image Store中。Image Store可以是多種不同的Object Store,包括OpenStack Object Storage (Swift)
h) 最后,user dashboard是另一個可選的項目。OpenStack Dashboard提供了一個OpenStack Compute界面來給應用開發者和devops staff類似API的功能。當前它是作為Django web Application來實現的。當然,也有其他可用的Web前端。
3.2 概念映射
將邏輯架構映射到概念架構中(如3-2所示),可以看見我們還缺少什么。
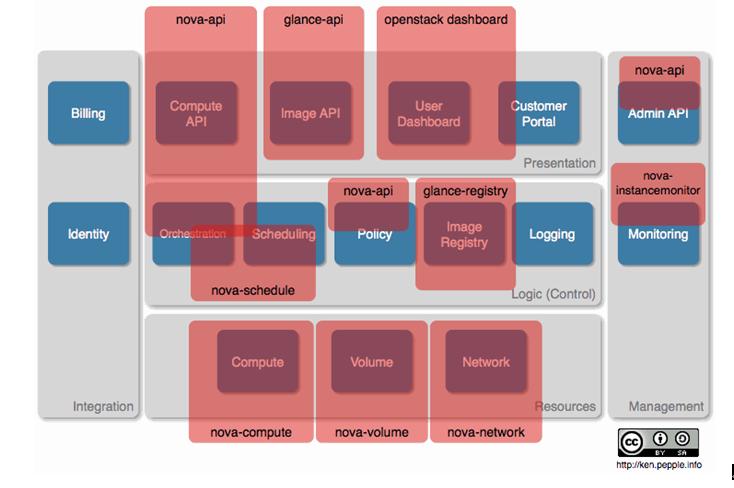
3-2 邏輯架構到概念架構的映射
這種覆蓋方式并不是唯一的,這里的只是作者的理解。通過覆蓋OpenStack Compute 邏輯組件,Glance和Dashboard,來表示功能范圍。對于每一個覆蓋,都有相應的提供該功能的邏輯組件的名稱。
a) 在這種覆蓋范圍中,最大的差距是logging和billing。此刻,OpenStack Compute沒有能協調logging事件、記錄日志以及創建/呈現bills的Billing組件。真正的焦點是logging和Billing的整合。這能通過以下方式來補救。比如代碼擴充,商業產品或者服務或者自定義日志解析的整合。
b) Identity也是未來可能要補充的一點。
c) customer portal也是一個整合點。user dashboard(見運行的實例,啟動新的實例)沒有提供一個界面,來允許應用擁有者簽署服務,跟蹤它們的費用以及聲明有問題的票據(lodge trouble tickets)。而且,這很可能對我們設想的服務提供商來說是合適的。
d) 理想的情況是,Admin API會復制我們能通過命令行接口做的所有功能。在帶有Admin API work的Diablo 發布中會更好。
e) 云監控和操作將是服務提供商關注的重點。好操作方法的關鍵是好的工具。當前,OpenStack Compute 提供 nova-instancemonitor,它跟蹤計算結點使用情況。未來我們還需要三方工具來監控。
f) Policy是極其重要的方面,但是會與供應商很相關。從quotas到QoS,到隱私控制都在其管轄內。當前圖上有部分覆蓋,但是這取決于供應商的復雜需求。為準確起見,OpenStack Compute 為實例,浮點IP地址以及元數據提供配額。
g) 當前,OpenStack Compute內的Scheduling對于大的安裝來說是相當初步的。調度器是以插件的方式設計的,目前支持chance(隨機主機分配),simple(最少負載)和zone(在一個可用區域里的隨機結點。)分布式的調度器和理解異構主機的調度器正在開發之中。
如你所見,OpenStack Compute為我們想象的服務提供商,提供了一個不錯的基礎,只要服務提供商愿意做一些整合。
3.3 OpenStack Compute系統架構
OpenStack Compute由一些主要組件組成。“Cloud controller”包含很多組件,它表示全局狀態,以及與其他組件交互。實際上,它提供的是Nova-api服務。它的功能是:為所有API查詢提供一個端點,初始化絕大多數的部署活動,以及實施一些策略。API 服務器起cloud controller web Service前端的作用。Compute controller 提供compute服務資源,典型包含compute service,Object Store component可選地提供存儲服務。Auth manager提供認證和授權服務,Volume controller為compute servers提供快速和持久的塊級別存儲。Network controller提供虛擬網絡使compute servers彼此交互以及與公網進行交互。Scheduler選擇最合適的compute controller來管理(host)一個實例。
OpenStack Compute建立在無共享、基于消息的架構上。Cloud controller通過HTTP與internal object store交互,通過AMQP和scheduler、network controller、 和volume controller 來進行通信。為了避免在等待接收時阻塞每個組件,OpenStack Compute用異步調用的方式。
為了獲得帶有一個組件多個備份的無共享屬性,OpenStack Compute將所有的云系統狀態保持在分布式的數據存儲中。對系統狀態的更新會寫到這個存儲中,必要時用質子事務。
對系統狀態的請求會從store中讀出。在少數情況下,控制器也會短時間緩存讀取結果。
3.4 OpenStack Compute物理架構
OpenStack Compute采用無共享、基于消息的架構,非常靈活,我們能安裝每個nova- service在單獨的服務器上,這意味著安裝OpenStack Compute有多種可能的方法。可能多結點部署唯一的聯合依賴性,是Dashboard必須被安裝在nova-api服務器。幾種部署架構如下:
a) 單結點:一臺服務器運行所有的nova- services,同時也驅動虛擬實例。這種配置只為嘗試OpenStack Compute,或者為了開發目的;
b) 雙結點:一個cloud controller 結點運行除nova-compute外的所有nova-services,compute結點運行nova-compute。一臺客戶計算機很可能需要打包鏡像,以及和服務器進行交互,但是并不是必要的。這種配置主要用于概念和開發環境的證明。
c) 多結點:通過簡單部署nova-compute在一臺額外的服務器以及拷貝nova.conf文件到這個新增的結點,你能在兩結點的基礎上,添加更多的compute結點,形成多結點部署。在較為復雜的多結點部署中,還能增加一個volume controller 和一個network controller作為額外的結點。對于運行多個需要大量處理能力的虛擬機實例,至少是4個結點是最好的。
一個可能的Openstack Compute多服務器部署(集群中聯網的虛擬服務器可能會改變)如下3-3所示:
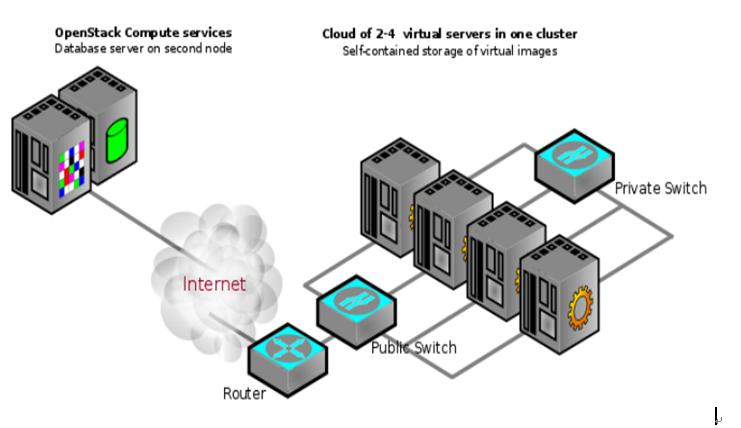
3-3 OpenStack Compute物理架構一
如果你注意到消息隊列中大量的復制引發了性能問題,一種可選的架構是增加更多的Messaging服務器。在這種情形下,除了可以擴展數據庫服務器外,還可以增加一臺額外的RabbitMQ服務器。部署中可以在任意服務器上運行任意nova-service,只要nova.conf中配置為指向RabbitMQ服務器,并且這些服務器能發送消息到它。
下圖3-4是另外一種多結點的部署架構。
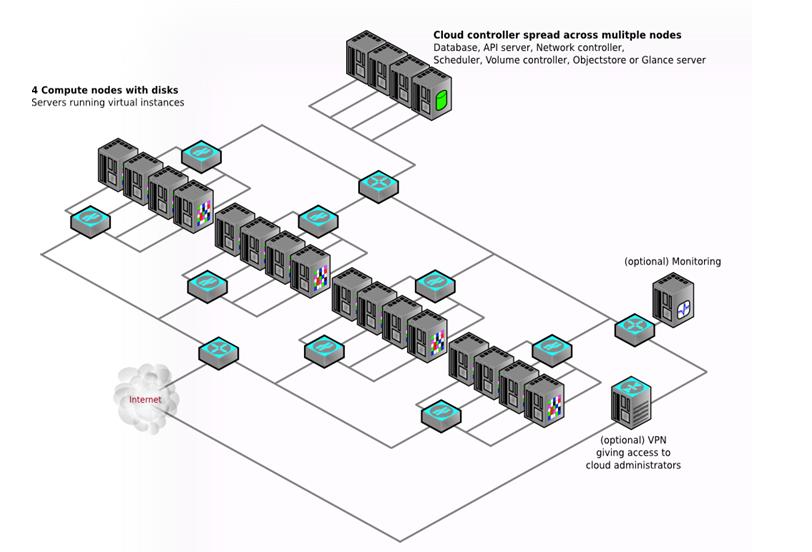
3-4 多結點的部署架構二
3.5 OpenStack Compute服務架構
因為Compute有多個服務,也可能有多種配置,下圖3-5顯示了總體的服務架構,以及服務之間的通信系統。
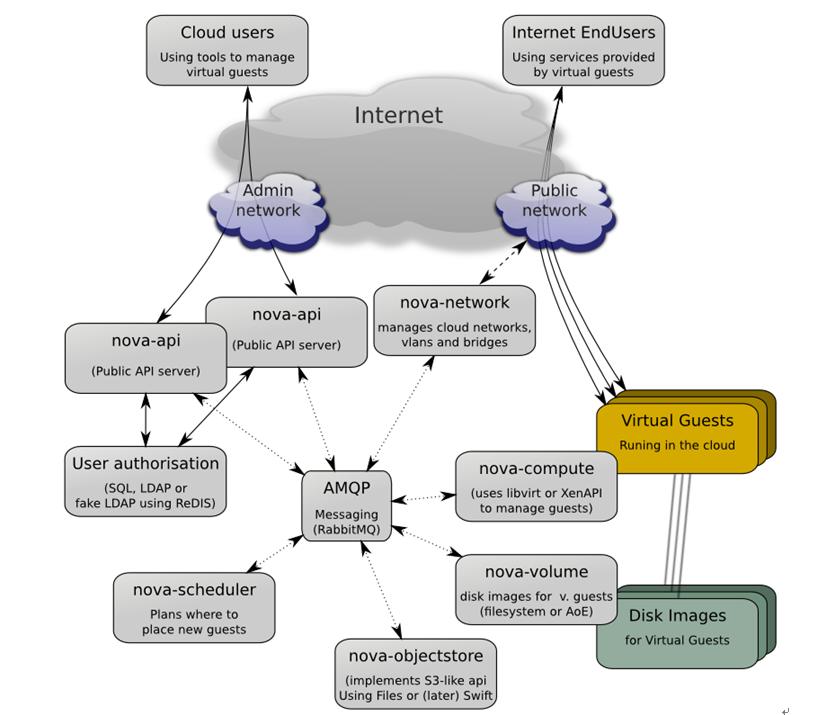
3-5 OpenStack Compute服務架構
4. OpenStack Image Service
OpenStack Image Service包括兩個主要的部分,分別是API server和Registry server(s)。
OpenStack Image Service的設計,盡可能適合各種后端倉儲和注冊數據庫方案。API Server(運行“glance api”程序)起通信hub的作用。比如各種各樣的客戶程序,鏡像元數據的注冊,實際包含虛擬機鏡像數據的存儲系統,都是通過它來進行通信的。API server轉發客戶端的請求到鏡像元數據注冊處和它的后端倉儲。OpenStack Image Service就是通過這些機制來實際保存進來的虛擬機鏡像的。
OpenStack Image Service支持的后端倉儲有:
a) OpenStack Object Storage。它是OpenStack中高可用的對象存儲項目。
b) FileSystem。OpenStack Image Service存儲虛擬機鏡像的默認后端是后端文件系統。這個簡單的后端會把鏡像文件寫到本地文件系統。
c) S3。該后端允許OpenStack Image Service存儲虛擬機鏡像在Amazon S3服務中。
d) HTTP。OpenStack Image Service能通過HTTP在Internet上讀取可用的虛擬機鏡像。這種存儲方式是只讀的。
OpenStack Image Service registry servers是遵守OpenStack Image Service Registry API的服務器。
根據安裝手冊,這兩個服務安裝在同一個服務器上。鏡像本身則可存儲在OpenStack Object Storage, Amazon's S3 infrastructure,fileSystem。如果你只需要只讀訪問,可以存儲在一臺Web服務器上。
5. OpenStack Object Storage
5.1 關鍵概念
a) Accounts和 Account Servers
OpenStack Object Storage系統被設計來供許多不同的存儲消費者或客戶使用。每個用戶必須通過認證系統來識別自己。為此,OpenStack Object Storage提供了一個授權系統(swauth)。
運行Account服務的結點與個體賬戶是不同的概念。Account服務器是存儲系統的部分,必須和Container服務器和Object服務器配置在一起。
b) Authentication 和 Access Permissions
你必須通過認證服務來認證,以接收OpenStack Object Storage連接參數和認證令牌。令牌必須為所有后面的container/object操作而傳遞。典型的,特定語言的API處理認證,令牌傳遞和HTTPS request/response 通信。
通過運用X-Container-Read: accountname和 X-Container-Write: accountname:username,你能為用戶或者賬戶對對象執行訪問控制。比如,這個設置就允許來自accountname賬戶的的任意用戶來讀,但是只允許accountname賬戶里的用戶username來寫。你也能給OpenStack Object Storage中存儲的對象授予公共訪問的權限,而且可以通過Referer頭部阻止像熱鏈接這種基于站點的內容盜竊,來限制公共訪問。公共的container設置被用作訪問控制列表之上的默認授權。比如,X-Container-Read: referer: any 這個設置,允許任何人能從container中讀,而不管其他的授權設置。
一般來說,每個用戶能完全訪問自己的存儲賬戶。用戶必須用他們的證書來認證,一旦被認證,他們就能創建或刪除container,以及賬戶之類的對象。一個用戶能訪問另一個賬戶的內容的唯一方式是,他們享有一個API訪問key或你的認證系統提供的會話令牌。
c) Containers and Objects
一個Container是一個存儲隔間,為你提供一種組織屬于屬于你的數據的方式。它比較類似于文件夾或目錄。Container和其他文件系統概念的主要差異是containers不能嵌套。然而,你可以在你的賬戶內創建無數的containers。但是你必須在你的賬戶上有一個container,因為數據必須存在Container中。
Container取名上的限制是,它們不能包含“/”,而且長度上少于256字節。長度的限制也適用于經過URL編碼后的名字。比如,Course Docs的Container名經過URL編碼后是“Course%20Docs”,因此此時的長度是13字節而非11字節。
一個對象是基本的存儲實體,和表示你存儲在OpenStack Object Storage系統中文件的任何可選的元數據。當你上傳數據到OpenStack Object Storage,它原樣存儲,由一個位置(container),對象名,以及key/value對組成的任何元數據。比如,你可選擇存儲你數字照片的副本,把它們組織為一個影集。在這種情況下,每個對象可以用元數據Album :
Caribbean Cruise 或Album : Aspen Ski Trip來標記。
對象名上唯一的限制是,在經過URL編碼后,它們的長度要少于1024個字節。
上傳的存儲對象的允許的最大大小5GB,最小是0字節。你能用內嵌的大對象支持和St工具來檢索5GB以上的對象。對于元數據,每個對象不應該超過90個key/value對,所有key/value對的總字節長度不應該超過4KB。
d) Operations
Operations是你在OpenStack Object Storage系統上執行的行為,比如創建或刪除containers,上傳或下載objects等等。Operations的完全清單可以在開發文檔上找到。Operations能通過ReST web service API或特定語言的API來執行。值得強調的是,所有操作必須包括一個來自你授權系統的有效的授權令牌。
e) 特定語言的API綁定
一些流行語言支持的API 綁定,在RackSpace云文件產品中是可用的。這些綁定在基礎ReST API上提供了一層抽象,允許變成人員直接與container和object模型打交道,而不是HTTP請求和響應。這些綁定可免費下載,使用和修改。它們遵循MIT許可協議。對于OpenStack Object Storage,當前支持的API綁定是:PHP,Python,Java,C#/.NET 和Ruby。
5.2 Object Storage如何工作
a) Ring
Ring 代表磁盤上存儲的實體的名稱和它們的物理位置的映射。accounts, containers, and objects都有單獨的Ring。其他組件要在這三者之一進行任何操作,他們都需要合相應的Ring進行交互以確定它在集群中的位置。
Ring用zones,devices,partitions,和replicas來維護映射,在Ring中的每個分區都會在集群中默認有三個副本。分區的位置存儲在Ring維護的映射中。Ring也負責確定失敗場景中接替的設備。(這點類似HDFS副本的復制)。分區的副本要保證存儲在不同的zone。Ring的分區分布在OpenStack Object Storage installation所有設備中。分區需要移動的時候,Ring確保一次移動最少的分區,一次僅有一個分區的副本被移動。
權重能用來平衡分區在磁盤驅動上的分布。Ring在代理服務器和一些背景進程中使用。
b) Proxy Server
代理服務器負責將OpenStack Object Storage架構中其他部分結合在一起。對于每次請求,它都查詢在Ring中查詢account, container, or object的位置,并以此轉發請求。公有APIs也是通過代理服務器來暴露的。
大量的失敗也是由代理服務器來進行處理。比如一個服務器不可用,它就會要求Ring來為它找下一個接替的服務器,并把請求轉發到那里。
當對象流進或流出object server時,它們都通過代理服務器來流給用戶,或者通過它從用戶獲取。代理服務器不會緩沖它們。
Proxy服務器的功能可以總結為:查詢位置,處理失敗,中轉對象。
c) Object Server
Object Server,是非常簡單的blob存儲服務器,能存儲、檢索和刪除本地磁盤上的對象,它以二進制文件形式存放在文件系統中,元數據以文件的擴展屬性存放。
對象以源于對象名的hash和操作的時間戳的路徑來存放。上一次寫總會成功,確保最新的版本將被使用。刪除也視作文件的一個版本:這確保刪除的文件也被正確復制,更舊的把本不會因為失敗情形離奇消失。
d) Container Server
其主要工作是處理對象列表,它不知道對象在哪里,只是知道哪些對象在一個特定的container。列表被存儲為sqlite 數據庫文件,類似對象的方式在集群中復制。也進行了跟蹤統計,包括對象的總數,以及container中使用的總存儲量。
e) Account Server
它是類似于Container Server,除了它是負責containers的列表而非對象。
f) Replication
設計副本的目的是,在面臨網絡中斷或驅動失敗等臨時錯誤條件時,保持系統在一致的狀態。
副本進程會比較本地的數據和每個遠處的副本,以確保他們所有都包含最新的版本。對象副本用一個Hash列表來快速比較每個分區的片段,而containe和 account replication 用的是Hash和共享的高水印結合的方法。
副本的更新,是基于推送的。對于對象副本,更新是遠程同步文件到Peer。Account和container replication通過HTTP or rsync把整個數據庫文件推送遺失的記錄。
副本也通過tombstone設置最新版本的方式,確保數據從系統中清除。
g) 更新器(Updaters)
有時,container 或 account數據不能被立即更新,這通常是發生在失敗的情形或高負載時期。如果一個更新失敗,該更新會在文件系統上本地排隊,更新器將處理這些失敗的更新。事件一致性窗口(eventual consistency window)最可能來起作用。比如,假設一個container服務器正處于載入之中,一個新對象正被放進系統,代理服務器一響應客戶端成功,該對象就立即可讀了。然而,container服務器沒有更新Object列表,所以更新就進入隊列,以等待稍后的更新。Container列表,因此可能還不會立即包含這個對象。
實際上,一致性窗口只是與updater運行的頻率一樣大,當代理服務器將轉發清單請求到響應的第一個container服務器中,也許甚至還不會被注意。在載入之下的服務器可能還不是服務后續清單請求的那個。另外兩個副本中的一個可能處理這個清單。
h) Auditors
Auditors會檢查objects, containers, 和 accounts的完整性。如果發先損壞的文件,它將被隔離,好的副本將會取代這個壞的文件。如果發現其他的錯誤,它們會記入到日志中。
5.3 OpenStack Object Storage物理架構
Proxy Services 偏向于CPU和network I/O 密集型,而 Object Services, Container Services, Account Services 偏向于disk and networkI/O 密集型。
可以在每一服務器上安裝所有的服務,在Rackspace內部, 他們將Proxy Services放在他們自己的服務器上,而所有存儲服務則放在同一服務器上。這允許我們發送10G的網絡給代理,1G給存儲服務器,從而保持對代理服務器的負載平衡更好管理。我們能通過增加更多代理來擴展整個API吞吐量。如果需要獲得Account或 Container Services更大的吞吐量,它們也可以部署到自己的服務器上。
在部署OpenStack Object Storage時,可以單結點安裝,但是它只適用于開發和測試目的。也可以多服務器的安裝,它能獲得分布式對象存儲系統需要的高可用性和冗余。
有這樣一個樣本部署架構,如圖5-1所示。一個Proxy 結點,運行代理服務,一個Auth 結點,運行認證服務,五個Storage結點,運行Account,Container和Object服務。
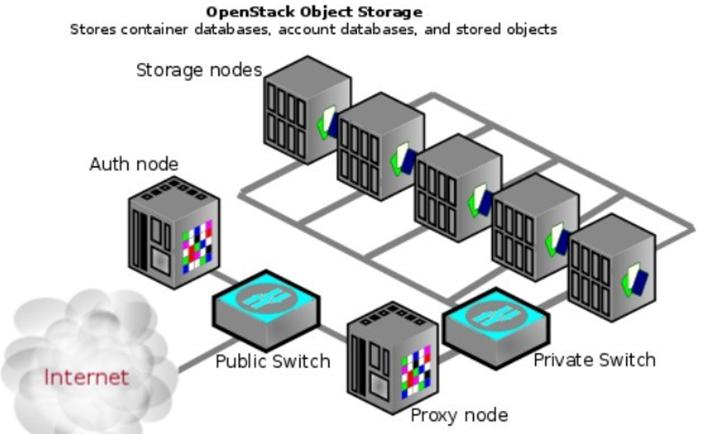
5-1 五個Storage結點的OpenStack Object Storage物理架構
以上是“OpenStack是什么意思”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





