溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“怎么讓Hadoop運行得更快一些”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“怎么讓Hadoop運行得更快一些”這篇文章吧。
Hadoop是用以下的方式來解決速度問題:
1 使用分布式文件系統:這使得負載分攤,并壯大系統
2 優化寫入速度:為了獲得更快的寫入速度,Hadoop架構是設計成先寫入記錄,然后在進行處理
3 使用批處理(Map/Reduce)來平衡數據傳送速度和處理速度。
批處理所帶來的挑戰
批量處理的挑戰在于,數據必須要間斷性地進入才能保證流程正常運作,而如果數據源連續地輸入,就會造成系統崩潰。
如果我們增加批處理窗口的話,結果就會增加數據處理過程的時間,使得相關的數據分析報告也要推遲落入我們的手中。在許多系統里,他們會選擇在非高峰時間進行數據批處理,而這個時間是非常有限的。隨著數據的體積不斷脹大,處理數據的時間就不斷增加,這樣發展下去的話,需要被處理的數據就會不斷積壓。這最終的結果有可能一天都處理不完數據。
通過流處理來提升速度
流處理的概念是非常簡單的。我們并不需要等到所有數據記錄完后才進行處理,我們可以邊記錄邊處理。
拿生產線來做比喻,我們可以等到所有的組件齊全后才開始裝配汽車,也可以在生產廠那邊把組件包裝好,然后再送到特定的生產線,并馬上組裝起來。不用說,你也知道哪個速度會更快一點吧。
數據處理就跟生產線一樣,而流處理進程就是把數據包裝起來,并送到特定的“生產線”上。而在傳統行業上,即使生產商把所有的部件都預裝起來,我們依然需要一條生產線來組裝。同樣,流處理并不是要取代Hadoop,它只是用于減少系統大量工作,從而提升系統的處理速度。
Curt Monash在他的“傳統數據庫最終會在RAM中終結”的研究中指出的,內存間的流處理能夠打造出更好的流處理系統。下面就是一個實時大數據的分析案例,并用Twitter來演示數據的相應處理方式。
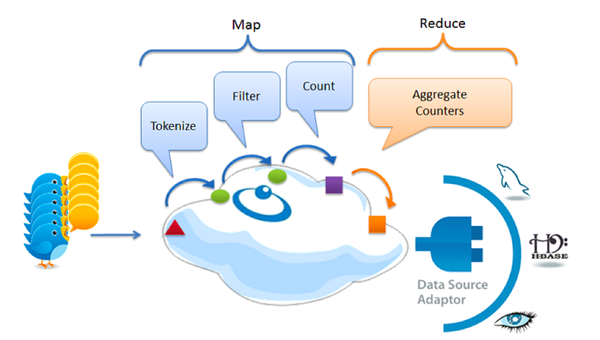
Google更快的處理方案:用流處理來替代Map/Reduce
由于當時缺乏可替方案,即使Map/Reduce性能不佳,許多大數據系統依然要使用這個技術。一個***的應用例子就是使用這項技術來維護全球的搜索索引。現在Google在索引處理方面大大減少使用Map/Reduce,反而加入了實時處理模式,這使得索引速度縮短為原來的一百分之一。
在網絡中,一些類型的數據在不斷膨脹。這也是HBase為什么計入觸發式處理的原因,而Twitter未來將要處理更龐大的流數據。
以上是“怎么讓Hadoop運行得更快一些”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





