溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關如何分析JavaScrip中的Base64編碼和解碼,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
Base64是最常用的編碼之一,比如開發中用于傳遞參數、現代瀏覽器中的<img />標簽直接通過Base64字符串來渲染圖片以及用于郵件中等等。Base64編碼在RFC2045中定義,它被定義為:Base64內容傳送編碼被設計用來把任意序列的8位字節描述為一種不易被人直接識別的形式。
我們知道,任何數據在計算機中都是以二進制的方式存儲的。一個字節為8位,一個字符在計算機中存儲為一個或多個字節,比如英文字母、數字以及英文標點符號就是用一個 字節來存儲的,通常稱為ASCII碼。而簡體中文、繁體中文、日文以及韓文等都是用多字節來存儲的,通常稱為多字節字符。因為Base64編碼是對字符串的編碼表示進行處理的,不同編碼的字符串的Base64的結果是不同的,所以我們需要了解基本的字符編碼知識。
計算機最開始只支持ASCII碼,一個字符用一個字節表示,只用了低7位,***位為0,因此總共有128個ASCII碼,范圍為0~127。后來為了支持多種地區的語言,各大組織機構和IT廠商開始發明它們自己的編碼方案,以便彌補ASCII編碼的不足,如GB2312編碼、GBK編碼和Big5編碼等。但這些編碼都只是針對局部地區或少數語言文字,沒有辦法表達所有的語言文字。而且這些不同的編碼之間并沒有任何聯系,它們之間的轉換需要通過查表來實現。
為了提高計算機的信息處理和交換功能,使得世界各國的文字都能在計算機中處理,從1984年起,ISO組織就開始研究制定一個全新的標準:通用多八位(即多字節)編碼字符集(Universal Multiple-Octet Coded Character Set),簡稱UCS。標準的編號為:ISO 10646。這一標準為世界各種主要語言的字符(包括簡體及繁體的中文字)及附加符號,編制統一的內碼。
統一碼(Unicode)是Universal Code的縮寫,是由另一個叫“Unicode學術學會”(The Unicode Consortium)的機構制定的字符編碼系統。Unicode與ISO 10646國際編碼標準從內容上來說是同步一致的。具體可參考:Unicode 。
ANSI
ANSI不代表具體的編碼,它是指本地編碼。比如在簡體版windows上它表示GB2312編碼,在繁體版windows上它表示Big5編碼,在日文操作系統上它表示JIS編碼。所以如果您新建了個文本文件并保存為ANSI編碼,那么您現在應該知道這個文件的編碼為本地編碼。
Unicode
Unicode編碼是和字符表一一映射的。比如56DE代表漢字'回',這種映射關系是固定不變的。通俗的說Unicode編碼就是字符表的坐標,通過56DE就能找到漢字'回'。Unicode編碼的實現包括UTF8、UTF16、UTF32等等。
Unicode本身定義的就是每個字符的數值,是字符和自然數的映射關系,而UTF-8或者UTF-16甚至UTF-32則定義了如何在字節流中斷字,是計算機領域的概念。

通過上圖我們知道,UTF-8編碼為變長的編碼方式,占1~6個字節,可通過Unicode編碼值的區間來判斷,并且每個組成UTF8字符的字節都是有規律可循的。本文只討論UTF8和UTF16這兩種編碼。
UTF16
UTF16編碼使用固定的2個字節來存儲。因為是多字節存儲,所以它的存儲方式分為2種:大端序和小端序。UTF16編碼是Unicode最直接的實現方式,通常我們在windows上新建文本文件后保存為Unicode編碼,其實就是保存為UTF16編碼。UTF16編碼在windows上采用小端序的方式存儲,以下我新建了個文本文件并保存為Unicode編碼來測試,文件中只輸入了一個漢字'回',之后我用Editplus打開它,切換到十六進制方式查看,如圖所示:
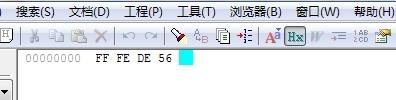
我們看到有4個字節,前2個字節FF FE是文件頭,表示這是一個UTF16編碼的文件,而DE 56則是'回'的UTF16編碼的十六進制。我們經常使用的JavaScript語言,它內部就是采用UTF16編碼,并且它的存儲方式為大端序,來看一個例子:
<script type="text/javascript"> console.group('Test Unicode: '); console.log(('回'.charCodeAt(0)).toString(16).toUpperCase()); </script>
很明顯跟剛才Editplus顯示的不一樣,順序是相反的,這是因為字節序不一樣。具體可參考:UTF-16 。
UTF8
UTF8是采用變長的編碼方式,為1~6個字節,但通常我們只把它看作單字節或三字節的實現,因為其它情況實在少見。UTF8編碼通過多個字節組合的方式來顯示,這是計算機處理UTF8的機制,它是無字節序之分的,并且每個字節都非常有規律,詳見上圖,在此不再詳述。
UTF16轉UTF8
UTF16和UTF8之間的相互轉換可以通過上圖的轉換表來實現,判斷Unicode碼所在的區間就可以得到這個字符是由幾個字節所組成,之后通過移位來實現。我們用漢字'回'來舉一個轉換的例子。
我們已經知道漢字'回'的Unicode碼是0x56DE,它介于U+00000800 – U+0000FFFF之間,所以它是用三個字節來表示的。

所以我們需要將0x56DE這個雙字節的值變為三字節的值,注意上圖中的x部分,就是對應0x56DE的各位字節,如果您數一下x的個數,會發現剛好是16位。
轉換思路
從0x56DE中取出4位放在低位,并和二進制的1110結合,這就是***個字節。從0x56DE中剩下的字節中取出6位放在低位,并和二進制的10結合,這就是第二個字節。第三個字節依照類似的方式實現。
代碼實現
為了讓大家更好的理解,以下代碼只是實現漢字'回'的轉換,代碼如下:
<script type="text/javascript"> /** * 轉換對照表 * U+00000000 – U+0000007F 0xxxxxxx * U+00000080 – U+000007FF 110xxxxx 10xxxxxx * U+00000800 – U+0000FFFF 1110xxxx 10xxxxxx 10xxxxxx * U+00010000 – U+001FFFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx * U+00200000 – U+03FFFFFF 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx * U+04000000 – U+7FFFFFFF 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx */ /* * '回'的Unicode編碼為:0x56DE,它介于U+00000800 – U+0000FFFF之間,所以它占用三個字節。 * U+00000800 – U+0000FFFF 1110xxxx 10xxxxxx 10xxxxxx */ var ucode = 0x56DE; // 1110xxxx var byte1 = 0xE0 | ((ucode >> 12) & 0x0F); // 10xxxxxx var byte2 = 0x80 | ((ucode >> 6) & 0x3F); // 10xxxxxx var byte3 = 0x80 | (ucode & 0x3F); var utf8 = String.fromCharCode(byte1) + String.fromCharCode(byte2) + String.fromCharCode(byte3); console.group('Test UTF16ToUTF8: '); console.log(utf8); console.groupEnd(); </script>
輸出的結果看起來像亂碼,這是因為JavaScript不知道如何顯示UTF8的字符。您或許會說輸出不正常轉換還有什么用,但您應該知道轉換的目的還經常用于傳輸或API的需要。
UTF8轉UTF16
這是UTF16轉換到UTF8的逆轉換,同樣需要對照轉換表來實現。還是接上一個例子,我們已經得到了漢字'回'的UTF8編碼,這是三個字節的,我們只需要按照轉換表來轉成雙字節的,如圖所示,我們需要保留下所有的x。
代碼如下:
<script type="text/javascript"> /** * 轉換對照表 * U+00000000 – U+0000007F 0xxxxxxx * U+00000080 – U+000007FF 110xxxxx 10xxxxxx * U+00000800 – U+0000FFFF 1110xxxx 10xxxxxx 10xxxxxx * U+00010000 – U+001FFFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx * U+00200000 – U+03FFFFFF 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx * U+04000000 – U+7FFFFFFF 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx */ /* * '回'的Unicode編碼為:0x56DE,它介于U+00000800 – U+0000FFFF之間,所以它占用三個字節。 * U+00000800 – U+0000FFFF 1110xxxx 10xxxxxx 10xxxxxx */ var ucode = 0x56DE; // 1110xxxx var byte1 = 0xE0 | ((ucode >> 12) & 0x0F); // 10xxxxxx var byte2 = 0x80 | ((ucode >> 6) & 0x3F); // 10xxxxxx var byte3 = 0x80 | (ucode & 0x3F); var utf8 = String.fromCharCode(byte1) + String.fromCharCode(byte2) + String.fromCharCode(byte3); console.group('Test UTF16ToUTF8: '); console.log(utf8); console.groupEnd(); /** ------------------------------------------------------------------------------------*/ // 由三個字節組成,所以分別取出 var c1 = utf8.charCodeAt(0); var c2 = utf8.charCodeAt(1); var c3 = utf8.charCodeAt(2); /* * 需要通過判斷特定位的方式來轉換,但這里是已知是三個字節,所以忽略判斷,而是直接拿到所有的x,組成16位。 * U+00000800 – U+0000FFFF 1110xxxx 10xxxxxx 10xxxxxx */ // 丟棄***個字節的高四位并和第二個字節的高四位組成一個字節 var b1 = (c1 << 4) | ((c2 >> 2) & 0x0F); // 同理第二個字節和第三個字節組合 var b2 = ((c2 & 0x03) << 6) | (c3 & 0x3F); // 將b1和b2組成16位 var ucode = ((b1 & 0x00FF) << 8) | b2; console.group('Test UTF8ToUTF16: '); console.log(ucode.toString(16).toUpperCase(), String.fromCharCode(ucode)); console.groupEnd(); </script>
知道了轉換規則,就很容易實現了。
Base64編碼要求把3個8位字節(3*8=24)轉化為4個6位的字節(4*6=24),之后在6位的前面補兩個0,形成8位一個字節的形式。由于2的6次方為64,所以每6個位為一個單元,對應某個可打印字符。當原數據不是3的整數倍時,如果***剩下兩個輸入數據,在編碼結果后加1個“=;如果***剩下一個輸入數據,編碼結果后加2個“=;如果沒有剩下任何數據,就什么都不要加,這樣才可以保證資料還原的正確性。
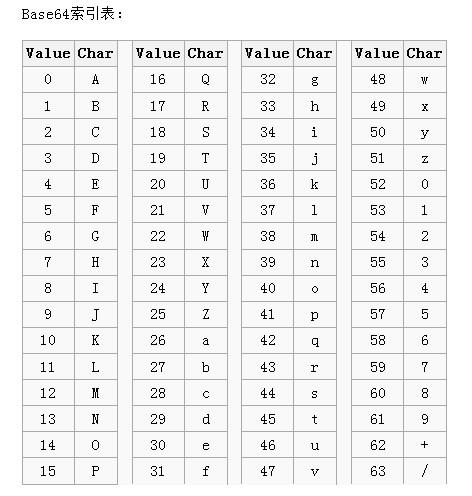
轉碼對照表
每6個單元高位補2個零形成的字節位于0~63之間,通過在轉碼表中查找對應的可打印字符。“=”用于填充。如下圖所示為轉碼表。
具體可參考: Base64 。
解碼是編碼的逆過程,先看后面補了幾個“=”號,最多只可能補2個“=”號。一個“=”相當于補了2個0,所以去掉后面補的0后,再按8位展開,即可還原。
之前已經詳細講解了整個過程,本文的例子都是采用UTF8編碼的字符串作為Base64編碼的基礎。因為JavaScript內部是使用Unicode編碼,所以需要有個轉換過程,原理之前也詳細講解過并給出了示例,以下是代碼實現:
<script type="text/javascript"> /** * UTF16和UTF8轉換對照表 * U+00000000 – U+0000007F 0xxxxxxx * U+00000080 – U+000007FF 110xxxxx 10xxxxxx * U+00000800 – U+0000FFFF 1110xxxx 10xxxxxx 10xxxxxx * U+00010000 – U+001FFFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx * U+00200000 – U+03FFFFFF 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx * U+04000000 – U+7FFFFFFF 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx */ var Base64 = { // 轉碼表 table : [ 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O' ,'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '+', '/' ], UTF16ToUTF8 : function(str) { var res = [], len = str.length; for (var i = 0; i < len; i++) { var code = str.charCodeAt(i); if (code > 0x0000 && code <= 0x007F) { // 單字節,這里并不考慮0x0000,因為它是空字節 // U+00000000 – U+0000007F 0xxxxxxx res.push(str.charAt(i)); } else if (code >= 0x0080 && code <= 0x07FF) { // 雙字節 // U+00000080 – U+000007FF 110xxxxx 10xxxxxx // 110xxxxx var byte1 = 0xC0 | ((code >> 6) & 0x1F); // 10xxxxxx var byte2 = 0x80 | (code & 0x3F); res.push( String.fromCharCode(byte1), String.fromCharCode(byte2) ); } else if (code >= 0x0800 && code <= 0xFFFF) { // 三字節 // U+00000800 – U+0000FFFF 1110xxxx 10xxxxxx 10xxxxxx // 1110xxxx var byte1 = 0xE0 | ((code >> 12) & 0x0F); // 10xxxxxx var byte2 = 0x80 | ((code >> 6) & 0x3F); // 10xxxxxx var byte3 = 0x80 | (code & 0x3F); res.push( String.fromCharCode(byte1), String.fromCharCode(byte2), String.fromCharCode(byte3) ); } else if (code >= 0x00010000 && code <= 0x001FFFFF) { // 四字節 // U+00010000 – U+001FFFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx } else if (code >= 0x00200000 && code <= 0x03FFFFFF) { // 五字節 // U+00200000 – U+03FFFFFF 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx } else /** if (code >= 0x04000000 && code <= 0x7FFFFFFF)*/ { // 六字節 // U+04000000 – U+7FFFFFFF 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx } } return res.join(''); }, UTF8ToUTF16 : function(str) { var res = [], len = str.length; var i = 0; for (var i = 0; i < len; i++) { var code = str.charCodeAt(i); // 對***個字節進行判斷 if (((code >> 7) & 0xFF) == 0x0) { // 單字節 // 0xxxxxxx res.push(str.charAt(i)); } else if (((code >> 5) & 0xFF) == 0x6) { // 雙字節 // 110xxxxx 10xxxxxx var code2 = str.charCodeAt(++i); var byte1 = (code & 0x1F) << 6; var byte2 = code2 & 0x3F; var utf16 = byte1 | byte2; res.push(Sting.fromCharCode(utf16)); } else if (((code >> 4) & 0xFF) == 0xE) { // 三字節 // 1110xxxx 10xxxxxx 10xxxxxx var code2 = str.charCodeAt(++i); var code3 = str.charCodeAt(++i); var byte1 = (code << 4) | ((code2 >> 2) & 0x0F); var byte2 = ((code2 & 0x03) << 6) | (code3 & 0x3F); utf16 = ((byte1 & 0x00FF) << 8) | byte2 res.push(String.fromCharCode(utf16)); } else if (((code >> 3) & 0xFF) == 0x1E) { // 四字節 // 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx } else if (((code >> 2) & 0xFF) == 0x3E) { // 五字節 // 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx } else /** if (((code >> 1) & 0xFF) == 0x7E)*/ { // 六字節 // 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx } } return res.join(''); }, encode : function(str) { if (!str) { return ''; } var utf8 = this.UTF16ToUTF8(str); // 轉成UTF8 var i = 0; // 遍歷索引 var len = utf8.length; var res = []; while (i < len) { var c1 = utf8.charCodeAt(i++) & 0xFF; res.push(this.table[c1 >> 2]); // 需要補2個= if (i == len) { res.push(this.table[(c1 & 0x3) << 4]); res.push('=='); break; } var c2 = utf8.charCodeAt(i++); // 需要補1個= if (i == len) { res.push(this.table[((c1 & 0x3) << 4) | ((c2 >> 4) & 0x0F)]); res.push(this.table[(c2 & 0x0F) << 2]); res.push('='); break; } var c3 = utf8.charCodeAt(i++); res.push(this.table[((c1 & 0x3) << 4) | ((c2 >> 4) & 0x0F)]); res.push(this.table[((c2 & 0x0F) << 2) | ((c3 & 0xC0) >> 6)]); res.push(this.table[c3 & 0x3F]); } return res.join(''); }, decode : function(str) { if (!str) { return ''; } var len = str.length; var i = 0; var res = []; while (i < len) { code1 = this.table.indexOf(str.charAt(i++)); code2 = this.table.indexOf(str.charAt(i++)); code3 = this.table.indexOf(str.charAt(i++)); code4 = this.table.indexOf(str.charAt(i++)); c1 = (code1 << 2) | (code2 >> 4); c2 = ((code2 & 0xF) << 4) | (code3 >> 2); c3 = ((code3 & 0x3) << 6) | code4; res.push(String.fromCharCode(c1)); if (code3 != 64) { res.push(String.fromCharCode(c2)); } if (code4 != 64) { res.push(String.fromCharCode(c3)); } } return this.UTF8ToUTF16(res.join('')); } }; console.group('Test Base64: '); var b64 = Base64.encode('Hello, oschina!又是一年春來到~'); console.log(b64); console.log(Base64.decode(b64)); console.groupEnd(); </script>
不得不說,在JavaScript中實現確實很麻煩。我們來看下PHP對同樣的字符串編碼的結果:

因為字符編碼是一樣的,所以結果也一樣。
看完上述內容,你們對如何分析JavaScrip中的Base64編碼和解碼有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





