溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Rust異步編程方式是什么”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Rust異步編程方式是什么”吧!
調度器是如何工作的?
調度器,顧名思義,就是如何調度程序執行。通常來說,程序會分成許多“工作單元”,我們將這種工作單元成為任務(task)。一個任務要么是可運行的,要么是掛起的(空閑的或阻塞的)。任務是彼此獨立的,因為處在“可運行的”任務都可能被并發的執行。調度器的職責就是執行任務,直到任務被掛起。這個過程中隱含得本質就是如何為任務分配全局資源——CPU 時間。
接下來的內容里只是圍繞“用戶空間”的調度器,有操作系統基礎知識的讀者應該明白,指的是運行于操作系統線程之上的調度器,而操作系統線程則是由內核調度器所調度。
Tokio 調度器會執行 Rust 的 future,就像我們討論 Java 語言、Go 語言等線程模型時一樣,Rust 的 future可以理解為 Rust 語言的“異步綠色線程”,它是 M:N 模式,很多用戶空間的任務通過多路復用跑在少量的系統線程上。
調度器的設計模式有很多種,每種都有各自的優缺點。但本質上,可以將調度器抽象得看作是一個(任務)隊列,以及一個不斷消費隊列中任務的處理器,我們可以用偽代碼表示成如下形式:
while let Some(task) = self.queue.pop { task.run;}當任務變成“可運行”的,就被插入到隊列中:
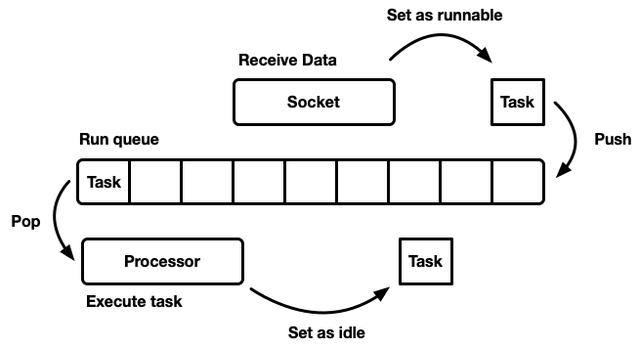
雖然我們可以設計成將資源、任務以及處理器都存在于一個單獨線程中,但 Tokio 還是選擇多線程模型。現代計算機都具有多個 CPU 以及多個物理核,使用單線程模型調度器會嚴重得限制資源利用率,所以為了盡可能壓榨所有 CPU 或物理核的能力,就需要:
單一全局的任務隊列,多處理器
多任務隊列,每個都有單獨的處理器
單隊列+多處理器
這種模型中,有一個全局的任務隊列。當任務處于“可運行的”狀態時,它被插到任務隊列尾。處理器們都在不同的線程上運行,每個處理器都從隊列頭取出任務并“消費”,如果隊列為空了,那所有線程(以及對應的處理器)都被阻塞。
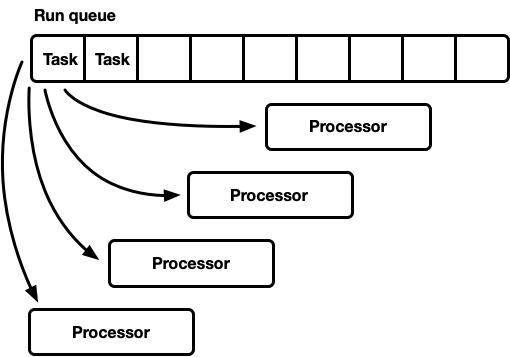
任務隊列必須支持多個生產者和多個消費者。這里常用的算法就是使用侵入式鏈表,這里的侵入式表示放入隊列的任務本身需要包含指向下(后)一個任務的指針。這樣在插入和彈出操作時就可以避免內存分配的操作,同時插入操作是無鎖,但彈出操作就需要一個信號量去協調多個消費者。
這種方式多用于實現通用線程池場景,它具有如下的優點:
任務會被公平地調度
實現相對簡單明了
上面說得公平調度意味著所有任務是以“先進先出”的方式來調度。這樣的方式在有一些場景下,比如使用 fork-join 方式的并行計算場景時就不夠高效了。因為唯一重要的考量是最終結果的計算速度,而非子任務的公平性。
當然這種調度模型也有缺點。所有的處理器(消費者)都守著隊列頭,導致處理器真正執行任務所消耗的時間遠遠大于任務從隊列中彈出的時間,這在長耗時型任務場景中是有益的,因為隊列爭用會降低。然而,Rust 的異步任務是被設計用于短耗時的,此時爭用隊列的開銷就變得很大了。
并發和“機械共情”
讀者們肯定聽過“為xxx平臺特別優化”這樣的表達,這是因為只有充分了解硬件架構,才能知道如何最大化利用硬件資源,才能設計出運行性能最高的程序。這就是所謂的“機械共情”,這個詞是由馬丁湯普森最初提出并使用的。
至于現代硬件架構下如何處理并發的相關細節并不在本文討論的范圍內,感興趣的讀者也可以閱讀文章末的更多參考資料部分。
通常來說,硬件不是通過提高速度(頻率)而是為程序提供更多的 CPU 核來獲取性能提升。每個核都可以在極短的時間內執行大量的計算,相較而言,訪問內存之類的操作則需要更多時間。因此,為了使程序運行得更快,我們必須使每次內存訪問的 CPU 指令數量最大化。盡管編譯器可以幫助我們做很多事,但作為程序設計開發人員,我們需要謹慎地考慮數據在內存中的結構布局以及訪問內存的模式。
當涉及到線程并發時,CPU 的緩存一致性機制就會發揮作用,它會確保每個 CPU 的緩存都保持最新狀態。
所以顯而易見,我們要盡可能地避免跨線程同步,因為它是性能殺手。
多處理器+多任務隊列
與前面的模型對比,在這種方式下,我們使用多個單線程調度器,每個處理器都有自己獨占的任務隊列,這樣完全避免了同步問題。由于 Rust 的任務模型要求任意線程都可以提交任務到隊列,所以我們仍需要設計一種線程安全的方式。要么每個處理器的任務隊列支持線程安全的插入操作(MPSC),要么就每個處理器有兩個隊列:非同步隊列和線程安全隊列。
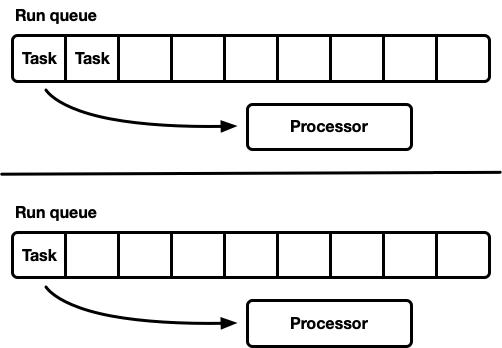
這便是 Seastar 所使用的策略。因為幾乎完全避免了同步,所以性能非常高。但需要注意的是,這并不是靈丹妙藥,因為無法確保任務負載都是完全一致統一的,處理器可能出現嚴重的負載不均衡,使得資源利用率低下。這通常產生的場景是任務被粘到了固定的、特定的處理器上。
眾所周知,真實世界的任務負載并不是一致統一的,所以在設計通用調度器時要避免使用此種模型。
“任務竊取”調度器
通常來說,任務竊取調度器是建立在分片調度模型之上的,主要為了解決資源利用率低的問題。每個處理器都具有自己獨占的任務隊列,處于“可運行的”任務會被插入到當前處理器的隊列中,并且只會被當前處理器所消費(執行)。但巧妙的是,當一個處理器空閑時,它會檢查同級的其他處理器的任務隊列,看看是不是能“竊取”一些任務來執行。這也是這種模型的名稱含義所在。最終,只有在無法從其他處理器的任務隊列那里獲得任務時該處理器就會進入休眠。
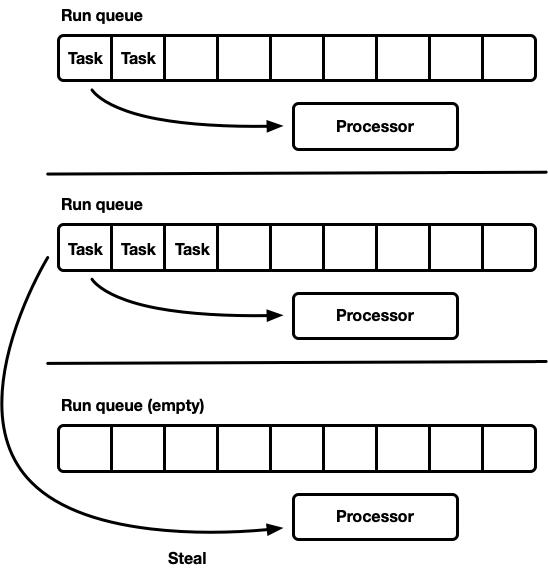
這幾乎是“兩全其美”的方法。處理器可以獨立運行,避免了同步開銷。而且如果任務負載在處理器間分布不均衡,調度器也能夠重新分配負載。正是由于這樣的特性,諸如 Go 語言、Erlang 語言、Java 語言等都采用了“任務竊取”調度器。
當然,它也是有缺點的,那就是它的復雜性。任務隊列必須支持“竊取”操作,并且需要一些跨處理器同步操作。整個過程如果執行不正確,那“竊取”的開銷就超過了模型本身的收益。
讓我們來考慮一個場景:處理器 A 當前正在執行任務,并且此刻它的任務隊列是空的;處理器 B 此時空閑,它嘗試“竊取”任務但是失敗了,因此進入休眠態。緊接著,處理器 A 所執行的任務產生出了20個(子)任務。目的是喚醒處理器 B。這進而就需要調度器在觀察到任務隊列中有新的任務時,向處于休眠態的處理器發出信號。顯而易見,這樣的場景下會需要額外的同步操作,但這恰恰是我們想要避免的。
綜上所述:
盡量減少同步操作總是好的
“任務竊取”是通用調度器的首選算法
處理器間基本是相互獨立的,但是“偷竊”操作時不可避免的需要一些同步操作
Tokio 0.1 調度器
2018年3月,Tokio 發布了其第一版基于“任務竊取”算法的調度器。但那個版本的實現中有一些瑕疵:
首先,I/O 型任務會被同時操作 I/O 選擇器(epoll、kqueue、iocp等)的線程所執行;更多與 CPU 綁定的任務會進入線程池。在這種情況下,活躍態線程的數量應該是靈活的、動態的,所以(適時得)關閉空閑態線程是合理的。但是,在“任務竊取”調度器上執行所有異步任務時,始終保持少量的活躍態線程是更合理的。
其次,當時采用了基于 Chase-Lev deque 算法的隊列,該算法后來被證明并不適合于調度獨立的異步任務場景。
第三,實現過于復雜。由于代碼中過多得使用 atomic,然而大部分情況下,mutex 是更好地選擇。
最后,代碼中有許多細小的低效設計和實現,但由于早期為保證 API 的穩定性,導致了一些技術債。
當然,隨著 Tokio 新版的發布,我們收獲了很多的經驗教訓,償還了許多技術債,這著實是令人興奮的!
下一代的 Tokio 調度器
現在我們深入解析一下新調度器的變更。
新的任務系統
首先,重要的亮點并不屬于 Tokio 的一部分,但對達成我們的成就至關重要:std 包含了由 Taylor Cramer設計的新的任務系統。該系統給調度系統提供了鉤子(hooks),方便調度器執行 Rust 異步任務,并且確實做得很好,比之前的版本更輕巧靈活。
Waker結構由資源保存,用于表示任務可運行并被推送到調度程序的運行隊列中。在新的任務系統中,Waker結構過去是更大的,但指針寬度為兩個指針。減小大小對于最小化復制Waker值的開銷以及在結構中占用較少的空間非常重要,從而允許將更多關鍵數據放入高速緩存行中。自定義vtable設計可實現許多優化,這將在后面討論。
更好的任務隊列
任務隊列是調度程序的核心,是最關鍵的組成部分。最初的tokio調度器使用crossbeam的deque實現,即單生產者、多消費者deque。任務從一端入隊,從另一端出隊。大多數情況下,入隊線程會出隊它,然而,其他線程偶爾會出隊任務來“竊取”。deque包含一個數組和一組追蹤頭部和尾部的索引。當deque滿了時,入隊數據將導致存儲空間增長。會分配一個新的、更大的數組,并將值移到新存儲區中。
雙端隊列增長的能力要付出復雜性和運行成本。入隊/出隊操作必須考慮到這種情況。此外,在隊列增長時,釋放原始數組會帶來額外的困難。在垃圾收集語言中,gc會釋放它。然而rust不帶GC,這意味著程序需要負責釋放數組,但線程可能正在并發訪問內存。Crossbeam對此的答案是采用基于代的回收策略。雖然開銷并不是非常大,但確實在代碼熱路徑中的增加了不小的開銷。每當進入和退出臨界區時,每個操作都必須是atomic RMW(讀修改寫)操作,以向其他線程發出信號。
由于增長本地隊列的相關成本不低,因此值得研究是否需要增長隊列。這個問題最終導致了調度程序的重寫。新調度程序的策略是對每個隊列使用固定大小。當隊列已滿時,任務將被推送到一個全局的、多使用者、多生產者隊列中,而不是增長本地隊列。處理器需要檢查這個全局隊列,但檢查的頻率要比本地隊列低得多。
早期實驗過用有界mpmc隊列代替了Crossbeam隊列。由于push和pop都執行了大量的同步,因此沒有帶來太大的提升。關于竊取任務,需要記住的一個關鍵點是,在有負載的時候隊列幾乎沒有爭用,因為每個處理器只訪問自己的隊列。
在這一點上,我仔細閱讀go源代碼,發現它使用了一個固定大小的單生產者、多消費者隊列。這個隊列令只需要很少的同步就可以正常工作。我對該算法進行了一些修改,使之適用于tokio調度程序。值得注意的是,go實現版本中其原子操作使用順序一致性(基于我對go的有限知識)。作為tokio調度器的一部分,該版本還降低了較冷代碼路徑中的一些復制。
該隊列實現是一個循環緩沖區,使用數組存儲值。原子整數用于跟蹤頭部和尾部位置。
struct Queue { /// Concurrently updated by many threads. head: AtomicU32, /// Only updated by producer thread but read by many threads. tail: AtomicU32, /// Masks the head / tail position value to obtain the index in the buffer. mask: usize, /// Stores the tasks. buffer: Box<[MaybeUninit<Task>]>,}入隊由單獨線程完成:
loop { let head = self.head.load(Acquire); // safety: this is the **only** thread that updates this cell. let tail = self.tail.unsync_load; if tail.wrapping_sub(head) < self.buffer.len as u32 { // Map the position to a slot index. let idx = tail as usize & self.mask; // Don't drop the previous value in `buffer[idx]` because // it is uninitialized memory. self.buffer[idx].as_mut_ptr.write(task); // Make the task available self.tail.store(tail.wrapping_add(1), Release); return; } // The local buffer is full. Push a batch of work to the global // queue. match self.push_overflow(task, head, tail, global) { Ok(_) => return, // Lost the race, try again Err(v) => task = v, }}請注意,在此push函數中,唯一的原子操作是使用Acquire順序的load和具有Release順序的store。沒有讀-修改-寫操作(compare_and_swap,fetch_and等)或順序一致性。因為在x86芯片上,所有load/store 已經是“原子的”。因此,在CPU級別,此功能不是同步的。使用原子操作會影響編譯器,因為它會阻止某些優化,但也僅此而已。第一個load很可能可以通過Relaxed順序完成,但是切換成Relaxed順序沒有明顯的收益。
隊列已滿時,將調用push_overflow。此功能將本地隊列中的一半任務移到全局隊列中。全局隊列是由互斥鎖保護的侵入鏈表。首先將要移動到全局隊列中的任務鏈接在一起,然后獲取互斥鎖,并通過更新全局隊列的尾指針來寫入所有任務。
如果您熟悉原子內存操作的細節,您可能會注意到上圖所示的push函數可能會產生“問題”。使用Acquire順序的原子load同步語義非常弱。它可能會返回老值(并發竊取操作可能已經增加了self.head的值),但是執行入隊的線程會讀到線程中的老值。這對于算法的正確性不是問題。在入隊的代碼路徑中,我們只關心本地運行隊列是否已滿。鑒于當前線程是可以執行入隊操作的唯一線程,則老值將使隊列比實際更滿。它可能會錯誤地認為隊列已滿并進入push_overflow函數,但是此函數包括更強的原子操作。如果push_overflow確定隊列實際上未滿,則返回w / Err并再次嘗試push操作。這是push_overflow將一半運行隊列移至全局隊列的另一個原因。通過移動一半的隊列,“運行隊列為空”的誤報率就會降低。
本地出對消息也很輕量級:
loop { let head = self.head.load(Acquire); // safety: this is the **only** thread that updates this cell. let tail = self.tail.unsync_load; if head == tail { // queue is empty return None; } // Map the head position to a slot index. let idx = head as usize & self.mask; let task = self.buffer[idx].as_ptr.read; // Attempt to claim the task read above. let actual = self .head .compare_and_swap(head, head.wrapping_add(1), Release); if actual == head { return Some(task.assume_init); }}在此函數中,存在單個原子load和一個帶有release的compare_and_swap。主要開銷來自compare_and_swap。
竊取功能類似于出隊,但是self.tail的load必須是原子的。同樣,類似于push_overflow,竊取操作將嘗試竊取隊列的一半,而不是單個任務。這這是不錯的特性,我們將在后面介紹。
最后一部分是全局隊列。該隊列用于處理本地隊列的溢出,以及從非處理器線程向調度程序提交任務。如果處理器有負載,即本地隊列中有任務。在從本地隊列執行約60個任務后,處理器將嘗試從全局隊列獲取任務。當處于“搜索”狀態時,它還會檢查全局隊列,如下所述。
優化消息傳遞模式
用Tokio編寫的應用程序通常以許多小的獨立任務為模型。這些任務將使用消息相互通信。這種模式類似于Go和Erlang等其他語言。考慮到這種模式的普遍性,調度程序嘗試對其進行優化是有意義的。
給定任務A和任務B。任務A當前正在執行,并通過channel向任務B發送消息。通道是任務B當前阻塞在channel上,因此發送消息將導致任務B轉換為可運行狀態,并被入隊到當前處理器的運行隊列中。然后,處理器將從運行隊列中彈出下一個任務,執行該任務,然后重復執行直到完成任務B。
問題在于,從發送消息到執行任務B的時間之間可能會有很大的延遲。此外,“熱”數據(例如消息)在發送時已存儲在CPU高速緩存中,但是到任務B被調度時,有可能已經從高速緩存中清理掉了。
為了解決這個問題,新的Tokio調度程序實現了特定優化(也可以在Go和Kotlin的調度程序中找到)。當任務轉換為可運行狀態時,它存儲在“下一個任務”槽中,而不是將其入隊到隊列的后面。在檢查運行隊列之前,處理器將始終檢查該槽。將任務插入此槽時,如果任務已存儲在其中,則舊任務將從槽中移除,并入隊到隊列的后面。在消息傳遞的情況下,這將保證消息的接收者會被立馬調度。
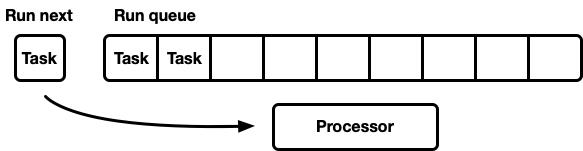
任務竊取
在竊取任務調度器中,當處理器的運行隊列為空時,處理器將嘗試從同級處理器中竊取任務。隨機選擇同級處理器,然后對該同級處理器執行竊取操作。如果未找到任務,則嘗試下一個同級處理器,依此類推,直到找到任務。
實際上,許多處理器通常在大約同一時間完成其運行隊列的處理。當一批任務到達時(例如,輪詢epoll以確保socket就緒時),就會發生這種情況。處理器被喚醒,獲取并運行任務。這導致所有處理器同時嘗試竊取,意味著多線程試圖訪問相同的隊列。這會引起爭用。隨機選擇初始節點有助于減少爭用,但是仍然很糟糕。
新的調度程序會限制并發執行竊取操作的處理器的數量。我們將試圖竊取的處理器狀態稱為“正在搜索任務”,或簡稱為“正在搜索”狀態。通過使用原子計數保證處理器在開始搜索之前遞增以及在退出搜索狀態時遞減來控制并發數量。搜索程序的最大數量是處理器總數的一半。雖然限制相當草率,但依然可以工作。我們對搜索程序的數量沒有硬性限制,只需要節流即可,以精度來換取算法效率。
處于正在搜索狀態后,處理器將嘗試從同級任務線程中竊取任務并檢查全局隊列。
減少跨線程同步
任務竊取調度程序的另一個關鍵部分是同級通知。這是處理器在觀察新任務時通知同級的地方。如果其他處理器正處于休眠狀態,則被喚醒并竊取任務。通知還有另一個重要責任。回顧使用弱原子順序(獲取/發布)的隊列算法。由于原子內存順序的工作原理,而無需額外的同步,因此無法保證同級處理器將知道隊列中的任務被竊取。因此通知動作還負責為同級處理器建立必要的同步,以使其知道任務以竊取任務。這些要求使得通知操作代價高昂。我們的目標是在保證CPU利用率的情況下,盡可能少地執行通知操作。通知太多會導致驚群問題。
老版本的Tokio調度程序采用了樸素的通知方式。每當將新任務推送到運行隊列時,就會通知處理器。每當該處理器并在喚醒時找到任務,它便會通知另一個處理器。這種邏輯會導致所有處理器都被喚醒從而引起爭用。通常這些處理器中的大多數都找不到任務,然后重新進入休眠。
通過使用Go調度器中類似的技術,新調度器有顯著改進。新調度器在相同的地方進行執行,然而僅在沒有處于搜索狀態的worker時才進行通知。通知worker后,其立即轉換為搜索狀態。當處于搜索狀態的處理器找到新任務時,它會首先退出搜索狀態,然后通知下一個處理器。
這種方法用于限制處理器喚醒的速率。如果一次調度了一批任務(例如,在輪詢epoll以確保套接字就緒時),則處理器會收到第一個任務的通知,然后處于搜索狀態。該處理器不會收到批處理中的其余任務的通知。負責通知的處理程序將竊取批處理中的一半任務,然后通知另一個處理器。第三個處理器將被喚醒,從前兩個處理器中查找任務,然后竊取其中一半。這樣處理器負載會平滑上升,任務也會達到快速負載平衡。
減少內存分配
新的Tokio調度程序對每個任務只需要分配一次內存,而舊的調度程序則需要分配兩次內存。以前,Task結構如下:
struct Task { /// All state needed to manage the task state: TaskState, /// The logic to run is represented as a future trait object. future: Box<dyn Future<Output = >>,}然后,Task結構也將被置于Box中。自從舊的Tokio調度程序發布以來,發生了兩件事。首先,std :: alloc穩定了。其次,Future任務系統切換到顯式的vtable策略。有了這兩個條件,我們就可以減少一次內存分配。
現在,任務表示為:
struct Task<T> { header: Header, future: T, trailer: Trailer,}Header和Trailer都是執行任務所需的狀態,狀態被劃分為“熱”數據(header)和“冷”數據(trailer),即,經常訪問的數據和很少使用的數據。熱數據放置在結構的頭部,并保持盡可能小。當CPU取消引用任務時,它將一次性加載高速緩存行大小的數據量(介于64和128字節之間)。我們希望該數據盡可能有價值。
減少原子引用計數
最后一個優化在于新的調度程序如何減少原子引用計數。任務結構有許多未完成的引用:調度程序和每個喚醒程序都擁有一個句柄。管理此內存的方法是使用原子引用計數。此策略需要在每次克隆引用時進行一次原子操作,并在每次刪除引用時進行一次相反的原子操作。當最終引用次數為0時,將釋放內存。
在舊的Tokio調度程序中,每個喚醒器都有一個對任務句柄的引用計數:
struct Waker { task: Arc<Task>,} impl Waker { fn wake(&self) { let task = self.task.clone; task.scheduler.schedule(task); }}喚醒任務后,將調用task 的clone方法(原子增量)。然后將引用置入運行隊列。當處理器執行完任務時,它將刪除引用,從而導致引用計數的原子遞減。這些原子操作雖然代價很低但是積少成多。
std :: future任務系統的設計人員已經確定了此問題。據觀察,當調用Waker :: wake時,通常不再需要原來的waker引用。這樣可以在將任務推入運行隊列時重用原子計數。現在,std :: future任務系統包括兩個“喚醒” API:
wake帶self參數
wake_by_ref帶&self參數。
這種API設計迫使調用者使用wake方法來避免原子增量。現在的實現變為:
impl Waker { fn wake(self) { task.scheduler.schedule(self.task); } fn wake_by_ref(&self) { let task = self.task.clone; task.scheduler.schedule(task); }}這就避免了額外的引用計數的開銷,然而這僅僅在可以獲取所有權的時候可用。根據我的經驗,調用wake幾乎總是通過借用而非獲取引用。使用self進行喚醒可防止重用waker,在使用self時實現線程安全的喚醒也更加困難(其細節將留給另一個文章)。
新的調度程序端通過避免調用wake_by_ref中的clone來逐步解決問題,從而其和wake(self)一樣有效。通過使調度程序維護當前處于活動狀態(尚未完成)的所有任務的列表來完成此功能。此列表代表將任務推送到運行隊列所需的引用計數。
這種優化的困難之處在于,確保調度程序在任務結束前不會從其列表中刪除任何任務。如何進行管理的細節不在本文的討論范圍之內,有興趣可以參考源代碼。
使用Loom無畏并發
眾所周知,編寫正確的、并發安全的、無鎖的代碼不是一件容易事,而且正確性最為重要,特別是要盡力避免那些和內存分配相關的代碼缺陷。在此方面,新版調度器做了很多努力,包括大量的優化以及避免使用大部分 std 類型。
從測試角度來說,通常有幾種方法用來驗證并發代碼的正確性。一種是完全依賴用戶在其使用場景中驗證;另一種是依賴循環運行的各種粒度單元測試試圖捕捉那些非常小概率的極端情況的并發缺陷。這種情況下,循環運行多長時間合適就成了另一個問題,10分鐘或者10天?
上述情況在我們的工作中是無法接受的,我們希望交付并發布時感到十足的自信,對 Tokio 用戶而言,可靠性是最為重要的。
因此,我們便造了一個“新輪子”:Loom,它是一個用于測試并發代碼的工具。測試用例可以按照最樸實尋常的方式來設計和編寫,但當通過 Loom 來執行時,Loom 會運行多次用例,同時會置換(permute)在多線程環境下所有可能遇到的行為或結果,這個過程中 Loom 還會驗證內存訪問正確與否,以及內存分配和釋放的行為正確與否等等。
下面是調度器在 Loom 上一個真實的測試場景:
#[test]fn multi_spawn { loom::model(|| { let pool = ThreadPool::new; let c1 = Arc::new(AtomicUsize::new(0)); let (tx, rx) = oneshot::channel; let tx1 = Arc::new(Mutex::new(Some(tx))); // Spawn a task let c2 = c1.clone; let tx2 = tx1.clone; pool.spawn(async move { spawn(async move { if 1 == c1.fetch_add(1, Relaxed) { tx1.lock.unwrap.take.unwrap.send(); } }); }); // Spawn a second task pool.spawn(async move { spawn(async move { if 1 == c2.fetch_add(1, Relaxed) { tx2.lock.unwrap.take.unwrap.send(); } }); }); rx.recv; });}上述代碼中的 loom::model部分運行了成千上萬次,每次行為都會有細微的差別,比如線程切換的順序,以及每次原子操作時,Loom 會嘗試所有可能的行為(符合 C++ 11 中的內存模型規范)。前面我提到過,使用 Acquire進行原子的加載操作是非常弱(保證)的,可能返回舊(臟)值,Loom 會嘗試所有可能加載的值。
在調度器的日常開發測試中,Loom 發揮了非常重要的作用,幫助我們發現并確認了10多個其他測試手段(單元測試、手工測試、壓力測試)所遺漏的隱蔽缺陷。
有的讀者們可能會對前文提到的“對所有可能的結果或行為進行排列組合和置換”產生疑問。眾所周知,對可能行為的簡單排列組合就會導致階乘式的“爆炸”。當然目前有許多用于避免這類指數級爆炸的算法,Loom 中采用的核心算法是基于“動態子集縮減”算法(dynamic partial reduction)。該算法能夠動態“修剪”會導致一致執行結果的排列子集,但需要注意的是,即便如此,在狀態空間巨大時也一樣會導致修剪效率大幅降低。Loom 采用了有界動態子集縮減算法來限制搜索空間。
總而言之,Loom 極大地幫助了我們,使得我們更有信心地發布新版調度器。
測試結果
我們來具體看看新版 Tokio 調度器到底取得了多大的性能提升?
首先,在微基準測試中,新版調度器提升顯著。
老版本
test chained_spawn ... bench: 2,019,796 ns/iter (+/- 302,168) test ping_pong ... bench: 1,279,948 ns/iter (+/- 154,365) test spawn_many ... bench: 10,283,608 ns/iter (+/- 1,284,275) test yield_many ... bench: 21,450,748 ns/iter (+/- 1,201,337)
新版本
test chained_spawn ... bench: 168,854 ns/iter (+/- 8,339) test ping_pong ... bench: 562,659 ns/iter (+/- 34,410) test spawn_many ... bench: 7,320,737 ns/iter (+/- 264,620) test yield_many ... bench: 14,638,563 ns/iter (+/- 1,573,678)
測試內容包括:
chained_spawn測試會遞歸地不斷產生新的子任務。
ping_pong測試會分配一個一次性地(oneshot)通道,接著產生一個新的子任務,子任務在該通道上發送消息,原任務則接受消息。
spawn_many測試會產生出大量子任務,并注入給調度器。
yield_many 會測試一個喚醒自己的任務。
為了更接近真實世界的工作負載,我們再試試 Hyper 基準測試:
wrk -t1 -c50 -d10
老版本
Running 10s test @ http://127.0.0.1:3000 1 threads and 50 connections Thread Stats Avg Stdev Max +/- Stdev Latency 371.53us 99.05us 1.97ms 60.53% Req/Sec 114.61k 8.45k 133.85k 67.00% 1139307 requests in 10.00s, 95.61MB read Requests/sec: 113923.19 Transfer/sec: 9.56MB
新版本
Running 10s test @ http://127.0.0.1:3000 1 threads and 50 connections Thread Stats Avg Stdev Max +/- Stdev Latency 275.05us 69.81us 1.09ms 73.57% Req/Sec 153.17k 10.68k 171.51k 71.00% 1522671 requests in 10.00s, 127.79MB read Requests/sec: 152258.70 Transfer/sec: 12.78MB
目前 Hyper 基準測試已經比 TechEmpower 更有參考性,所以從結果來看,我們很興奮 Tokio 調度器已經可以沖擊這樣的性能排行榜。
另外一個令人印象深刻的結果是,Tonic,流行的 gRPC 客戶端/服務端框架,取得了超過10%的性能提升,這還是在 Tonic 本身沒有做特定優化的情況下!
感謝各位的閱讀,以上就是“Rust異步編程方式是什么”的內容了,經過本文的學習后,相信大家對Rust異步編程方式是什么這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





