溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“瀏覽器的工作原理是什么”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“瀏覽器的工作原理是什么”吧!
瀏覽器架構
在講瀏覽器架構之前,先理解兩個概念,進程和線程。
進程(process)是程序的一次執行過程,是一個動態概念,是程序在執行過程中分配和管理資源的基本單位,線程(thread)是CPU調度和分派的基本單位,它可與同屬一個進程的其他的線程共享進程所擁有的全部資源。
簡單的說呢,進程可以理解成正在執行的應用程序,而線程呢,可以理解成我們應用程序中的代碼的執行器。而他們的關系可想而知,線程是跑在進程里面的,一個進程里面可能有一個或者多個線程,而一個線程,只能隸屬于一個進程。
大家都知道,瀏覽器屬于一個應用程序,而應用程序的一次執行,可以理解為計算機啟動了一個進程,進程啟動后,CPU會給該進程分配相應的內存空間,當我們的進程得到了內存之后,就可以使用線程進行資源調度,進而完成我們應用程序的功能。
而在應用程序中,為了滿足功能的需要,啟動的進程會創建另外的新的進程來處理其他任務,這些創建出來的新的進程擁有全新的獨立的內存空間,不能與原來的進程內向內存,如果這些進程之間需要通信,可以通過IPC機制(Inter Process Communication)來進行。
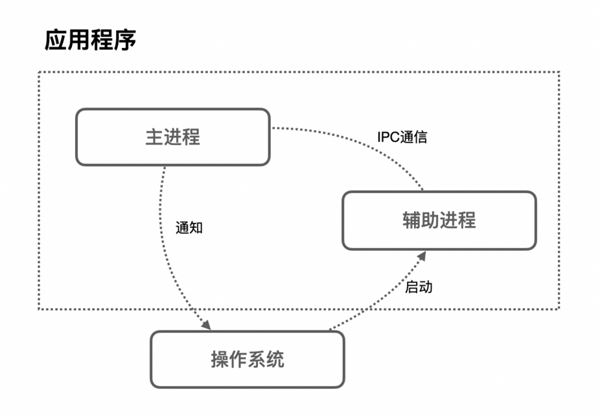
很多應用程序都會采取這種多進程的方式來工作,因為進程和進程之間是互相獨立的它們互不影響,也就是說,當其中一個進程掛掉了之后,不會影響到其他進程的執行,只需要重啟掛掉的進程就可以恢復運行。
瀏覽器的多進程架構
假如我們去開發一個瀏覽器,它的架構可以是一個單進程多線程的應用程序,也可以是一個使用IPC通信的多進程應用程序。
不同的瀏覽器使用不同的架構,下面主要以Chrome為例,介紹瀏覽器的多進程架構。
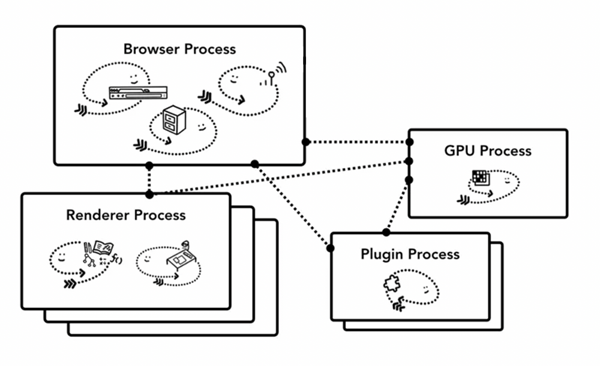
在Chrome中,主要的進程有4個:
瀏覽器進程 (Browser Process):負責瀏覽器的TAB的前進、后退、地址欄、書簽欄的工作和處理瀏覽器的一些不可見的底層操作,比如網絡請求和文件訪問。
渲染進程 (Renderer Process):負責一個Tab內的顯示相關的工作,也稱渲染引擎。
插件進程 (Plugin Process):負責控制網頁使用到的插件
GPU進程 (GPU Process):負責處理整個應用程序的GPU任務

這4個進程之間的關系是什么呢?
首先,當我們是要瀏覽一個網頁,我們會在瀏覽器的地址欄里輸入URL,這個時候Browser Process會向這個URL發送請求,獲取這個URL的HTML內容,然后將HTML交給Renderer Process,Renderer Process解析HTML內容,解析遇到需要請求網絡的資源又返回來交給Browser Process進行加載,同時通知Browser Process,需要Plugin Process加載插件資源,執行插件代碼。解析完成后,Renderer Process計算得到圖像幀,并將這些圖像幀交給GPU Process,GPU Process將其轉化為圖像顯示屏幕。
多進程架構的好處
Chrome為什么要使用多進程架構呢?
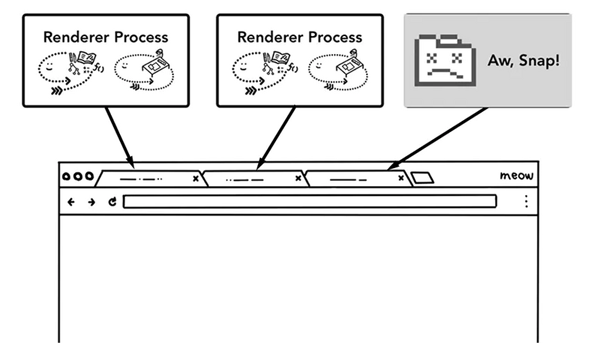
第一,更高的容錯性。當今WEB應用中,HTML,JavaScript和CSS日益復雜,這些跑在渲染引擎的代碼,頻繁的出現BUG,而有些BUG會直接導致渲染引擎崩潰,多進程架構使得每一個渲染引擎運行在各自的進程中,相互之間不受影響,也就是說,當其中一個頁面崩潰掛掉之后,其他頁面還可以正常的運行不收影響。
第二,更高的安全性和沙盒性(sanboxing)。渲染引擎會經常性的在網絡上遇到不可信、甚至是惡意的代碼,它們會利用這些漏洞在你的電腦上安裝惡意的軟件,針對這一問題,瀏覽器對不同進程限制了不同的權限,并為其提供沙盒運行環境,使其更安全更可靠
第三,更高的響應速度。在單進程的架構中,各個任務相互競爭搶奪CPU資源,使得瀏覽器響應速度變慢,而多進程架構正好規避了這一缺點。
多進程架構優化
之前的我們說到,Renderer Process的作用是負責一個Tab內的顯示相關的工作,這就意味著,一個Tab,就會有一個Renderer Process,這些進程之間的內存無法進行共享,而不同進程的內存常常需要包含相同的內容。
瀏覽器的進程模式
為了節省內存,Chrome提供了四種進程模式(Process Models),不同的進程模式會對 tab 進程做不同的處理。
Process-per-site-instance (default) - 同一個 site-instance 使用一個進程
Process-per-site - 同一個 site 使用一個進程
Process-per-tab - 每個 tab 使用一個進程
Single process - 所有 tab 共用一個進程
這里需要給出 site 和 site-instance 的定義
site 指的是相同的 registered domain name(如: google.com ,bbc.co.uk)和scheme (如:https://)。比如a.baidu.com和b.baidu.com就可以理解為同一個 site(注意這里要和 Same-origin policy 區分開來,同源策略還涉及到子域名和端口)。
site-instance 指的是一組 connected pages from the same site,這里 connected 的定義是 can obtain references to each other in script code 怎么理解這段話呢。滿足下面兩中情況并且打開的新頁面和舊頁面屬于上面定義的同一個 site,就屬于同一個 site-instance
用戶通過<a target="_blank">這種方式點擊打開的新頁面
JS代碼打開的新頁面(比如 window.open)
理解了概念之后,下面解釋四個進程模式
首先是Single process,顧名思義,單進程模式,所有tab都會使用同一個進程。接下來是Process-per-tab ,也是顧名思義,每打開一個tab,會新建一個進程。而對于Process-per-site,當你打開 a.baidu.com 頁面,在打開 b.baidu.com 的頁面,這兩個頁面的tab使用的是共一個進程,因為這兩個頁面的site相同,而如此一來,如果其中一個tab崩潰了,而另一個tab也會崩潰。
Process-per-site-instance 是最重要的,因為這個是 Chrome 默認使用的模式,也就是幾乎所有的用戶都在用的模式。當你打開一個 tab 訪問 a.baidu.com ,然后再打開一個 tab 訪問 b.baidu.com,這兩個 tab 會使用兩個進程。而如果你在 a.baidu.com 中,通過JS代碼打開了 b.baidu.com 頁面,這兩個 tab 會使用同一個進程。
默認模式選擇
那么為什么瀏覽器使用Process-per-site-instance作為默認的進程模式呢?
Process-per-site-instance兼容了性能與易用性,是一個比較中庸通用的模式。
相較于 Process-per-tab,能夠少開很多進程,就意味著更少的內存占用
相較于 Process-per-site,能夠更好的隔離相同域名下毫無關聯的 tab,更加安全
導航過程都發生了什么
前面我們講了瀏覽器的多進程架構,講了多進程架構的各種好處,和Chrome是怎么優化多進程架構的,下面從用戶瀏覽網頁這一簡單的場景,來深入了解進程和線程是如何呈現我們的網站頁面的。
網頁加載過程
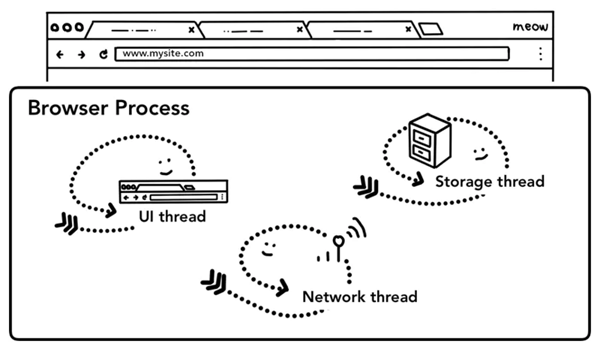
之前我們我們提到,tab以外的大部分工作由瀏覽器進程Browser Process負責,針對工作的不同,Browser Process 劃分出不同的工作線程:
UI thread:控制瀏覽器上的按鈕及輸入框;
network thread:處理網絡請求,從網上獲取數據;
storage thread: 控制文件等的訪問;
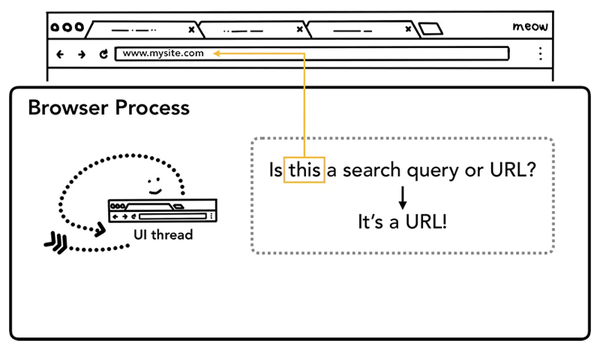
第一步:處理輸入
當我們在瀏覽器的地址欄輸入內容按下回車時,UI thread會判斷輸入的內容是搜索關鍵詞(search query)還是URL,如果是搜索關鍵詞,跳轉至默認搜索引擎對應都搜索URL,如果輸入的內容是URL,則開始請求URL。
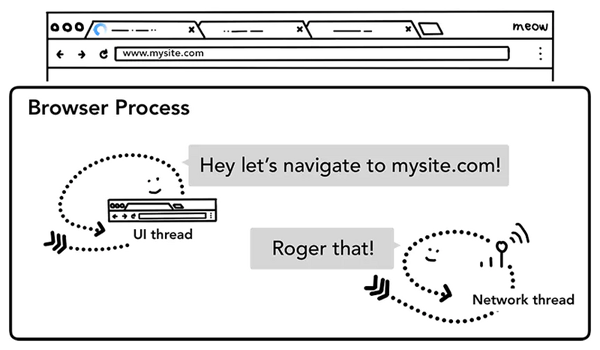
第二步:開始導航
回車按下后,UI thread將關鍵詞搜索對應的URL或輸入的URL交給網絡線程Network thread,此時UI線程使Tab前的圖標展示為加載中狀態,然后網絡進程進行一系列諸如DNS尋址,建立TLS連接等操作進行資源請求,如果收到服務器的301重定向響應,它就會告知UI線程進行重定向然后它會再次發起一個新的網絡請求。
第三步:讀取響應
network thread接收到服務器的響應后,開始解析HTTP響應報文,然后根據響應頭中的Content-Type字段來確定響應主體的媒體類型(MIME Type),如果媒體類型是一個HTML文件,則將響應數據交給渲染進程(renderer process)來進行下一步的工作,如果是 zip 文件或者其它文件,會把相關數據傳輸給下載管理器。
與此同時,瀏覽器會進行 Safe Browsing 安全檢查,如果域名或者請求內容匹配到已知的惡意站點,network thread 會展示一個警告頁。除此之外,網絡線程還會做 CORB(Cross Origin Read Blocking)檢查來確定那些敏感的跨站數據不會被發送至渲染進程。
第四步:查找渲染進程
各種檢查完畢以后,network thread 確信瀏覽器可以導航到請求網頁,network thread 會通知 UI thread 數據已經準備好,UI thread 會查找到一個 renderer process 進行網頁的渲染。
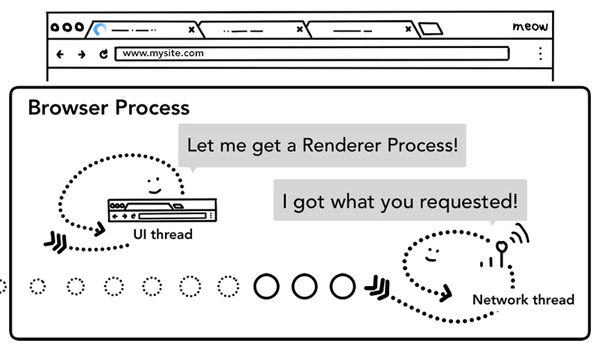
瀏覽器為了對查找渲染進程這一步驟進行優化,考慮到網絡請求獲取響應需要時間,所以在第二步開始,瀏覽器已經預先查找和啟動了一個渲染進程,如果中間步驟一切順利,當 network thread 接收到數據時,渲染進程已經準備好了,但是如果遇到重定向,這個準備好的渲染進程也許就不可用了,這個時候會重新啟動一個渲染進程。
第五步:提交導航
到了這一步,數據和渲染進程都準備好了,Browser Process 會向 Renderer Process 發送IPC消息來確認導航,此時,瀏覽器進程將準備好的數據發送給渲染進程,渲染進程接收到數據之后,又發送IPC消息給瀏覽器進程,告訴瀏覽器進程導航已經提交了,頁面開始加載。
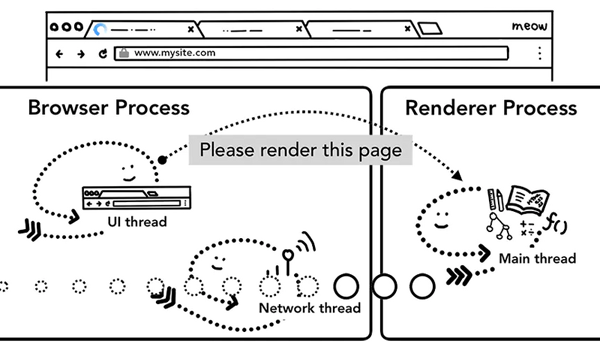
這個時候導航欄會更新,安全指示符更新(地址前面的小鎖),訪問歷史列表(history tab)更新,即可以通過前進后退來切換該頁面。
第六步:初始化加載完成
當導航提交完成后,渲染進程開始加載資源及渲染頁面(詳細內容下文介紹),當頁面渲染完成后(頁面及內部的iframe都觸發了onload事件),會向瀏覽器進程發送IPC消息,告知瀏覽器進程,這個時候UI thread會停止展示tab中的加載中圖標。
網頁渲染原理
導航過程完成之后,瀏覽器進程把數據交給了渲染進程,渲染進程負責tab內的所有事情,核心目的就是將HTML/CSS/JS代碼,轉化為用戶可進行交互的web頁面。那么渲染進程是如何工作的呢?
渲染進程中,包含線程分別是:
一個主線程(main thread)
多個工作線程(work thread)
一個合成器線程(compositor thread)
多個光柵化線程(raster thread)
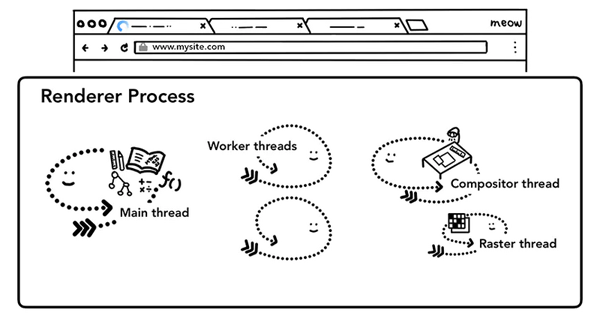
不同的線程,有著不同的工作職責。
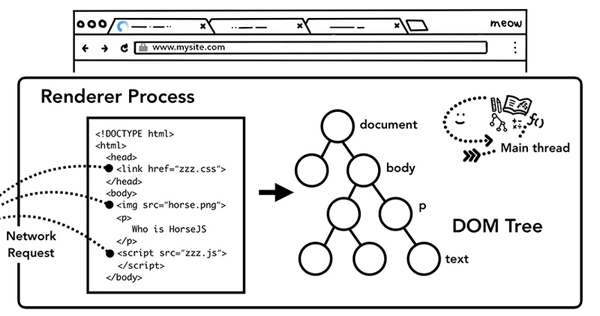
構建DOM
當渲染進程接受到導航的確認信息后,開始接受來自瀏覽器進程的數據,這個時候,主線程會解析數據轉化為DOM(Document Object Model)對象。
DOM為WEB開發人員通過JavaScript與網頁進行交互的數據結構及API。
資源子加載
在構建DOM的過程中,會解析到圖片、CSS、JavaScript腳本等資源,這些資源是需要從網絡或者緩存中獲取的,主線程在構建DOM過程中如果遇到了這些資源,逐一發起請求去獲取,而為了提升效率,瀏覽器也會運行預加載掃描(preload scanner)程序,如果如果HTML中存在img、link等標簽,預加載掃描程序會把這些請求傳遞給Browser Process的network thread進行資源下載。
JavaScript的下載與執行
構建DOM過程中,如果遇到<script>標簽,渲染引擎會停止對HTML的解析,而去加載執行JS代碼,原因在于JS代碼可能會改變DOM的結構(比如執行document.write()等API)
不過開發者其實也有多種方式來告知瀏覽器應對如何應對某個資源,比如說如果在<script> 標簽上添加了 async 或 defer 等屬性,瀏覽器會異步的加載和執行JS代碼,而不會阻塞渲染。
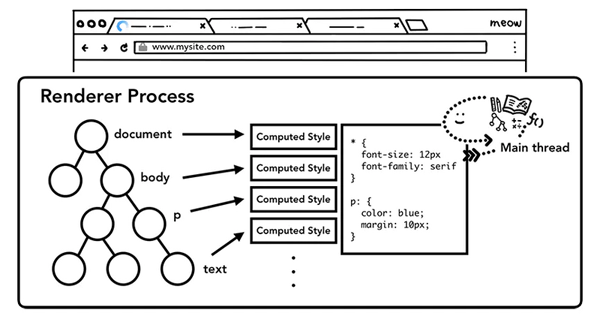
樣式計算 - Style calculation
DOM樹只是我們頁面的結構,我們要知道頁面長什么樣子,我們還需要知道DOM的每一個節點的樣式。主線程在解析頁面時,遇到<style>標簽或者<link>標簽的CSS資源,會加載CSS代碼,根據CSS代碼確定每個DOM節點的計算樣式(computed style)。
計算樣式是主線程根據CSS樣式選擇器(CSS selectors)計算出的每個DOM元素應該具備的具體樣式,即使你的頁面沒有設置任何自定義的樣式,瀏覽器也會提供其默認的樣式。
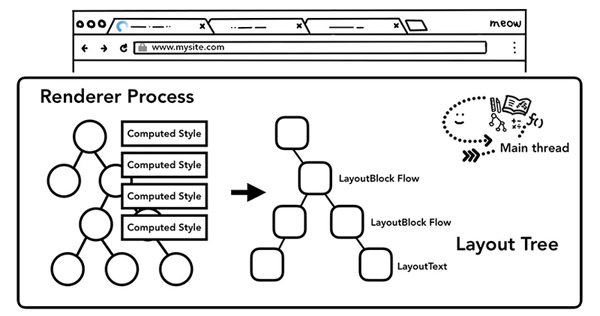
布局 - Layout
DOM樹和計算樣式完成后,我們還需要知道每一個節點在頁面上的位置,布局(Layout)其實就是找到所有元素的幾何關系的過程。
主線程會遍歷DOM 及相關元素的計算樣式,構建出包含每個元素的頁面坐標信息及盒子模型大小的布局樹(Render Tree),遍歷過程中,會跳過隱藏的元素(display: none),另外,偽元素雖然在DOM上不可見,但是在布局樹上是可見的。
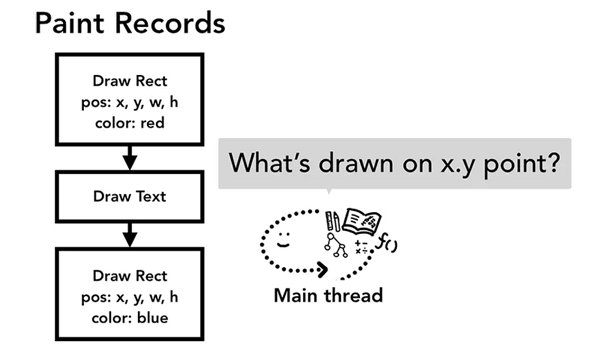
繪制 - Paint
布局 layout 之后,我們知道了不同元素的結構,樣式,幾何關系,我們要繪制出一個頁面,我們要需要知道每個元素的繪制先后順序,在繪制階段,主線程會遍歷布局樹(layout tree),生成一系列的繪畫記錄(paint records)。繪畫記錄可以看做是記錄各元素繪制先后順序的筆記。
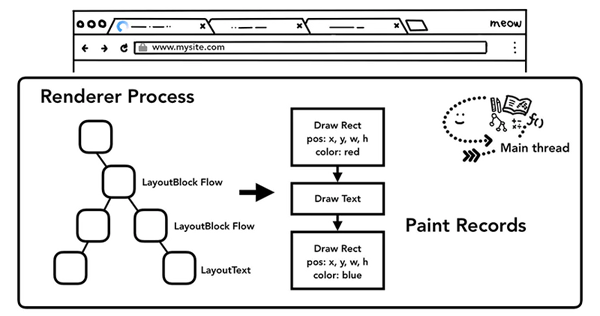
合成 - Compositing
文檔結構、元素的樣式、元素的幾何關系、繪畫順序,這些信息我們都有了,這個時候如果要繪制一個頁面,我們需要做的是把這些信息轉化為顯示器中的像素,這個轉化的過程,叫做光柵化(rasterizing)。
那我們要繪制一個頁面,最簡單的做法是只光柵化視口內(viewport)的網頁內容,如果用戶進行了頁面滾動,就移動光柵幀(rastered frame)并且光柵化更多的內容以補上頁面缺失的部分,如下:
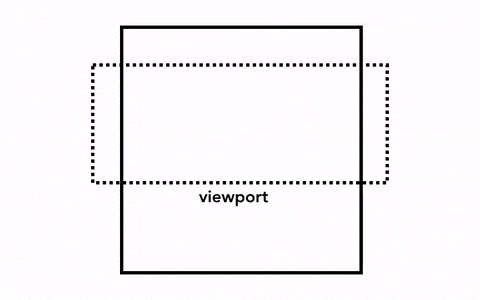
最簡單的光柵化過程
Chrome第一個版本就是采用這種簡單的繪制方式,這一方式唯一的缺點就是每當頁面滾動,光柵線程都需要對新移進視圖的內容進行光柵化,這是一定的性能損耗,為了優化這種情況,Chrome采取一種更加復雜的叫做合成(compositing)的做法。
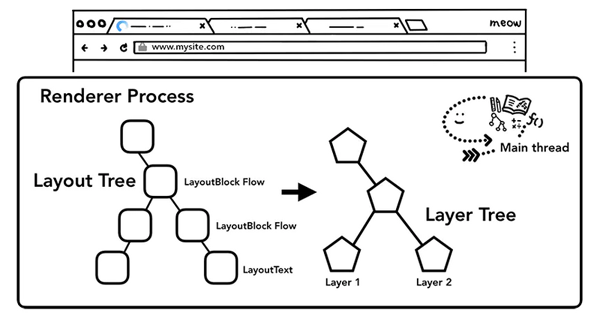
那么,什么是合成?合成是一種將頁面分成若干層,然后分別對它們進行光柵化,最后在一個單獨的線程 - 合成線程(compositor thread)里面合并成一個頁面的技術。當用戶滾動頁面時,由于頁面各個層都已經被光柵化了,瀏覽器需要做的只是合成一個新的幀來展示滾動后的效果罷了。頁面的動畫效果實現也是類似,將頁面上的層進行移動并構建出一個新的幀即可。

為了實現合成技術,我們需要對元素進行分層,確定哪些元素需要放置在哪一層,主線程需要遍歷渲染樹來創建一棵層次樹(Layer Tree),對于添加了 will-change CSS 屬性的元素,會被看做單獨的一層,沒有 will-change CSS屬性的元素,瀏覽器會根據情況決定是否要把該元素放在單獨的層。
你可能會想要給頁面上所有的元素一個單獨的層,然而當頁面的層超過一定的數量后,層的合成操作要比在每個幀中光柵化頁面的一小部分還要慢,因此衡量你應用的渲染性能是十分重要的一件事情。
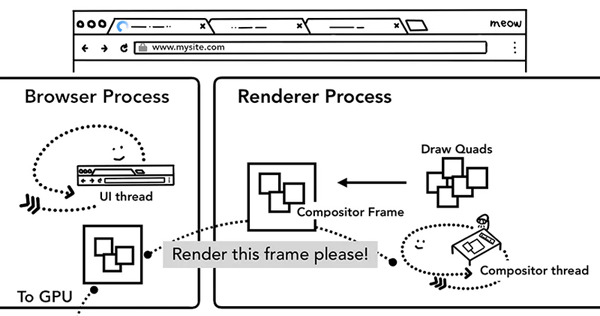
一旦Layer Tress被創建,渲染順序被確定,主線程會把這些信息通知給合成器線程,合成器線程開始對層次數的每一層進行光柵化。有的層的可以達到整個頁面的大小,所以合成線程需要將它們切分為一塊又一塊的小圖塊(tiles),之后將這些小圖塊分別進行發送給一系列光柵線程(raster threads)進行光柵化,結束后光柵線程會將每個圖塊的光柵結果存在GPU Process的內存中。
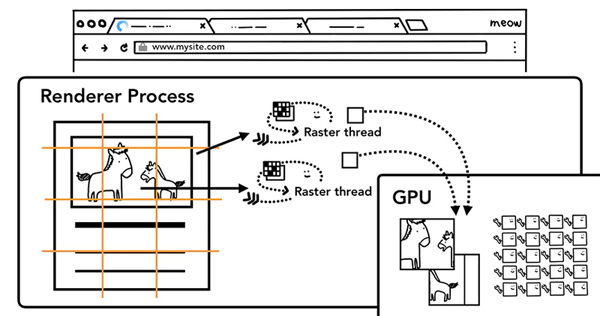
為了優化顯示體驗,合成線程可以給不同的光柵線程賦予不同的優先級,將那些在視口中的或者視口附近的層先被光柵化。
當圖層上面的圖塊都被柵格化后,合成線程會收集圖塊上面叫做繪畫四邊形(draw quads)的信息來構建一個合成幀(compositor frame)。
繪畫四邊形:包含圖塊在內存的位置以及圖層合成后圖塊在頁面的位置之類的信息。
合成幀:代表頁面一個幀的內容的繪制四邊形集合。
以上所有步驟完成后,合成線程就會通過IPC向瀏覽器進程(browser process)提交(commit)一個渲染幀。這個時候可能有另外一個合成幀被瀏覽器進程的UI線程(UI thread)提交以改變瀏覽器的UI。這些合成幀都會被發送給GPU從而展示在屏幕上。如果合成線程收到頁面滾動的事件,合成線程會構建另外一個合成幀發送給GPU來更新頁面。
合成的好處在于這個過程沒有涉及到主線程,所以合成線程不需要等待樣式的計算以及JavaScript完成執行。這就是為什么rocks.com/en/tutorials/speed/high-performance-animations/" _fcksavedurl="https://www.html5rocks.com/en/tutorials/speed/high-performance-animations/">合成器相關的動畫最流暢,如果某個動畫涉及到布局或者繪制的調整,就會涉及到主線程的重新計算,自然會慢很多。
瀏覽器對事件的處理
當頁面渲染完畢以后,TAB內已經顯示出了可交互的WEB頁面,用戶可以進行移動鼠標、點擊頁面等操作了,而當這些事件發生時候,瀏覽器是如何處理這些事件的呢?
以點擊事件(click event)為例,讓鼠標點擊頁面時候,首先接受到事件信息的是Browser Process,但是Browser Process只知道事件發生的類型和發生的位置,具體怎么對這個點擊事件進行處理,還是由Tab內的Renderer Process進行的。Browser Process接受到事件后,隨后便把事件的信息傳遞給了渲染進程,渲染進程會找到根據事件發生的坐標,找到目標對象(target),并且運行這個目標對象的點擊事件綁定的監聽函數(listener)。
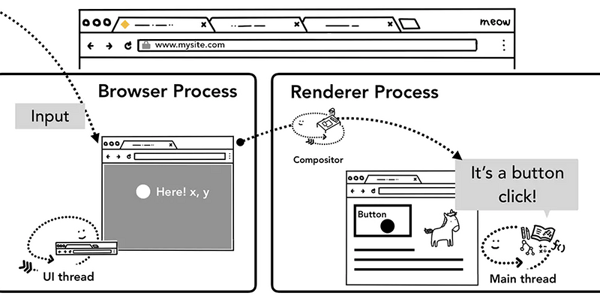
渲染進程中合成器線程接收事件
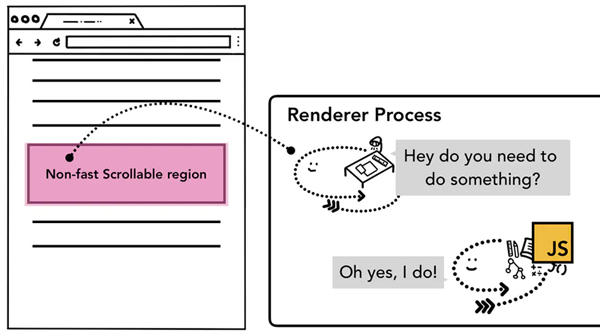
前面我們說到,合成器線程可以獨立于主線程之外通過已光柵化的層創建組合幀,例如頁面滾動,如果沒有對頁面滾動綁定相關的事件,組合器線程可以獨立于主線程創建組合幀,如果頁面綁定了頁面滾動事件,合成器線程會等待主線程進行事件處理后才會創建組合幀。那么,合成器線程是如何判斷出這個事件是否需要路由給主線程處理的呢?
由于執行 JS 是主線程的工作,當頁面合成時,合成器線程會標記頁面中綁定有事件處理器的區域為非快速滾動區域(non-fast scrollable region),如果事件發生在這些存在標注的區域,合成器線程會把事件信息發送給主線程,等待主線程進行事件處理,如果事件不是發生在這些區域,合成器線程則會直接合成新的幀而不用等到主線程的響應。
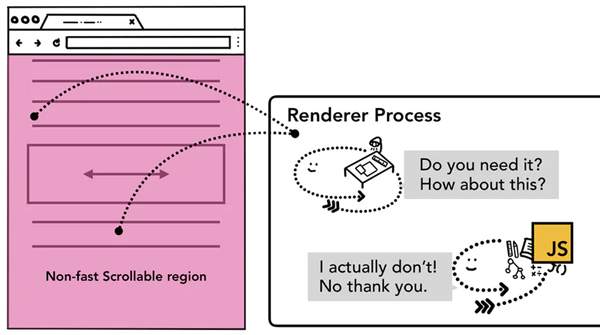
而對于非快速滾動區域的標記,開發者需要注意全局事件的綁定,比如我們使用事件委托,將目標元素的事件交給根元素body進行處理,代碼如下:
document.body.addEventListener('touchstart', event => { if (event.target === area) { event.preventDefault() } })在開發者角度看,這一段代碼沒什么問題,但是從瀏覽器角度看,這一段代碼給body元素綁定了事件監聽器,也就意味著整個頁面都被編輯為一個非快速滾動區域,這會使得即使你的頁面的某些區域沒有綁定任何事件,每次用戶觸發事件時,合成器線程也需要和主線程通信并等待反饋,流暢的合成器獨立處理合成幀的模式就失效了。
其實這種情況也很好處理,只需要在事件監聽時傳遞passtive參數為 true,passtive會告訴瀏覽器你既要綁定事件,又要讓組合器線程直接跳過主線程的事件處理直接合成創建組合幀。
document.body.addEventListener('touchstart', ?event => { if (event.target === area) { event.preventDefault() } }, {passive: true});查找事件的目標對象(event target)
當合成器線程接收到事件信息,判定到事件發生不在非快速滾動區域后,合成器線程會向主線程發送這個時間信息,主線程獲取到事件信息的第一件事就是通過命中測試(hit test)去找到事件的目標對象。具體的命中測試流程是遍歷在繪制階段生成的繪畫記錄(paint records)來找到包含了事件發生坐標上的元素對象。
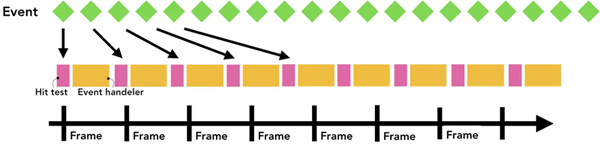
瀏覽器對事件的優化
一般我們屏幕的幀率是每秒60幀,也就是60fps,但是某些事件觸發的頻率超過了這個數值,比如wheel,mousewheel,mousemove,pointermove,touchmove,這些連續性的事件一般每秒會觸發60~120次,假如每一次觸發事件都將事件發送到主線程處理,由于屏幕的刷新速率相對來說較低,這樣使得主線程會觸發過量的命中測試以及JS代碼,使得性能有了沒必要是損耗。
出于優化的目的,瀏覽器會合并這些連續的事件,延遲到下一幀渲染是執行,也就是requestAnimationFrame之前。
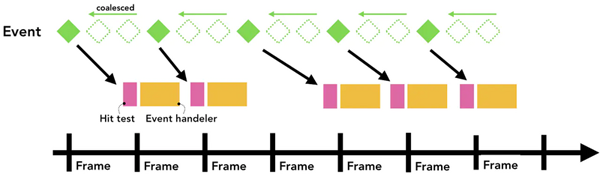
和之前相同的事件軸,可是這次事件被合并并延遲調度了
而對于非連續性的事件,如keydown,keyup,mousedown,mouseup,touchstart,touchend等,會直接派發給主線程去執行。
到此,相信大家對“瀏覽器的工作原理是什么”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





