溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹做API 監控有沒有什么方法,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
前言
針對 API 的管理,非常重要的一點就是做 API 監控。前段時間看了 Nginx 社區發布的一本關于 API 流量管理的書,感覺書中的內容還不錯,結合我在實際應用中的經驗,今天就來梳理一下 API 的監控的一些方法。
看了原文書感覺國外這些技術人在做事之前還是很有條理的,另外最近在也在讀一本社區管理的書,其中他們就把社區研究的層次分為了 3 層:框架(Frameworks),理論(Theories),模型(Models)。下面簡單解釋一下,感覺這個方法論非常實用,我感覺在很多地方都可以使用。
框架是說大方向,明確各個部分的關系,讓大家能在這個框架之下達成共識;
理論是比框架更明確的一個概念,它是在框架之下對每個模塊或者子模塊的進一步細化,或者是處理具體事情的技術或者原理性的解釋以及指導;
模型是更為具體的,解決特定事件的解釋和指導。研究人員使用模型來測試基于理論的各種假設,模型可以使用多種工具開發,包括數學、統計技術等。
這是一個做事情的框架體系,大家在思考和處理事情的應該也是有這樣一個模式的。
所以今天我在梳理 API 監控方面的內容的時候也想按照這樣一個基本思路來。
API 管理的基本框架
在 API 的管理上我是認為有幾個方面的:
API 的基本開發管理(API設計,接口元信息,調用管理,測試,限流,路由管理等等)
API 的基本監控(流量,耗時,錯誤碼,可用性監控等等)
API 的安全管控(STL,鑒權,證書等等)
API 的高級特性(可擴展性,緩存,伸縮,性能分析,流量放大分析等等)
從 API 的基本開發管理和到高級的功能分層進行管理,從基本可用到安全可控。API 的基本設計也是一個非常復雜的事情,要做好一個 API 的設計也不是那么容易的,這部分我后面也打算寫一個系列來介紹一下。今天的重點是是 API 的基本監控。
API 監控級別
API 監控同樣也是符合上面的理論,也是有一個理論框架的。對于 API 的監控首先是分級別的,這是為了監控的實施,很多事情分層之后就會很清晰,無論在理解上和該怎么實施上都會很清晰。那看看對于 API 監控是怎么分級的。
基礎設施監控
服務級別監控
業務級別監控
基礎設施監控
這里我們主要關注的是硬件cpu,磁盤,內存等的可靠性,還有比如操作系統,隊列服務等組件的可靠性。上篇文章也介紹過如何快速分析定位系統中的這些問題。這些是服務運行穩定的基礎,所以對這些設施的監控是一個通用的做法,這個不是只有在 API 監控中才有的,但是如果要做完整的 API 監控,最后一部分當然是不可缺少的。
服務級別的監控
在服務級別的監控中,主要關注的是服務組件是不是健康可靠的,比如監控數據的讀寫,文件創建,服務的基本存活,服務調用延遲,服務的性能等等。
業務級別監控
最后是業務級別的監控,不同的應用場景和業務,對于監控的內容也是不一樣的。比如你要監控購買的量,監控登陸用戶,消息發送的條數,收到的禮物數,走過的路線等等,不同的業務場景需要監控的指標是不一樣的,這部分非常特性。
API 監控常見的監控指標
雖然上面說的第三個級別的監控是有很多特性,但是對于監控的內容來說他們還是有一些共性的。所以這里給大家列一些常用的監控指標類型。
速率
速率是一個常用的監控指標,數據的發送速率,增加速率,訪問速率,調用速率等等,這個指標旨在監控你的系統的服務能力。一般來說這個指標越大,服務能力越強。
請求延時
這個指標很多時候和上面的速率這個指標是有關系的,一般來說這個這個數值越小,說明你的服務性能越好。這個指標一般可以在 API 網關上進行采集或者是在客戶端采集。
錯誤率
對系統錯誤的監控對一個系統來至關重要,還有對不同錯誤碼的統計計數,有了對這些個指標的監控,系統的可用性監控就有了。
如果單純的只看前面兩個指標也是有問題的,因為有時候在系統故障的時候系統的訪問速率和請求延時會表現的很好,但是實際上是有很多錯誤請求和錯誤返回,比如系統的快速錯誤返回,大量錯誤的請求等。
配額突發過載
這種也是要監控的一個點,很多時候有瞬時過載的情況,這也是暴露了系統的一些潛在問題。
指標平均值
對于系統的穩定性、服務能力以及服務特點的監控這個是有必要的,很多時候不但要看當前狀態值,還要進一步看服務指標最近 5 分鐘、 10 分鐘、15 分鐘等的平均值。
API 監控常見的監控模型
上面都是鋪墊了,這部分其實才是我今天主要想分享的的內容,我感覺這部分內容才是比較有意思的。我上面列舉了那么多指標類型,每個類型在實際實施的時候又會派生出很多指標,那么問題就來了,我們在分析系統問題的時候是所有的指標都要看嗎?這個估計很難,那怎么做呢?
說起這個問題讓我想到股市中的一種做法:指數。提到這里大家如果了解所謂的指數,應該就知道我要說什么了,股票指數他可以通過對股市中的一些圈定的股票指標用特別的算法,計算出來一個值來表示股市的好壞。比如美國有納斯達克綜合指數,中國有上證指數和深成指數。
所以我這里介紹的這個所謂的監控模型也是類似的想法,但是這個模型是目前其它公司或者組織已經梳理好的,不是我的原創哈。
USE 模型
這里介紹第一種模型:USE (Utilization, Saturation, and Errors),這個模型最早是由 Brendan Gregg 大神提出來的,目前在 Netflix 公司,大名鼎鼎的《BPF Performance Tools》這本書的作者,1300 多頁的大部頭。他提到他提出這種模型就是為了讓大家可以快速的定位問題解決問題,而不用陷入細節而不知所措。
Gregg 說通過問 3 個問題就應該可以對你的系統可以有非常好的理解了:利用率如何?飽和度如何?錯誤或者錯誤率如何?
Utilization 利用率是指對系統諸如 CPU,磁盤,I/O 等的利用情況如何,是否空閑。
Saturation 飽和度是系統等待處理的業務或者請求程度,表示是否超過了目前系統的最大承受能力。
Errors 錯誤或者錯誤率這個也比較好理解,就是系統在處理這些業務或者請求的時候出現的錯誤事件。
關于這個模型更為詳細的解釋可以去他的個人網站了解:http://www.brendangregg.com/usemethod.html。
實際上也是這樣的,我在前面一篇翻譯的文章中介紹如何定位 Linux 系統的問題,其實大部分的方法思路都是這樣的。
或許你說這個和 API 監控有什么關系?Gregg 最早提出的目標確實是針對系統的指標分析,但是實際上這套方法模型應用在系統線程分析,網絡請求分析也是可以的。但是從根本來說它還是主要針對基礎設施的監控模型。
RED 模型
RED (Requests, Errors, and Duration),這個模型是由 Tom Wilkie 在 2015 的時候提出來的,它是對 USE 模型的一種升級,USE 模型在單機模型中會比較好用,但是在目前的分布式環境,微服務環境下,其實很難快速的來定位問題了,所以 RED 模型在針對復雜系統的健康評估的時候就比較有用了,可以看到使用的指標并不是很多,也是像上面的靈魂三問一樣:你的系統請求量多大?錯誤或者錯誤率有多少?耗時多大?
這里對這三個指標就不多解釋了,實際上大家在平時對 API 接口的考察估計也差不多會用到這些指標,但是我估計很多人從來沒有想過通過指標來構建一種模型,從而反映系統的的整體穩定性和可靠性。而且尤其對于微服務來說這個模型還是非常不錯的。
可以看出來這就是對應上面的服務級別監控。RED 模型是正對系統的整體可用性進行的一種評估方式。通過對系統請求的完整監控(從請求開始到返回的整個過程),并且從中抽取 3 個關鍵指標,來評估系統的可用性。RED 模型一般是在 API 網關這一層來使用,在這一層就可以對服務進行監控了。
LETS 模型
LETS (Latency, Errors, Traffic, and Saturation),整個模型是 Google 在 2003 年提出的,其實這個模型是 Google 提出他們的 SRE 的時候提出來的一個模型,這 4 個指標在 SRE 這本書中被稱之為 “The Four Golden Signals”。書中說如果你只能關注 4 個指標,那就關注這 4 個:延遲,錯誤,流量和飽和度。
“If you can only measure four metrics, focus on these four: Latency, Errors, Traffic, and Saturation.”
這個模型用最小關注指標集,提供了對系統可用性的評估。通過這 4 個指標的關注你就會發現系統中的大多數問題。它不像 USE 一樣比較底層,它是一個針對服務可用性的監控分析模型。
總結
做事情還是得有一定的方法論來指導的,今天這里總結的這篇文章目的就在于對 API 的監控方面進行梳理,梳理出了 API 監控的基本層次,常用指標和常見的監控模型。
對于 API 的監控模型來說,這里也要說明一下,不同的監控模型關注的問題點不同,或者說關注的監控層次不同。而且在實際的團隊中這塊的工作一般是會分為幾個組織來共同完成的。不同的團隊關注點會不一樣,所以可以針對具體的關注點可以選擇不同的模型。
另外要說的是,對于 API 的監控,雖然上面提到的層次、指標和模型都是前人總結的。但是時代在發展,技術在進步,大家在實際場景中使用的時候應該一方面選擇合適可用的,另一方面應該也可以想一想,可選的模型是否適應現在的場景,如果不適應又沒有更好的選擇的時候是不是自己可以抽象開發出一個針對自己場景的模型。讓定制的模型可以準確的反映自己系統的狀態。
一圖勝千言:
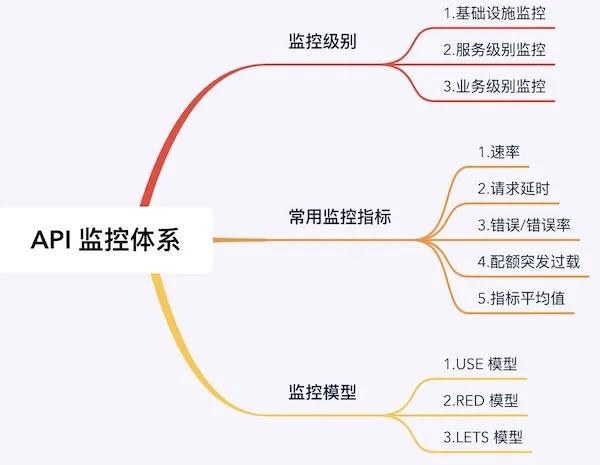
關于做API 監控有沒有什么方法就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





