溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何用Python做一份旅游攻略,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
旅游是調節心情的有效途徑,越來越多的上班族和學生期待利用假期時間外出游 玩來開拓眼界、舒緩壓力。然而真正有了假期,許多人卻會因“去哪玩”的問題倍感困惑,六月份正是出行的好時節,就讓我們一起來學習如何利用python來安排自己的出行計劃吧。
一.數據的獲取
最近幾年,既省錢又休閑的自助游逐漸成為年輕人出行的最愛,這里推薦一個我個人比較喜歡的旅游網站螞蜂窩,這次通過分析“驢友”們的出行計劃來規劃我們自己的行程,第一步當然是爬取網站數據啦
1.分析目標網頁
為了獲取大家的出行信息,我們進入網站的“結伴”板塊,查看“一個月以內”的出行計劃,可以看到隨著頁面的更改url并沒有發生變化,初步判斷該網頁是通過js加載的,要想爬取首先得找到真實url和返回的數據格式。
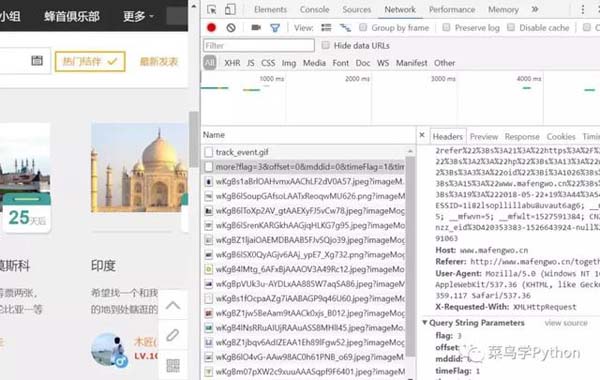
經過一番嘗試,我們成功找到了請求返回的真實url和關鍵參數,這里返回的是json格式的數據,里面包含了一個html文本。
2.確定抓取內容
在正式開始爬取數據之前,我們要先確定需要爬取哪些數據。行程的列表頁清晰地展現了目的地、行程簡介、發起人ID和性別(呵呵),雖然這些信息非常有參考價值,但是如果能獲取更多信息無疑會對我們的行程規劃更有幫助,所以還是要進入詳情頁來看一看。
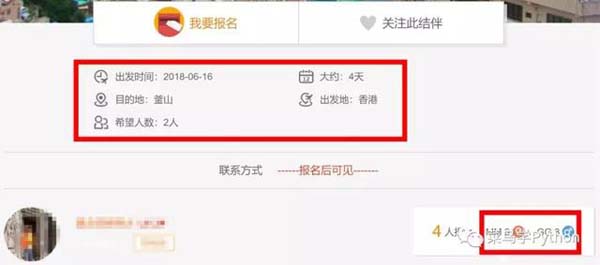
可以看到,詳情頁中對出發時間、行程歷時、出發地點等都有詳細說明,此外還有報名結伴人員情況,這項數據能在很大程度上反映小伙伴們的出行意向,所以一定要拿下來。
3.正式爬取數據
總體思路是爬取索引頁中每一個行程的發起人和詳情頁url,之后進入詳情頁抓取出發時間、歷史、目的地、出發城市、希望人數以及報名人員情況等數據,每個行程的索引頁數據和詳情頁數據合 并后作為該行程的完整數據進行存儲。以下是爬蟲程序的總入口:
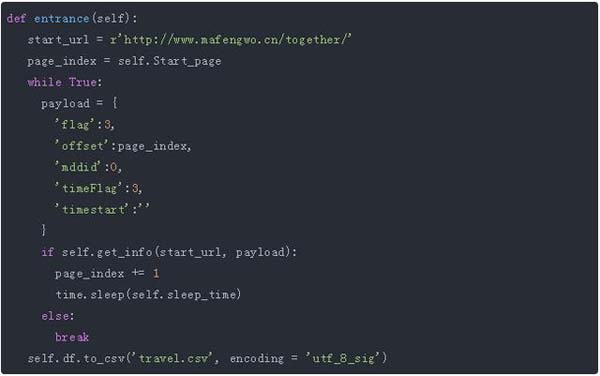
payload參數:flag決定了行程的排序方式,可選值為1、2、3,分別代表“即將出發”、“***發布”、“熱門結 伴”;
offset表示當前頁數,默認從0開始;middid表示行程目的地,不確定目的地值為0;timeFlage代表出 發時間,值為3表示選取一個月內的行程。
get_info()方法:抓取每一頁的行程信息并翻頁,如果無法獲取有效信息則說明爬取結束。
數據存儲:由于數據量不大,可以先全部存儲到一個dataframe數據結構中,再一次性寫入csv文件。
二. 數據清洗
我們來看看獲取到的數據是什么樣子的,可以看到,每條數據中都有很多干擾信息:
“出發時間”一欄我們想要 的僅僅是日期數據;
“報名人數”一欄我們想要的僅僅是數字,而不需要多余的修飾文字等等;
“部分出行” 計劃涵蓋了多個目的地,這對我們的旅游目的地分析是非常不利的

所以,我們必須先對獲取到的數據進行清洗, 以期為正式的數據分析奠定基礎。
1.規范格式
首先對歷時、希望人數、報名人數(女)、報名人數(男)這幾項數據進行清洗,僅保留數字部分;其次對出發是 按、出發地點相關數據進行情況,取到“:”及前面的內容。感謝pandas.Series.str方法,使我們可以非常簡單地完 成上述工作,功能函數如下:

only_num(self, col_list):去除數據中的非數字部分。
no_colon(self, col_list):去除數據中的“:”及其前面的內容。
2.拆分目的地
剛才說到過,一個行程中包含多個目的地會對我們的分析造成干擾,這里的解決思路是對目的地數據進行拆分。
將一列數據拆分成X列(X為該行程包含的目的地個數),同樣是使用pandas.Series.str方法,代碼如下:

三.數據分析
現在我們可以對數據進行分析查找六月份的旅行規律了,為了便于觀察,這里使用pyecharts進行可視化處理。
1.男女比例
首先對參與出行計劃的人員性別進行分析,利用dataframe的sum()和groupby().count()方法可以很容易獲得行程 發布者和參與者的性別分布:
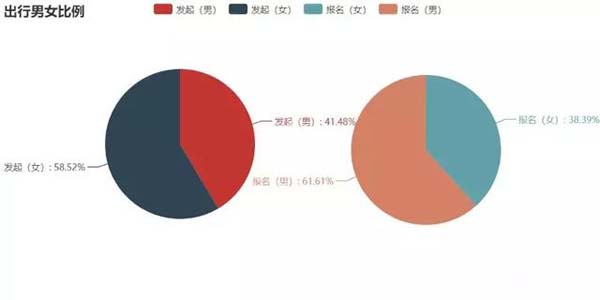
從圖中可以看出,發起人以女性居多,約占總數的60%,而參與者剛好相反,男性比 例約為60%,估計是女同胞們更擅長精心策劃行程,而男同胞們大多比較“懶”吧~
2.出發時間
這里我們首先用dataframen的groupby()方法,以“出行時間”為關鍵字對數據進行分組,分別統計每天的行程數量 和參與者數量,然后畫出折線圖。
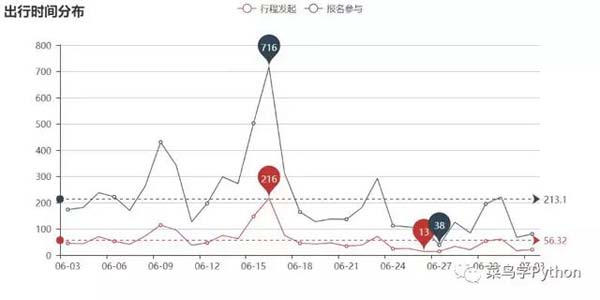
從結果來看,6月15、16兩天是六月份出行的高峰期(這個時間剛好開始端午節假期),端午節有出行計劃的朋友 們記得提前準備哈。除此之外的幾個波峰也都出現在周末,看來喜歡自助游的朋友中還是上班族(也可能是大學 生)居多啊。
3.目的地選擇
先來分析行程發布數據,首先將數據中所有的目的地加入到一個list中(包含重復數據),然后使用collections中的Counter()方法統計每個目的地出現的頻次,***制圖。

圖中列出了頻次較高的幾個目的地,彩條越長表示出現的頻次越多。稍微留意下我們會發現,大家比較青睞的都是一些商業化程度比較低的地區,比如拉薩,新疆!
其實作為一名自由行愛好者,我同樣比較喜歡更加原始和純粹的風光,對于沉淀心情確實會起到更好的效果,大家如果有出行計劃又不知道去哪玩的話,不妨從上面的目的地中選一下。

4.參與者情況如何
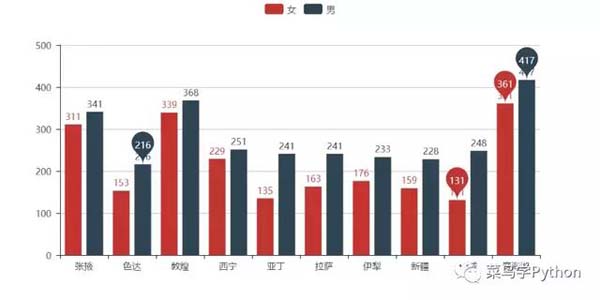
首先分別統計出各個目的地報名的男性數量和女性數量儲存到兩個dict中,分別取參與 人數最多的10個目的地,***將兩組數據合并、去重......
然后我們會驚奇地發現,雖然兩個序列中具體排名不盡相 同,但是男性和女性最想去的10個目的地居然完全一致。
不過各個地點的男女人數還是有較大差異的,如果想來一場***的邂逅,或許下面這張圖會有點幫助哈。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





