溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“學習Python過程中該注重哪些細節”,在日常操作中,相信很多人在學習Python過程中該注重哪些細節問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”學習Python過程中該注重哪些細節”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
01、只要一行代碼的列表生成器
假如每次你想要生成個列表,都要寫個循環,是不是很煩呢?好在 Python 已經有一個內建方法,只要一行代碼就能搞定這個問題。如果你不熟悉這個語法,可能理解起來會有點難度,不過一旦你習慣這個技術之后,你一定會愛不釋手的!
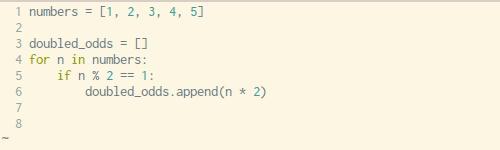
動圖:如何將一個循環改成列表生成式(來源:Trey Hunner )
上面這個動圖就是一個很好的例子,原來的代碼就是采用 for 循環生成列表的方法,而圖上一步一步將它改造成了一個只有一行代碼的列表生成式,再也不用循環啦。是不是很簡潔?
下面是另外一個對比范例:
使用循環:
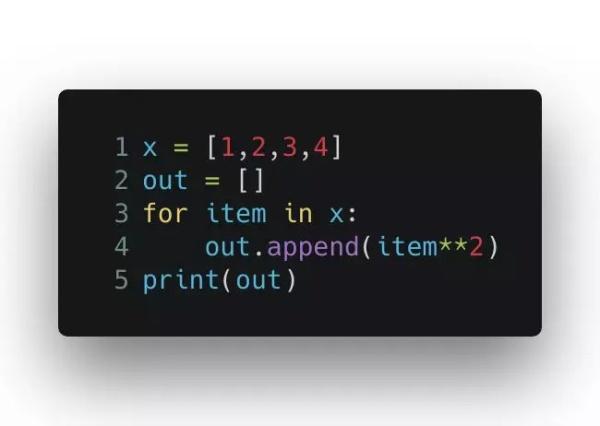
輸出的結果是 [1, 4, 9, 16]
使用生成式:
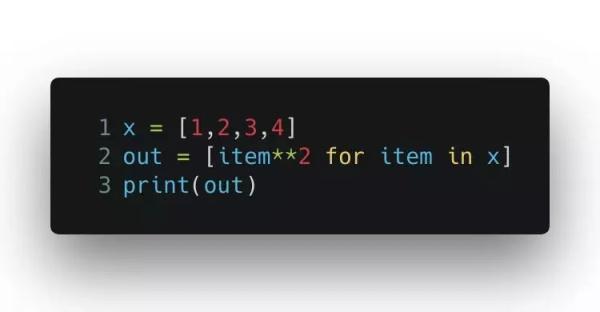
輸出的結果也是 [1, 4, 9, 16]
02、Lambda 表達式
明明這個函數用不了幾次,每次都要寫一大串函數構建代碼,是不是很累?別怕,Lambda 表達式來救你!Lambda 表達式能方便地創造簡單、一次使用而且匿名的函數對象。基本上,它們讓你無需費心構造一個函數,而是直接使用這個函數。
Lambda 表達式的基本語法是:

歐剃漢化,
要記住,Lambda 表達式創造的函數和普通的 def 構建的函數沒什么不同,只不過函數體只有單獨一個表達式而已。看看下面這個例子:
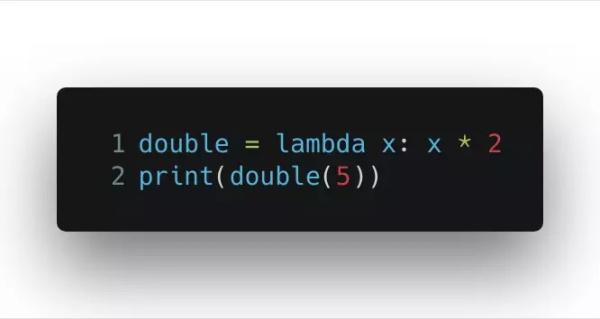
輸出的結果是 10
03、Map 和 Filter 函數
一旦你掌握了 Lambda 表達式,將它們與 map 或 filter 函數一起使用,可謂是威力無比。
具體來說, map() 函數接收一個列表,和一個函數,它對列表里的每個元素調用一個函數進行處理,再將結果放進一個新列表里。下面這個例子中,map() 函數遍歷 seq 中的每個元素,把它乘2,再把結果放入一個新列表,***返回這個列表。最外面一層 list() 函數是把 map() 返回的對象轉換成列表格式。
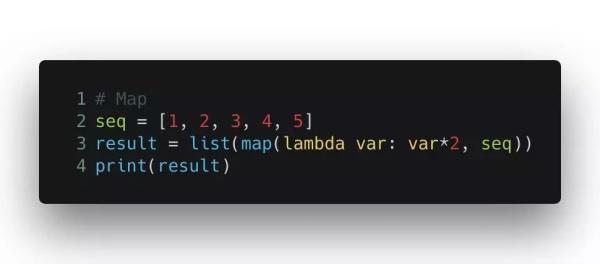
輸出的結果是 [2, 4, 6, 8, 10]
而 filter() 函數略有不同,它接收一個列表,和一個規則函數,在對列表里的每個元素調用這個規則函數之后,它把所有返回值為假的元素從列表中剔除,然后返回這個過濾后的子列表。
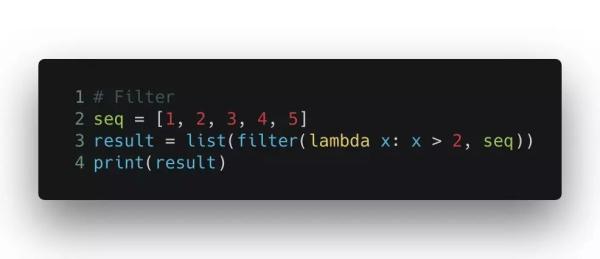
輸出的結果是 [3, 4, 5]
04、Arange 和 Linspace 函數
為了快速方便地生成 numpy 的數組,你一定得熟悉 arange() 和 linspace() 這兩個函數。這兩個函數分別有自己的特定用法,不過對我們來說,它們都能很好地生成 numpy 數組(而不是用 range() ),這在數據科學的分析工作上可是相當好用的。
arange() 函數按照指定的步長返回一個等差數列。除開始和結束值之外,你還可以自定義步長和數據類型。請注意,給定的結束值參數是不會被包含在結果內的。
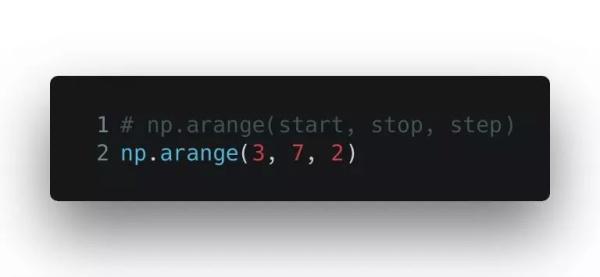
輸出的是一個數組對象: array([3, 5])
linspace() 函數的用法也很類似,不過有一點小小的不同。 linspace() 返回的是將給定區間進行若干等分以后的等分點組成的數列。所以你傳入的參數包括開始值、結束值,以及具體多少等分。linspace() 將這個區間進行等分后,把開始值、結束值和每個等分點都放進一個 NumPy 數組里。這在做數據可視化以及繪制坐標軸的時候都很有用。
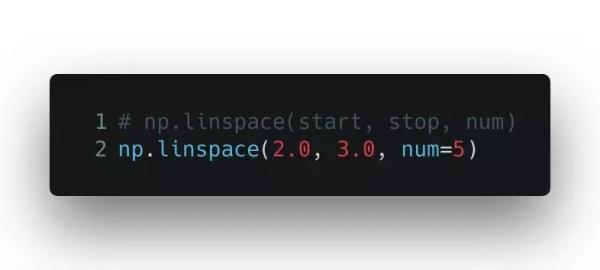
輸出的是一個數組對象: array([ 2.0, 2.25, 2.5, 2.75, 3.0])
05、Pandas 中坐標軸(axis 參數)的意義
在 Pandas 里要篩掉某一列,或是在 NumPy 矩陣里要對數據求和的時候,你可能已經遇到過這個 axis 參數的問題。如果你還沒見過,那提前了解一下也無妨。比如,對某個 Pandas 表這樣處理:
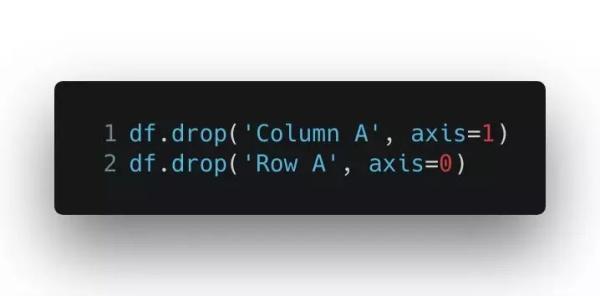
在我真正理解之前,我基本上每次要用到 drop 的時候,都得去重新查詢一下哪個 axis 的值對應的是哪個,多到我自己都數不清了。正如上面這個示例,你大概已經看出,如果要處理列,axis 要設成 1,如果處理行,axis 要設成 0,對吧。但這是為什么呢?我最喜歡的一個解釋(或者是我如何記住這一點的)是這樣的:

獲取 Pandas 數據表對象的 shape 屬性,你將獲得一個元組,元組的***個元素是數據表的行數,第二個元素是數據表的列數。想想 Python 里這兩個元素的下標吧,前面一個是 0,后面一個是 1,對不對?所以對于 axis 參數,0 就是前面的行數,1 就是后面的列數,怎么樣,好記吧?
06、用 Concat、Merge 和 Join 來合并數據表
如果你熟悉 SQL,這幾個概念對你來說就是小菜一碟。不過不管怎樣,這幾個函數從本質上來說不過就是合并多個數據表的不同方式而已。當然,要時刻記著什么情況下該用哪個函數也不是一件容易的事,所以,讓我們一起再回顧一下吧。
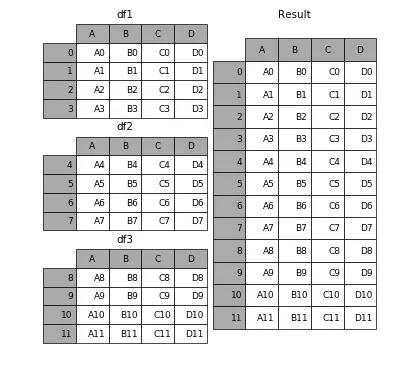
concat() 可以把一個或多個數據表按行(或列)的方向簡單堆疊起來(看你傳入的 axis 參數是 0 還是 1 咯)。
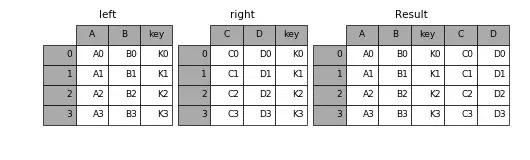
merge() 將會以用戶指定的某個名字相同的列為主鍵進行對齊,把兩個或多個數據表融合到一起。
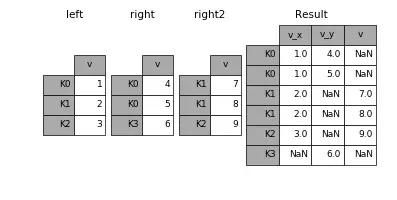
join()和 merge() 很相似,只不過 join() 是按數據表的索引進行對齊,而不是按某一個相同的列。當某個表缺少某個索引的時候,對應的值為空(NaN)。
有需要的話,你還可以查閱Pandas 官方文檔 ,了解更詳細的語法規則和應用實例,熟悉一些你可能會碰到的特殊情況。
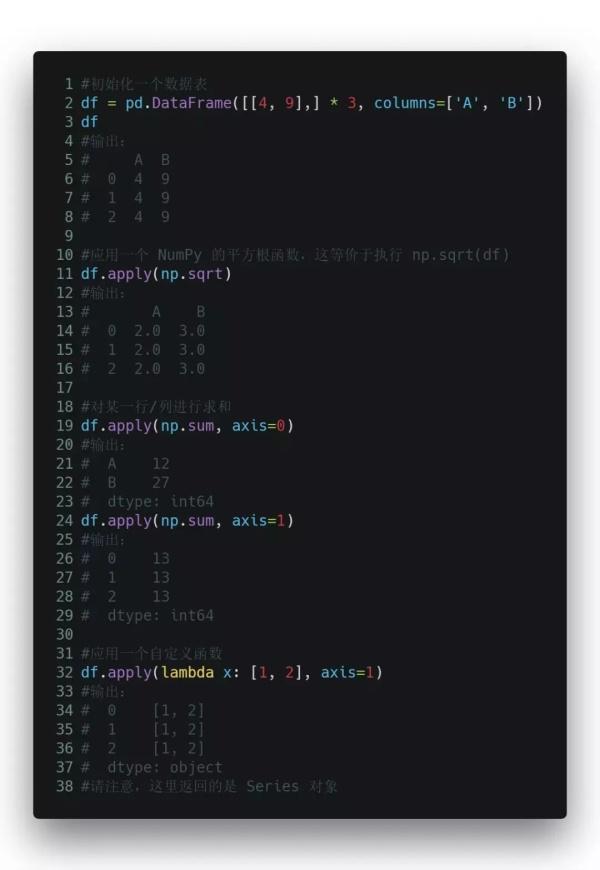
07、Apply 函數
你可以把 apply() 當作是一個 map() 函數,只不過這個函數是專為 Pandas 的數據表和 series 對象打造的。對初學者來說,你可以把 series 對象想象成類似 NumPy 里的數組對象。它是一個一維帶索引的數據表結構。
apply() 函數作用是,將一個函數應用到某個數據表中你指定的一行或一列中的每一個元素上。是不是很方便?特別是當你需要對某一列的所有元素都進行格式化或修改的時候,你就不用再一遍遍地循環啦!
這里就舉幾個簡單的例子,讓大家熟悉一下基本的語法規則:
08、數據透視表(Pivot Tables)
***也最重要的是數據透視表。如果你對微軟的 Excel 有一定了解的話,你大概也用過(或聽過)Excel 里的“數據透視表”功能。Pandas 里內建的 pivot_table() 函數的功能也差不多,它能幫你對一個數據表進行格式化,并輸出一個像 Excel 工作表一樣的表格。實際使用中,透視表將根據一個或多個鍵對數據進行分組統計,將函數傳入參數 aggfunc 中,數據將會按你指定的函數進行統計,并將結果分配到表格中。
下面是幾個 pivot_table() 的應用例子:

到此,關于“學習Python過程中該注重哪些細節”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





