溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“如何使用Python來處理數據集”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
Pandas對數據科學界來說是一份天賜的禮物。問任何一個數據科學家,他們喜歡如何使用Python處理他們的數據集,他們無疑會談到Pandas。
Pandas是一個偉大的編程庫的縮影:簡單、直觀、功能廣泛。
然而,對數據科學家的一項常規任務,使用Pandas進行數千甚至數百萬次的計算,仍然是一個挑戰。你不能只是將數據放入,編寫Python for循環,然后期望在合理的時間內處理數據。
Pandas是為一次性處理整個行或列的矢量化操作而設計的—循環遍歷每個單元格、行或列并不是這個庫的設計用途。因此,在使用Pandas時,你應該考慮到矩陣操作是高度并行化的。
本指南將教你如何使用Pandas的方式,它被設計用來使用矩陣運算。在此過程中,我將向你展示一些實用的節省時間的技巧和技巧,它們將使你的Pandas代碼運行得比那些可怕的Python for循環快得多!
設置
在本教程中,我們將使用經典的鳶尾花數據集。我們通過使用seaborn加載數據集并打印出前5行來開始。
現在讓我們建立一個基線,用Python for循環來測量我們的速度。我們將通過循環遍歷每一行來設置要在數據集上執行的計算,然后測量整個操作的速度。這將為我們提供一個基準,看看我們的新優化能在多大程度上幫助我們加速。
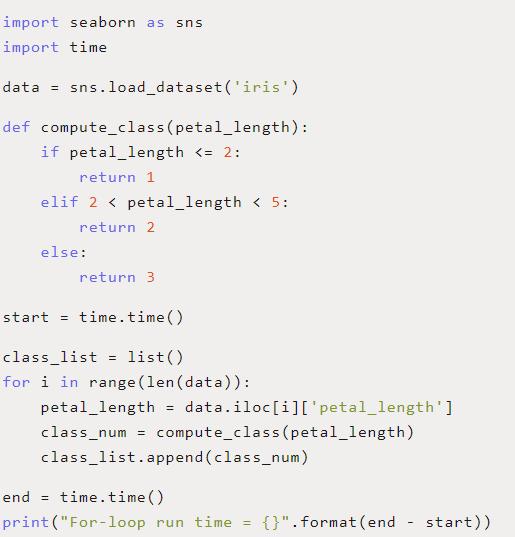
在上面的代碼中,我們創建了一個基本函數,它使用If-Else語句根據花瓣的長度選擇花的類。我們編寫了一個for循環,通過循環dataframe對每一行使用這個函數,然后測量循環的總運行時間。
在我的i7-8700k計算機上,循環運行5次平均需要0.01345秒。
使用.iterrows()來實現循環
我們可以立即做的最簡單但非常有價值的加速是使用Pandas的內置 .iterrows()函數。
在上一節中編寫for循環時,我們使用了 range()函數。然而,當我們在Python中對大范圍的值進行循環時,生成器往往要快得多。在本文中(https://towardsdatascience.com/5-advancedfeaturesof-python-and-how-use-them-73bffa373c84),你可以閱讀更多關于生成器如何工作的信息,并加快運行速度。
Pandas中的 .iterrows()函數在內部實現了一個生成器函數,它將在每次迭代中“生成”一行數據。更準確地說, .iterrows()為DataFrame中的每一行生成(index, Series) 的對(元組)。這實際上與在原始Python中使用類似于 enumerate()的東西是一樣的,但是運行速度要快得多。
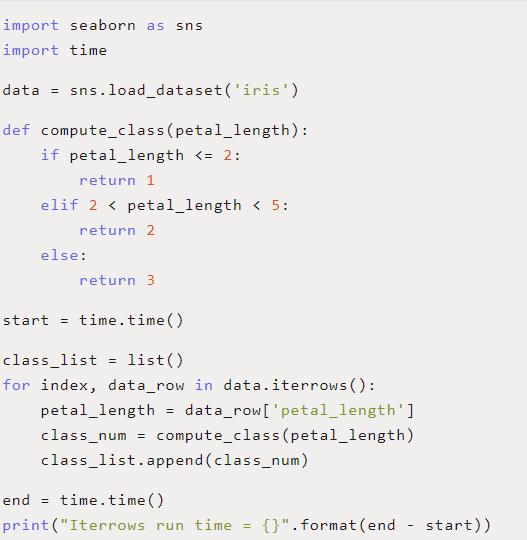
下面我們修改了代碼,使用 .iterrows()替常規的for循環。在我上一節測試所用的同一臺機器上,平均運行時間為0.005892秒—提高了2.28倍!
使用.apply()完全丟掉循環
.iterrows()函數極大地提高了速度,但還遠遠不夠。請始終記住,當使用為向量操作設計的庫時,可能有一種方法可以在完全沒有for循環的情況下很高效地完成任務。
提供這種功能的Pandas函數是 .apply()函數。我們的函數 .apply()接受另一個函數作為它的輸入,并沿著DataFrame的軸(行、列等)應用它。在傳遞函數的這種情況下,lambda通常可以方便地將所有內容打包在一起。
在下面的代碼中,我們已經完全用 .apply()和lambda函數替換了for循環來封裝我們想要的計算。在我的機器上,這段代碼的平均運行時間是0.0020897秒—比原來的for循環快6.44倍。

.apply()之所以要快得多,是因為它在內部嘗試遍歷Cython迭代器。如果你的函數恰好為Cython進行了很好的優化, .apply()將使你的速度更快。額外的好處是,使用內置函數可以生成更干凈、更可讀的代碼。
最后是使用cut
前面我提到過,如果你正在使用一個為向量化操作設計的庫,那么你應該始終尋找一種不使用for循環進行任何計算的方法。
類似地,許多以這種方式設計的庫,包括Pandas,都具有方便的內置函數,可以執行你正在尋找的精確計算—但是速度更快。
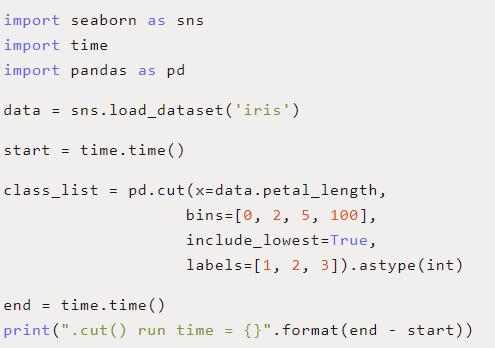
Pandas的 .cut()函數接受一組 bins為輸入,其中定義每個If-Else的范圍,以及一組 labels作為輸入,其中定義為每個范圍返回哪個值。然后,它執行與我們用 compute_class()函數手動編寫的操作完全相同的操作。
查看下面的代碼,看看 .cut()是如何工作的。我們又一次得到了更干凈、更可讀的代碼。最后, .cut()函數平均運行0.001423秒—比原來的for循環快了9.39倍!
“如何使用Python來處理數據集”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





