溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
最近搞了搞minist手寫數據集的神經網絡搭建,一個數據集里面很多個數據,不能一次喂入,所以需要分成一小塊一小塊喂入搭建好的網絡。
pytorch中有很方便的dataloader函數來方便我們進行批處理,做了簡單的例子,過程很簡單,就像把大象裝進冰箱里一共需要幾步?
第一步:打開冰箱門。
我們要創建torch能夠識別的數據集類型(pytorch中也有很多現成的數據集類型,以后再說)。
首先我們建立兩個向量X和Y,一個作為輸入的數據,一個作為正確的結果:

隨后我們需要把X和Y組成一個完整的數據集,并轉化為pytorch能識別的數據集類型:

我們來看一下這些數據的數據類型:

可以看出我們把X和Y通過Data.TensorDataset() 這個函數拼裝成了一個數據集,數據集的類型是【TensorDataset】。
好了,第一步結束了,冰箱門打開了。
第二步:把大象裝進去。
就是把上一步做成的數據集放入Data.DataLoader中,可以生成一個迭代器,從而我們可以方便的進行批處理。

DataLoader中也有很多其他參數:
好了,第二步結束了,大象裝進去了。
第三步:把冰箱門關上。
好啦,現在我們就可以愉快的用我們上面定義好的迭代器進行訓練啦。
在這里我們利用print來模擬我們的訓練過程,即我們在這里對搭建好的網絡進行喂入。

輸出的結果是:
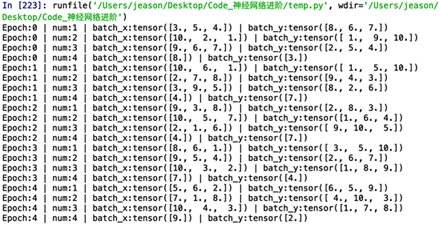
可以看到,我們一共訓練了所有的數據訓練了5次。數據中一共10組,我們設置的mini-batch是3,即每一次我們訓練網絡的時候喂入3組數據,到了最后一次我們只有1組數據了,比mini-batch小,我們就僅輸出這一個。
此外,還可以利用python中的enumerate(),是對所有可以迭代的數據類型(含有很多東西的list等等)進行取操作的函數,用法如下:

以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





