溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關如何用Python快速制作美觀炫酷且有深度的圖表,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
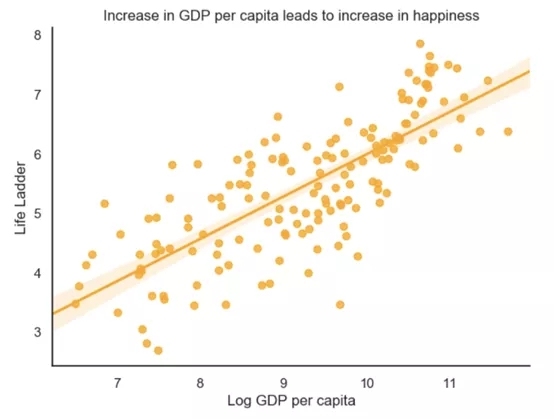
生活階梯(幸福指數)與人均GDP(金錢)正相關的正則圖
三種用Python可視化數據的不同方法。以可視化《2019年世界幸福報告》的數據為例,本文用Gapminder和Wikipedia的信息豐富了《世界幸福報告》數據,以探索新的數據關系和可視化方法。
《世界幸福報告》試圖回答世界范圍內影響幸福的因素。
報告根據對“坎特里爾階梯問題”的回答來確定幸福指數,被調查者需對自己的生活狀況進行打分,10分為最佳狀態,0分為最差。
將使用Life Ladder作為目標變量。Life Ladder就是指幸福指數。
文章結構

圖片來源:Nik MacMillan/Unsplash
本文旨在提供代碼指南和參考點,以便在查找特定類型的圖表時進行參考。為了節省空間,有時會將多個圖表合并到一張圖上。但是請放心,你可以在這個Repo或相應的Jupyter Notebook中找到所有基本代碼。
1. 我使用Python進行繪圖的經歷

大約兩年前,我開始更認真地學習Python。從那時起,Python幾乎每周都會給我一些驚喜,它不僅自身簡單易用,而且其生態系統中還有很多令人驚嘆的開源庫。我對命令、模式和概念越熟悉,就越能充分利用其功能。
(1) Matplotlib
與用Python繪圖正好相反。最初,我用matplotlib創建的幾乎每個圖表看起來都很過時。更糟糕的是,為了創建這些討厭的東西,我不得不在Stackoverflow上花費數小時。例如,研究改變x斜度的基本命令或者類似這些的蠢事。我一點也不想做多圖表。以編程的方式創建這些圖表是非常奇妙的,例如,一次生成50個不同變量的圖表,結果令人印象深刻。然而,其中涉及大量的工作,需要記住一大堆無用的指令。
(2) Seaborn
學習Seaborn能夠節省很多精力。Seaborn可以抽象出大量的微調。毫無疑問,這使得圖表在美觀上得到巨大的改善。然而,它也是構建在matplotlib之上的。通常,對于非標準的調整,仍然有必要使用機器級的matplotlib代碼。
(3) Bokeh
一時間,我以為Bokeh會成為一個后援解決方案。我在做地理空間可視化的時候發現了Bokeh。然而,我很快就意識到,雖然Bokeh有所不同,但還是和matplotlib一樣復雜。
(4) Plotly
不久前我確實嘗試過 plot.ly (后面就直接用plotly來表示)同樣用于地理空間可視化。那個時候,plotly比前面提到的庫還要麻煩。它必須通過筆記本賬戶登錄,然后plotly可以在線呈現,接著下載最終圖表。我很快就放棄了。但是,我最近看到了一個關于plotlyexpress和plotly4.0的Youtube視頻,重點是,他們把那些在線的廢話都刪掉了。我嘗試了一下,本篇文章就是嘗試的成果。我想,知道得晚總比不知道的好。
(5) Kepler.gl (地理空間數據優秀獎)
Kepler.gl不是一個Python庫,而是一款強大的基于web的地理空間數據可視化工具。只需要CSV文件,就可以使用Python輕松地創建文件。試試吧!
(6) 當前工作流程
最后,我決定使用Pandas本地繪圖進行快速檢查,并使用Seaborn繪制要在報告和演示中使用的圖表(視覺效果很重要)。
2. 分布的重要性

我在圣地亞哥從事研究期間,負責教授統計學(Stats119)。Stats119是統計學的入門課程,包括統計的基礎知識,如數據聚合(可視化和定量)、概率的概念、回歸、抽樣、以及最重要的分布。這一次,我對數量和現象的理解幾乎完全轉變為基于分布的理解(大多數時候是高斯分布)。
直到今天,我仍然驚訝于這兩個量的作用,標準差能幫助人理解現象。只要知道這兩個量,就可以直接得出具體結果的概率,用戶馬上就知道大部分的結果的分布情況。它提供了一個參考框架,無需進行過于復雜的計算,就可以快速找出有統計意義的事件。
一般來說,面對新數據時,我的第一步是嘗試可視化其分布,以便更好地理解數據。
3. 加載數據和包導入

先加載本文使用的數據。我已經對數據進行了預處理。并對它的意義進行了探究和推斷。
# Loadthe data data = pd.read_csv('https://raw.githubusercontent.com/FBosler/AdvancedPlotting/master/combined_set.csv')#this assigns labels per year data['Mean Log GDP per capita'] =data.groupby('Year')['Log GDP per capita'].transform( pd.qcut, q=5, labels=(['Lowest','Low','Medium','High','Highest']) )數據集包含以下值:
年份:計量年(2007 -2018)
生活階梯:受訪者根據坎特里爾階梯(CantrilLadder),用0~10分(最滿意的為10分)來衡量他們今天的生活
人均GDP:根據世界銀行2018年11月14日發布的《世界發展指標》(WDI),將人均GDP調整為PPP(2011年不變價國際元)·
社會支持:對下面問題的回答:“遇到困難時,是否可以隨時獲得親戚或朋友的幫助?”
出生時預期健康壽命:出生時預期健康壽命是根據世界衛生組織(WHO)全球衛生觀察站(GHO)數據庫構建的,數據分別來自2005年、2010年、2015年和2016年。
自由選擇權:回答下面這個問題:“你是否對自己生活的選擇自由感到滿意?”
慷慨:對“過去一個月是否給慈善機構捐過款?”與人均GDP相比·
政治清廉:回答“腐敗現象在政府中是否普遍?”“腐敗在企業內部是否普遍?”
積極影響:包括前一天快樂、歡笑和享受的平均頻率。
負面影響:包括前一天焦慮、悲傷和憤怒的平均頻率。
對國家政府的信心:不言自明
民主質量:一個國家的民主程度
執行質量:一個國家的政策執行情況
Gapminder預期壽命:Gapminder的預期壽命
Gapminder人口:國家人口
導入
import plotly import pandas as pd import numpy as np import seaborn as sns import plotly.express as pximport matplotlib%matplotlib inlineassertmatplotlib.__version__ == "3.1.0",""" Please install matplotlib version 3.1.0 by running: 1) !pip uninstall matplotlib 2) !pip install matplotlib==3.1.0 """
4. 迅速:使用Pandas進行基本繪圖

Pandas有內置的繪圖功能,可以在Series或DataFrame上調用。之所以喜歡這些繪圖函數,是因為它們簡潔、使用合理的智能默認值、很快就能給出進展程度。
創建圖表,在數據中調用.plot(kind=
np.exp(data[data['Year']==2018]['LogGDP per capita']).plot( kind='hist' ) 運行上述命令,生成以下圖表。
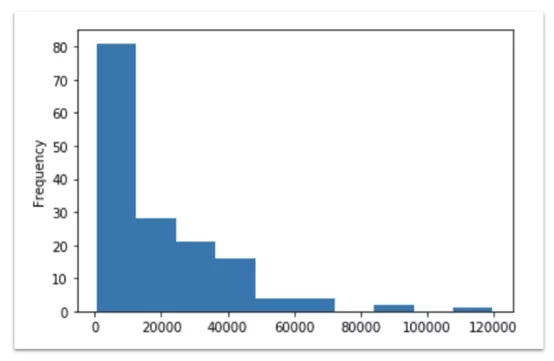
2018年:人均GDP直方圖。大多數國家都很窮,這一點也不奇怪!
用Pandas繪圖時,有五個主要參數:
kind:Pandas必須知道需要創建什么樣的圖,可選的有以下幾種:直方圖(hist),條形圖(bar),水平條圖(barh),散點圖(scatter),面積(area),核密度估計(kde),折線圖(line),方框(box),六邊形(hexbin),餅狀圖(pie)。
figsize:允許6英寸寬和4英寸高的默認輸出尺寸。需要一個元組(例如,我就經常使用figsize=(12,8))
title:為圖表添加一個標題。大多數情況下,可以用這個標題來標明圖表中所顯示的內容,這樣回過頭來看的時候,就能很快識別出表的內容。title需要一個字符串。
bins:直方圖的bin寬度。bin需要一個值的列表或類似列表序列(例如, bins=np.arange(2,8,0.25))
xlim/ylim: 軸的最大和最小默認值。xlim和ylim都最好有一個元組(例如, xlim=(0,5))
下面來快速瀏覽一下不同類型的圖。
(1) 垂直條形圖:
data[ data['Year'] == 2018 ].set_index('Country name')['Life Ladder'].nlargest(15).plot( kind='bar', figsize=(12,8) )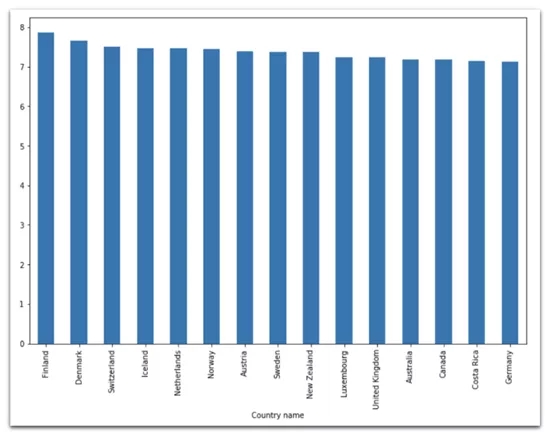
2018年:芬蘭位居15個最幸福國家之首
(2) 水平條形圖:
np.exp(data[ data['Year'] == 2018 ].groupby('Continent')['Log GDP per capita']\ .mean()).sort_values().plot( kind='barh', figsize=(12,8) )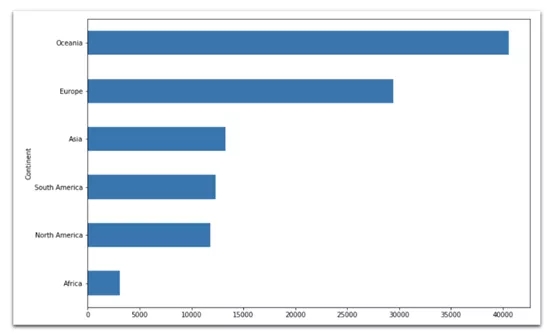
澳大利亞和新西蘭2011年人均GDP(美元)明顯領先
(3) 盒型圖
data['Life Ladder'].plot( kind='box', figsize=(12,8) )
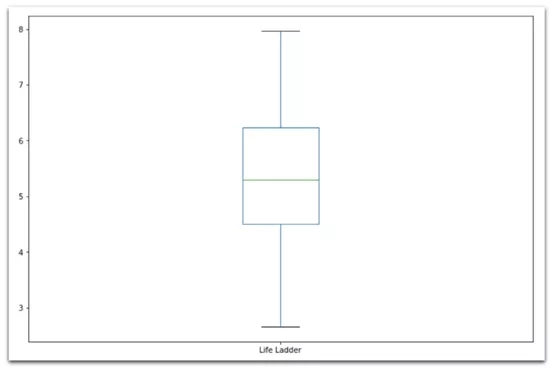
人生階梯分布的方框圖顯示平均值在5.5左右,范圍為3~8。
(4) 散點圖
data[['Healthy life expectancyat birth','Gapminder Life Expectancy']].plot( kind='scatter', x='Healthy life expectancy at birth', y='Gapminder Life Expectancy', figsize=(12,8) )
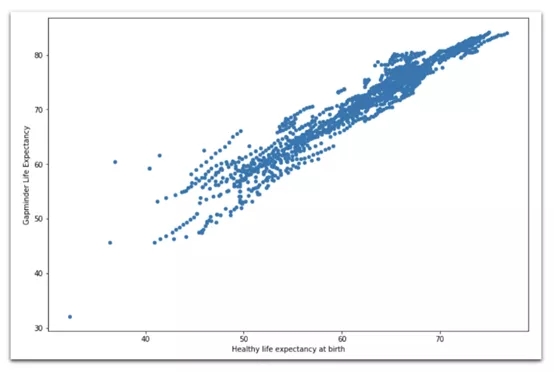
該散點圖顯示了《世界幸福報告》的預期壽命與Gapminder的預期壽命兩者之間的高度相關性
(5) Hexbin圖
data[data['Year'] == 2018].plot( kind='hexbin', x='Healthy life expectancy at birth', y='Generosity', C='Life Ladder', gridsize=20, figsize=(12,8), cmap="Blues", # defaults togreenish sharex=False # required to get rid ofa bug)
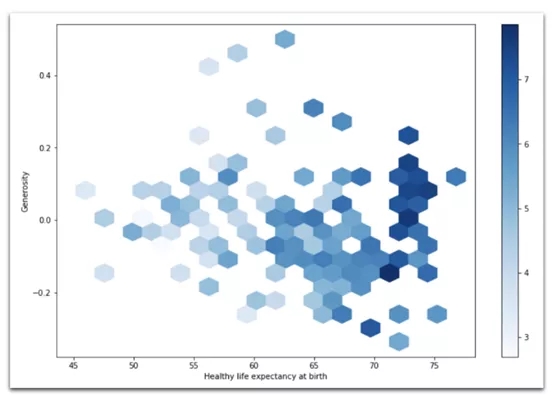
2018年:Hexbin圖,表示人的平均壽命與慷慨程度之間的關系。格子的顏色表示每個格子的平均壽命。
(6) 餅狀圖
data[data['Year'] == 2018].groupby( ['Continent'] )['Gapminder Population'].sum().plot( kind='pie', figsize=(12,8), cmap="Blues_r", # defaultsto orangish )
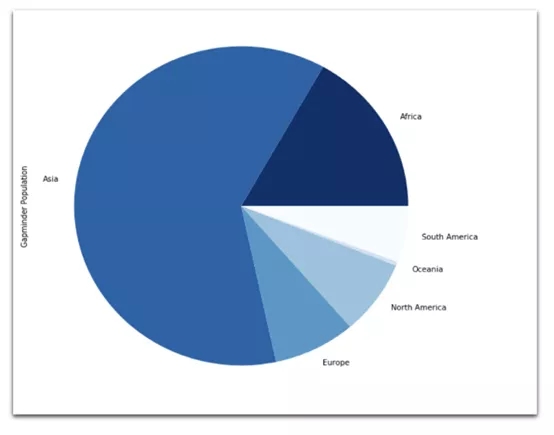
2018年:按大洲劃分的總人口數餅狀圖
(7) 堆積面積圖
data.groupby( ['Year','Continent'] )['Gapminder Population'].sum().unstack().plot( kind='area', figsize=(12,8), cmap="Blues", # defaults toorangish )
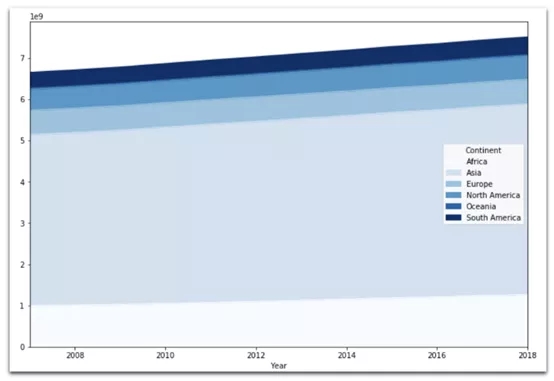
全球人口數量正在增長
(8) 折線圖
data[ data['Country name'] == 'Germany'].set_index('Year')['Life Ladder'].plot( kind='line', figsize=(12,8))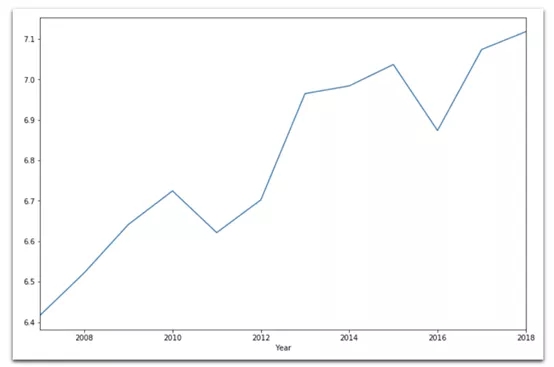
表示德國幸福指數發展的折線圖
(9) 關于Pandas繪圖的總結
用pandas繪圖很方便。易于訪問,速度也快。只是圖表外觀相當丑,幾乎不可能偏離默認值。不過這沒關系,因為有其他工具來制作更美觀的圖表。
5. 美觀:使用Seaborn進行高級繪圖

Seaborn使用的是默認繪圖。要確保運行結果與本文一致,請運行以下命令。
sns.reset_defaults() sns.set( rc={'figure.figsize':(7,5)}, style="white" # nicerlayout )(1) 繪制單變量分布
如前所述,我非常喜歡分布。直方圖和核密度分布都是可視化特定變量關鍵特征的有效方法。下面來看看如何在一個圖表中生成單個變量或多個變量分布。
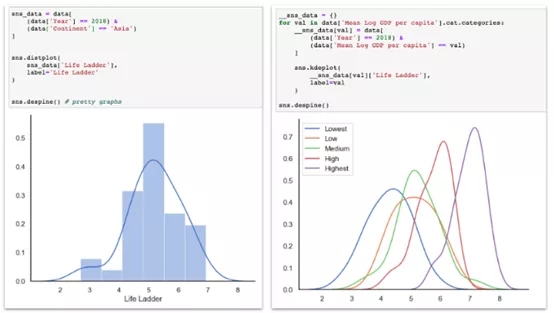
左圖:2018年亞洲國家人生階梯直方圖和核密度估算;
右圖:五組人均GDP人生階梯的核心密度估算——體現了金錢與幸福指數的關系
(2) 繪制二元分布
每當我想要直觀地探索兩個或多個變量之間的關系,總是用到某種形式的散點圖和分布評估。在概念上相似的圖表有三種變體。在每個圖中,中心圖(散點圖,二元KDE,hexbin)有助于理解兩個變量之間的聯合頻率分布。此外,在中心圖的右邊界和上邊界,描述了各自變量的邊際單變量分布(用KDE或直方圖表示)。
sns.jointplot( x='Log GDP per capita', y='Life Ladder', datadata=data, kind='scatter' # or 'kde' or 'hex' )
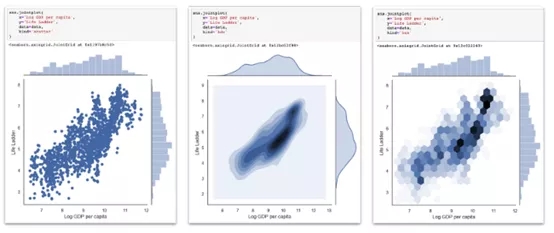
Seaborn雙標圖,散點圖、二元KDE和Hexbin圖都在中心圖中,邊緣分布在中心圖的左側和頂部
(3) 散點圖
散點圖是一種可視化兩個變量聯合密度分布的方法。可以通過添加色度來添加第三個變量,通過添加尺寸參數來添加第四個變量。
sns.scatterplot( x='Log GDP per capita', y='Life Ladder', datadata=data[data['Year'] == 2018], hue='Continent', size='Gapminder Population' )# both, hue and size are optional sns.despine() # prettier layout
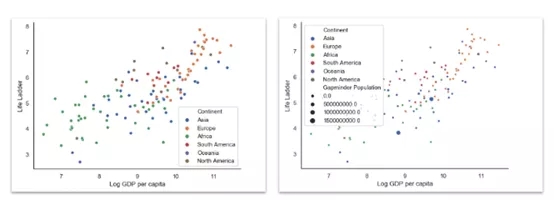
人均GDP與生活階梯的關系,不同顏色表示不同大洲和人口規模
(4) 小提琴圖
小提琴圖結合了盒狀圖和核密度估計值。它的作用類似于盒狀圖,顯示了定量數據在分類變量之間的分布,以便對這些分布進行比較。
sns.set( rc={'figure.figsize':(18,6)}, style="white")sns.violinplot( x='Continent', y='Life Ladder', hue='Mean Log GDP per capita', datadata=data)sns.despine()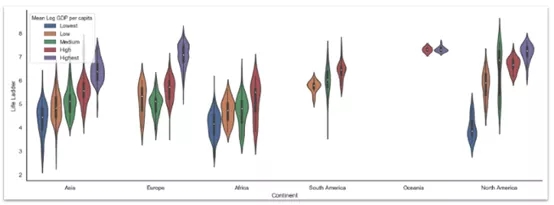
小提琴圖在繪制大洲與生活階梯的關系圖時,用人均GDP的平均值對數據進行分組。人均GDP越高,幸福指數就越高。
(5) 配對圖
Seaborn配對圖是在一個大網格中繪制雙變量散點圖的所有組合。我通常覺得這有點信息過載,但它有助于發現規律。
sns.set( style="white", palette="muted", color_codes=True )sns.pairplot( data[data.Year == 2018][[ 'Life Ladder','Log GDP percapita', 'Social support','Healthy lifeexpectancy at birth', 'Freedom to make lifechoices','Generosity', 'Perceptions of corruption','Positive affect', 'Negative affect','Confidence innational government', 'Mean Log GDP per capita' ]].dropna(), hue='Mean Log GDP per capita' )
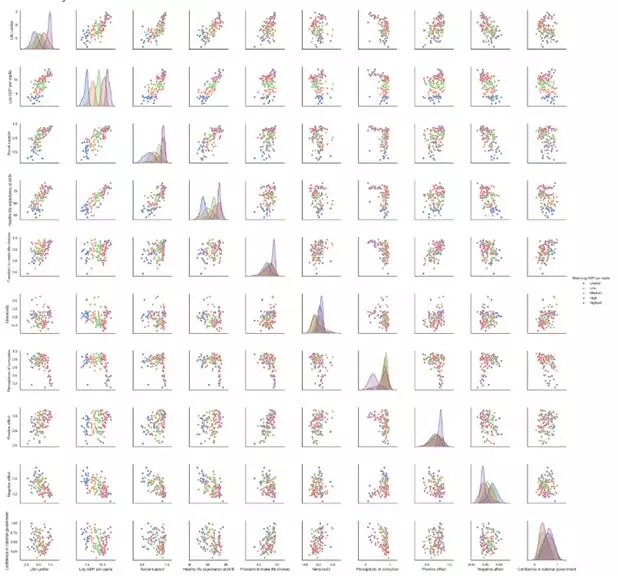
Seaborn散點圖網格中,所有選定的變量都分散在網格的下半部分和上半部分,對角線包含Kde圖。
(6) FacetGrids
對我來說,Seaborn的FacetGrid是證明它好用最有說服力的證據之一,因為它能輕而易舉地創建多圖表。通過配對圖,我們已經看到了FacetGrid的一個示例。它可以創建多個按變量分組的圖表。例如,行可以是一個變量(人均GDP的類別),列是另一個變量(大洲)。
它確實還需要適應客戶需求(即使用matplotlib),但是它仍然是令人信服。
(7) FacetGrid— 折線圖
g = sns.FacetGrid( data.groupby(['Mean Log GDP percapita','Year','Continent'])['Life Ladder'].mean().reset_index(), row='Mean Log GDP per capita', col='Continent', margin_titles=True ) g = (g.map(plt.plot, 'Year','Life Ladder'))
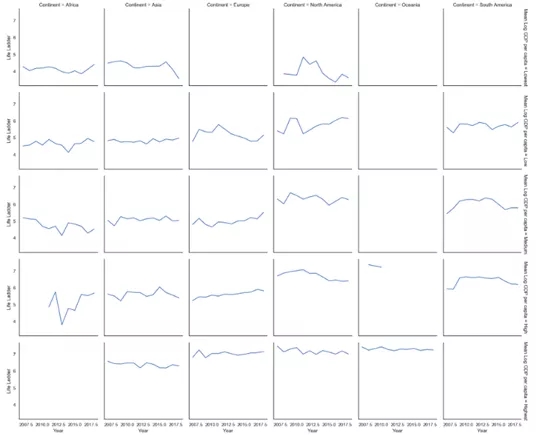
y軸代表生活階梯,x軸代表年份。網格的列代表大洲,網格的行代表不同水平的人均GDP。總體而言,北美人均GDP平均值較低的國家和歐洲人均GDP平均值中等或較高的國家,情況似乎有所好轉。
(8) FacetGrid— 直方圖
g = sns.FacetGrid(data,col="Continent", col_wrap=3,height=4) g = (g.map(plt.hist, "Life Ladder",bins=np.arange(2,9,0.5)))
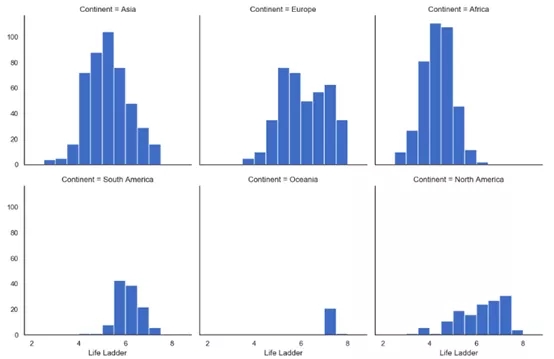
按大洲劃分的生活階梯直方圖
(9) FacetGrid— 帶注釋的KDE圖
還可以向網格中的每個圖表添加特定的注釋。以下示例將平均值和標準偏差以及在平均值處繪制的垂直線相加(代碼如下)。
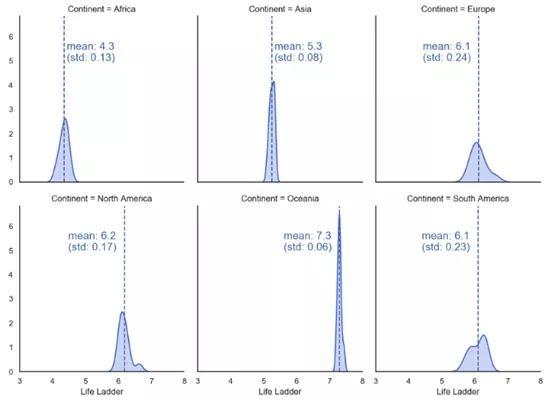
基于大洲的生命階梯核密度估計值,注釋為均值和標準差
defvertical_mean_line(x, **kwargs): plt.axvline(x.mean(), linestyle="--", color= kwargs.get("color", "r")) txkw =dict(size=15, color= kwargs.get("color", "r")) label_x_pos_adjustment =0.08# this needs customization based on your data label_y_pos_adjustment =5# this needs customization based on your data if x.mean() <6: # this needs customization based on your data tx ="mean: {:.2f}\n(std: {:.2f})".format(x.mean(),x.std()) plt.text(x.mean() + label_x_pos_adjustment, label_y_pos_adjustment, tx, **txkw) else: tx ="mean: {:.2f}\n (std: {:.2f})".format(x.mean(),x.std()) plt.text(x.mean() -1.4, label_y_pos_adjustment, tx, **txkw) _ = data.groupby(['Continent','Year'])['Life Ladder'].mean().reset_index() g = sns.FacetGrid(_, col="Continent", height=4, aspect=0.9, col_wrap=3, margin_titles=True) g.map(sns.kdeplot, "Life Ladder", shade=True, color='royalblue') g.map(vertical_mean_line, "Life Ladder")annotate_facet_grid.py hostedwith ? by GitHub
畫一條垂直的平均值線并添加注釋。
(10) FacetGrid— 熱圖
我最喜歡的一種繪圖類型就是FacetGrid的熱圖,即每一個網格都有熱圖。這種類型的繪圖有助于在一個圖中可視化四維和度量。代碼有點麻煩,但是可以根據使用者的需要快速調整。需要注意的是,這種圖表不能很好地處理缺失的值,所以需要大量的數據或適當的分段。
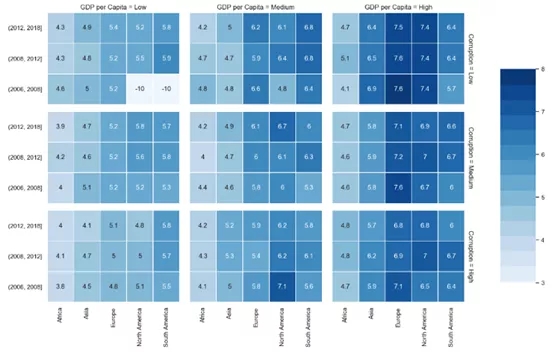
Facet熱圖,外層的行顯示在一年內,外層的列顯示人均GDP,內層的行顯示政治清廉,內層的列顯示大洲。我們看到幸福指數朝著右上方向增加(即,高人均GDP和高政治清廉)。時間的影響還不確定,一些大洲(歐洲和北美)似乎比其他大洲(非洲)更幸福。
heatmap_facetgrid.py
defdraw_heatmap(data,inner_row, inner_col, outer_row, outer_col, values, vmin,vmax): sns.set(font_scale=1) fg = sns.FacetGrid( data, row=outer_row, col=outer_col, margin_titles=True ) position = left, bottom, width, height =1.4, .2, .1, .6 cbar_ax = fg.fig.add_axes(position) fg.map_dataframe( draw_heatmap_facet, x_col=inner_col, y_col=inner_row, valuesvalues=values, cbar_axcbar_ax=cbar_ax, vminvmin=vmin, vmaxvmax=vmax ) fg.fig.subplots_adjust(right=1.3) plt.show() defdraw_heatmap_facet(*args, **kwargs): data = kwargs.pop('data') x_col = kwargs.pop('x_col') y_col = kwargs.pop('y_col') values = kwargs.pop('values') d = data.pivot(index=y_col, columns=x_col, valuesvalues=values) annot =round(d,4).values cmap = sns.color_palette("Blues",30) + sns.color_palette("Blues",30)[0::2] #cmap = sns.color_palette("Blues",30) sns.heatmap( d, **kwargs, annotannot=annot, center=0, cmapcmap=cmap, linewidth=.5 ) # Data preparation _ = data.copy() _['Year'] = pd.cut(_['Year'],bins=[2006,2008,2012,2018]) _['GDP per Capita'] = _.groupby(['Continent','Year'])['Log GDP per capita'].transform( pd.qcut, q=3, labels=(['Low','Medium','High']) ).fillna('Low') _['Corruption'] = _.groupby(['Continent','GDP per Capita'])['Perceptions of corruption'].transform( pd.qcut, q=3, labels=(['Low','Medium','High']) ) __ = _[_['Continent'] !='Oceania'].groupby(['Year','Continent','GDP per Capita','Corruption'])['Life Ladder'].mean().reset_index() _['Life Ladder'] = _['Life Ladder'].fillna(-10) draw_heatmap( data=_, outer_row='Corruption', outer_col='GDP per Capita', inner_row='Year', inner_col='Continent', values='Life Ladder', vmin=3, vmax=8, )heatmap_facetgrid.py hostedwith ? by GitHub
6. 精彩:用plotly創造精彩的互動情節

最后, 無需使用matplotlib!Plotly有三個重要特征:
懸停:當鼠標懸停在圖表上時,會彈出注釋
交互性:不需要任何額外設置,圖表就可以進行交互(例如,一次穿越時間的旅程)
漂亮的地理空間圖:Plotly已經內置了一些基本的映射功能,另外,還可以使用mapbox集成來制作令人驚嘆的圖表。
(1) 散點圖
通過下列代碼來運行plotly圖表:
fig = x.<PLOTTYPE>(PARAMS)然后是 fig.show() ,像這樣: fig = px.scatter( datadata_frame=data[data['Year'] ==2018], x="Log GDP per capita", y="Life Ladder", size="GapminderPopulation", color="Continent", hover_name="Country name", size_max=60 ) fig.show()
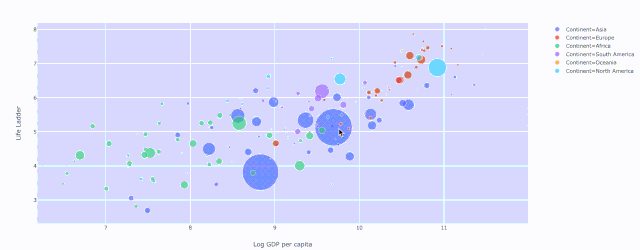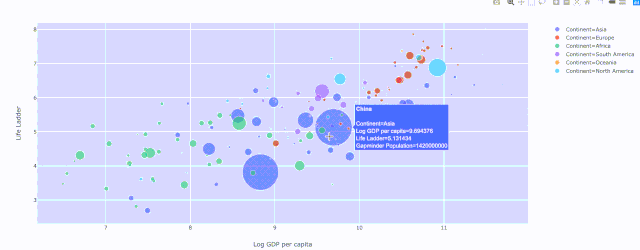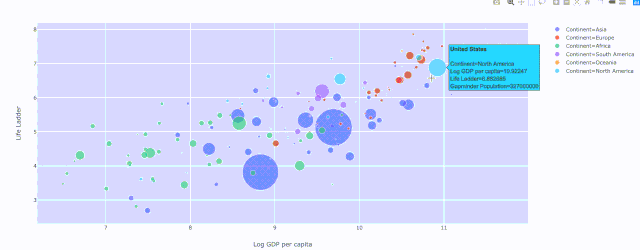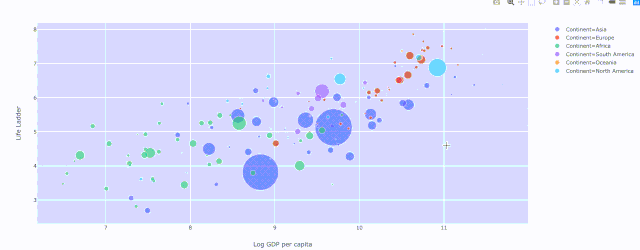
(2) 散點圖 — 穿越時間的漫步
fig = px.scatter( datadata=data, x="Log GDP per capita", y="Life Ladder", animation_frame="Year", animation_group="Countryname", size="GapminderPopulation", color="Continent", hover_name="Country name", facet_col="Continent", size_max=45, category_orders={'Year':list(range(2007,2019))} )fig.show()
可視化數年來繪圖數據的變化
(3) 平行類別——一個能可視化類別的有趣方式
def q_bin_in_3(col): return pd.qcut( col, q=3, labels=['Low','Medium','High'] )_ = data.copy() _['Social support'] = _.groupby('Year')['Socialsupport'].transform(q_bin_in_3)_['Life Expectancy'] =_.groupby('Year')['Healthy life expectancy atbirth'].transform(q_bin_in_3)_['Generosity'] =_.groupby('Year')['Generosity'].transform(q_bin_in_3)_['Perceptions ofcorruption'] = _.groupby('Year')['Perceptions ofcorruption'].transform(q_bin_in_3)__ = _.groupby(['Social support','LifeExpectancy','Generosity','Perceptions of corruption'])['LifeLadder'].mean().reset_index()fig = px.parallel_categories(_, color="LifeLadder", color_continuous_scale=px.colors.sequential.Inferno) fig.show()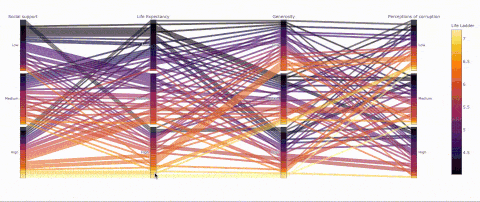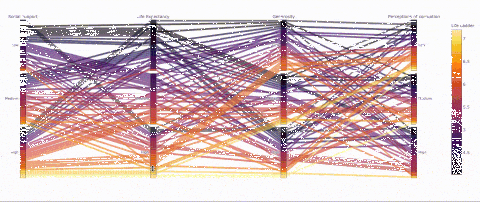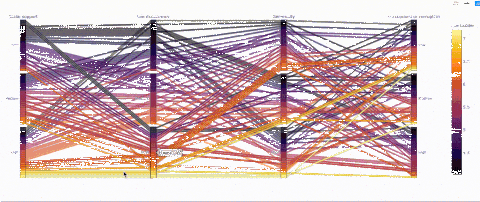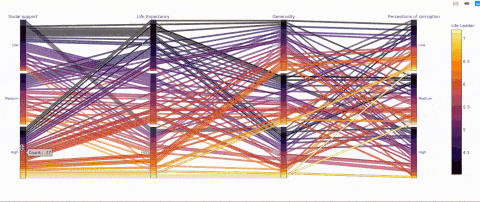
并不是所有預期壽命高的國家的人民都很幸福!
(4) 條形圖—一個交互式濾波器的示例
fig = px.bar( data, x="Continent", y="Gapminder Population", color="Mean Log GDP percapita", barmode="stack", facet_col="Year", category_orders={"Year":range(2007,2019)}, hover_name='Country name', hover_data=[ "Mean Log GDP percapita", "Gapminder Population", "Life Ladder" ] ) fig.show()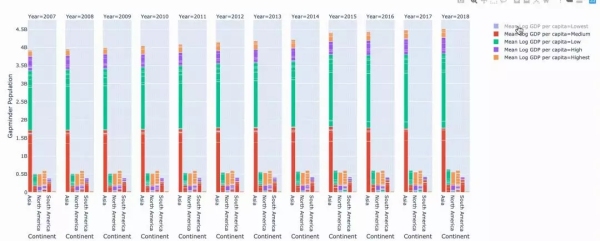
過濾條形圖很容易。毫無疑問,韓國是亞洲富裕國家之一。
(5) 等值線圖— —幸福指數與時間的關系
fig = px.choropleth( data, locations="ISO3", color="Life Ladder", hover_name="Country name", animation_frame="Year")fig.show()
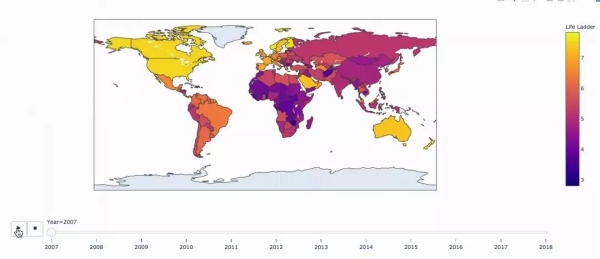
可視化不同地域的幸福指數是如何隨時間變化的。敘利亞和阿富汗正處于人生階梯的末端(這不足為奇)。
結束語
展示了如何成為一名真正的Python可視化專家、如何在快速探索時更有效率、以及如何在董事會會議前創建更漂亮的圖表、還有如何創建交互式繪圖圖表,尤其是在繪制地理空間數據時,十分有用。
上述就是小編為大家分享的如何用Python快速制作美觀炫酷且有深度的圖表了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





