溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Python怎么爬取電子課本送給居家上課的孩子們,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
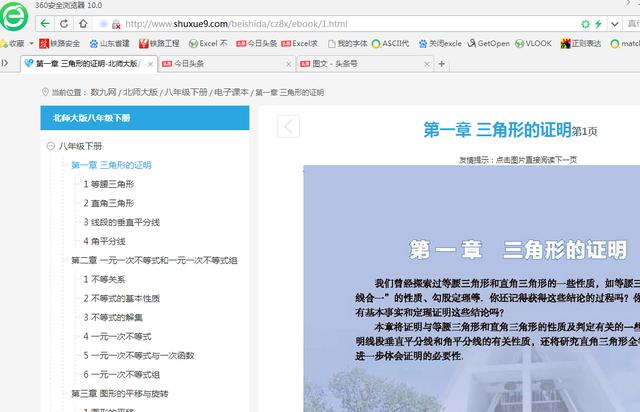
在這個全民抗疫的日子,中小學生們也開啟了居家上網課的生活。很多沒借到書的孩子,不得不在網上看電子課本,有的電子課本是老師發的網絡鏈接,每次打開網頁去看,既費流量,也不方便。今天我們就利用python的爬蟲功能,把網絡鏈接的課本爬下來,再做成PDF格式的本地文件,讓孩子們隨時都能看。本文案例爬取的網絡課本見下圖:
實現思路為兩部分:
用python從網站爬取全部課本圖片;
將圖片合并生成PDF格式文件。
具體過程:
爬蟲4流程:發出請求——獲得網頁——解析內容——保存內容。
根據上篇python批量爬取網絡圖片里講過的知識,網頁里的圖片有單獨的網址,爬取圖片時需要先爬取出圖片網址,再根據圖片網址爬取圖片。
1、發出請求:
首先找出合適的網址URL,因是靜態網頁網址,我們可直接用瀏覽器地址欄的網址,下圖2中紅框位置即為要用的網址,復制下來就行。
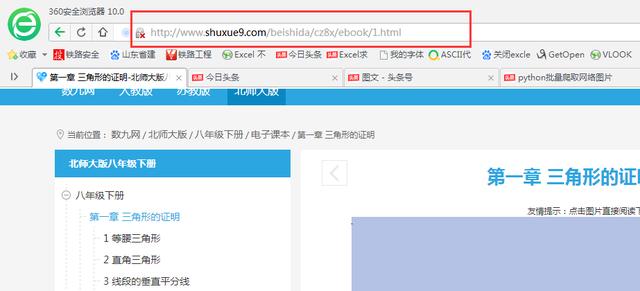
網頁網址為:http://www.shuxue9.com/beishida/cz8x/ebook/1.html
2、發出請求獲得響應:
url = http://www.shuxue9.com/beishida/cz8x/ebook/1.htmlresponse = requests.get(url)
3、解析響應獲得網頁內容:
soup = BeautifulSoup(response.content, 'lxml')
4、解析網頁內容,獲得圖片網址:
jgp_url = soup.find('div', class_="center").find('a').find('img')['src']5、向圖片網址發出訪問請求,并獲得圖片(因為該網址僅有圖片,不需用find解析):
jpg = requests.get(jgp_url).content
6、保存圖片:
f = open(set_path() + number + '.jpg','wb')f.write(jpg)
其中,set_path()是提前建好的用于存放圖片的路徑,代碼見下,也可直接寫上想用的路徑:
def set_path(): path = r'e:/python/book' if not os.path.isdir(path): os.makedirs(path) paths = path+'/' return(paths)
7、存在問題:
以上就完成了課本圖片的爬取,我們打開文件夾,發現只有一張圖片被下載了,后面的都沒。這是因為瀏覽網頁時,每個頁面都有不同的網址,我們試著分析一下,發現電子課本的每一頁網址很有規律:
第1頁網址:http://www.shuxue9.com/beishida/cz8x/ebook/1.html
第2頁網址:http://www.shuxue9.com/beishida/cz8x/ebook/2.html
......
第n頁網址:http://www.shuxue9.com/beishida/cz8x/ebook/n.html
每頁上的圖片網址各不相同,沒規律。我們可以根據規律用循環方式,對網址發起訪問,獲得圖片后,自動循環訪問下一個網址......最終獲得全部圖片。
8、設置循環提取:
在以上全部過程納入到一個for循環里,根據網頁,我們可以看到共有152頁,設置循環后完整代碼為:
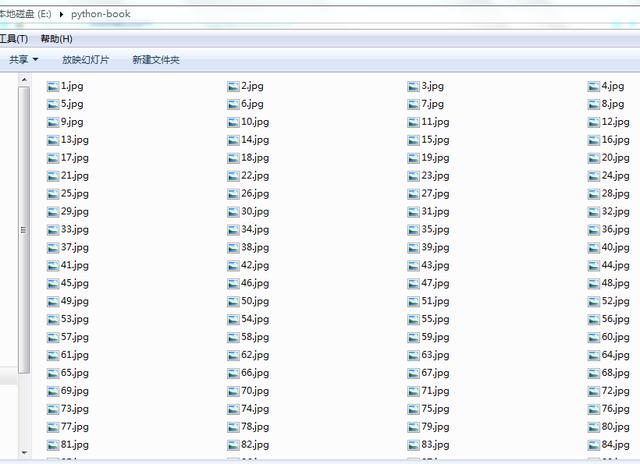
import requests , osfrom bs4 import BeautifulSoupfor i in range(1, 153):# 發出請求 url = "http://www.shuxue9.com/beishida/cz8x/ebook /{}".format(i)+".html" response = requests.get(url)# 獲得網頁 soup = BeautifulSoup(response.content, 'lxml')# 解析網頁得到圖片網址 jgp_url = soup.find('div', class_="center").find('a').find('img') ['src']# 發出請求解析獲得圖片 jpg = requests.get(jgp_url).content# 設置圖片保存路徑 p = r'e:/python-book' if not os.path.isdir(p): os.makedirs(p)# 保存圖片 f = open(p + '/' + str(i) + '.jpg', 'wb') f.write(jpg)print("下載完成")運行程序,即可一次下載全部課本圖片,效果為:

二、將圖片合并生成PDF格式文件
圖片下載完成后,將圖片生成PDF格式才方便使用。網上有專門的軟件,但免費的試用版只能合并幾張圖片。今天教大家一個免費且常用的OFFICE—ppt軟件來將多張圖片合并成一個PDF格式文件。
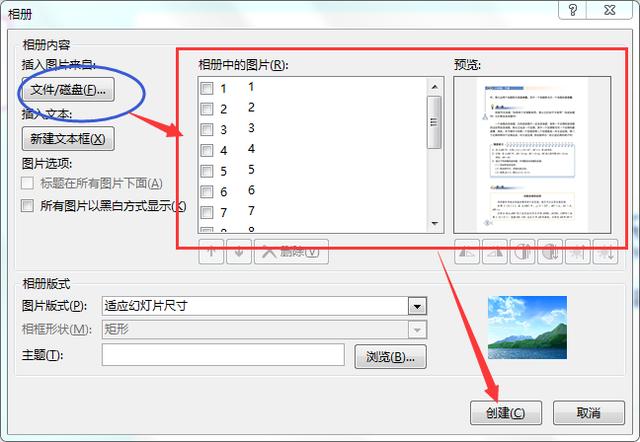
新建一個PowerPoint空白文件,點擊插入——相冊——新建相冊,
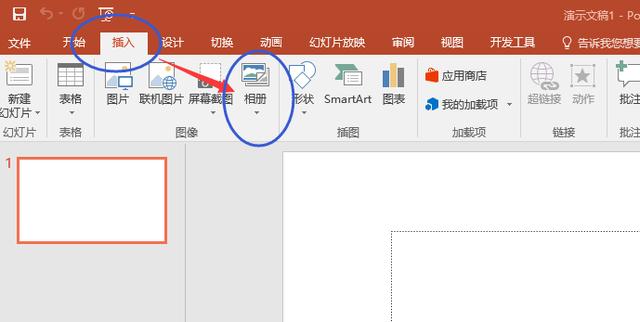
在彈出的窗體里,點擊左上角的“文件/磁盤”,將剛才下載的圖片全部導入進去,導入后的效果如下圖右側紅框樣式,然后點擊“創建”,保存文件時另存為PDF格式即可。
總結:
至此,從網頁爬取電子課本圖片,生成PDF格式的本地文件就全部完成了。其中,如何找到并提取網頁中的圖片網址,在本頭條上一篇文章里已有詳述,有疑問的可查閱或留言交流。
另分享一個從網頁內容中找到圖片網址的簡便方法:在打開的開發者工具界面,點擊左上角的箭頭符號,然后在網頁上點擊想要查找網址的圖片,會自動高亮顯示圖片網址所在位置。如下所示:

關于Python怎么爬取電子課本送給居家上課的孩子們問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





