溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Tomcat高并發之如何理解道與性能調優”,在日常操作中,相信很多人在Tomcat高并發之如何理解道與性能調優問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Tomcat高并發之如何理解道與性能調優”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
高并發拆解核心準備
這回,再次拆解,專注 Tomcat 高并發設計之道與性能調優,讓大家對整個架構有更高層次的了解與感悟。其中設計的每個組件思路都是將 Java 面向對象、面向接口、如何封裝變與不變,如何根據實際需求抽象不同組件分工合作,如何設計類實現單一職責,怎么做到將相似功能高內聚低耦合,設計模式運用到極致的學習借鑒。
這次主要涉及到的是 I/O 模型,以及線程池的基礎內容。
在學習之前,希望大家積累以下一些技術內容,很多內容「碼哥字節」也在歷史文章中分享過。大家可爬樓回顧……。希望大家重視如下幾個知識點,在掌握以下知識點再來拆解 Tomcat,就會事半功倍,否則很容易迷失方向不得其法。
一起來看 Tomcat 如何實現并發連接處理以及任務處理,性能的優化是每一個組件都起到對應的作用,如何使用最少的內存,最快的速度執行是我們的目標。
設計模式
模板方法模式: 抽象算法流程在抽象類中,封裝流程中的變化與不變點。將變化點延遲到子類實現,達到代碼復用,開閉原則。
觀察者模式:針對事件不同組件有不同響應機制的需求場景,達到解耦靈活通知下游。
責任鏈模式:將對象連接成一條鏈,將沿著這條鏈傳遞請求。在 Tomcat 中的 Valve 就是該設計模式的運用。
更多設計模式可查看「碼哥字節」之前的設計模式專輯,這里是傳送門。
I/O 模型
Tomcat 實現高并發接收連接,必然涉及到 I/O 模型的運用,了解同步阻塞、異步阻塞、I/O 多路復用,異步非阻塞相關概念以及 Java NIO 包的運用很有必要。本文也會帶大家著重說明 I/O 是如何在 Tomcat 運用實現高并發連接。大家通過本文我相信對 I/O 模型也會有一個深刻認識。
Java 并發編程
實現高并發,除了整體每個組件的優雅設計、設計模式的合理、I/O 的運用,還需要線程模型,如何高效的并發編程技巧。在高并發過程中,不可避免的會出現多個線程對共享變量的訪問,需要加鎖實現,如何高效的降低鎖沖突。因此作為程序員,要有意識的盡量避免鎖的使用,比如可以使用原子類 CAS 或者并發集合來代替。如果萬不得已需要用到鎖,也要盡量縮小鎖的范圍和鎖的強度。
對于并發相關的基礎知識,如果讀者感興趣「碼哥字節」后面也給大家安排上,目前也寫了部分并發專輯,大家可移步到歷史文章或者專輯翻閱,這里是傳送門,主要講解了并發實現的原理、什么是內存可見性,JMM 內存模模型、讀寫鎖等并發知識點。
Tomcat 總體架構
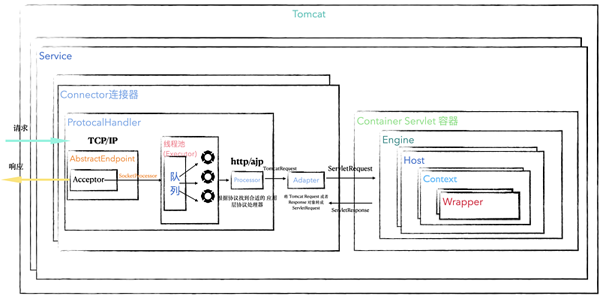
再次回顧下 Tomcat 整體架構設計,主要設計了 connector 連接器處理 TCP/IP 連接,container 容器作為 Servlet 容器,處理具體的業務請求。對外對內分別抽象兩個組件實現拓展。
一個 Tomcat 實例默認會有一個 Service,而一個 Service 可以包含多個連接器。連接器主要有 ProtocalHandler 和 Adapter 兩個組件共同完成連接器核心功能。
ProtocolHandler 主要由 Acceptor 以及 SocketProcessor 構成,實現了 TCP/IP 層 的 Socket 讀取并轉換成 TomcatRequest 和 TomcatResponse,最后根據 http 或者 ajp 協議獲取合適的 Processor 解析為應用層協議,并通過 Adapter 將 TomcatRequest、TomcatResponse 轉化成 標準的 ServletRequest、ServletResponse。通過 getAdapter().service(request, response);將請求傳遞到 Container 容器。
adapter.service()實現將請求轉發到容器 org.apache.catalina.connector.CoyoteAdapter
// Calling the container connector.getService().getContainer().getPipeline().getFirst().invoke( request, response);
這個調用會觸發 getPipeline 構成的責任鏈模式將請求一步步走入容器內部,每個容器都有一條 Pipeline,通過 First 開始到 Basic 結束并進入容器內部持有的子類容器,最后到 Servlet,這里就是責任鏈模式的經典運用。具體的源碼組件是 Pipeline 構成一條請求鏈,每一個鏈點由 Valve 組成。「碼哥字節」在上一篇Tomcat 架構解析到工作借鑒 已經詳細講解。如下圖所示,整個 Tomcat 的架構設計重要組件清晰可見,希望大家將這個全局架構圖深深印在腦海里,掌握全局思路才能更好地分析細節之美。
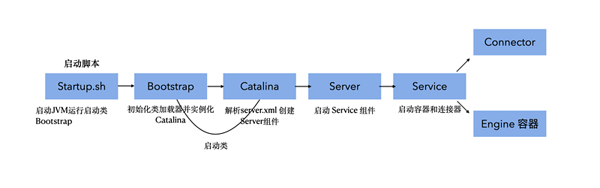
啟動流程:startup.sh 腳本到底發生了什么
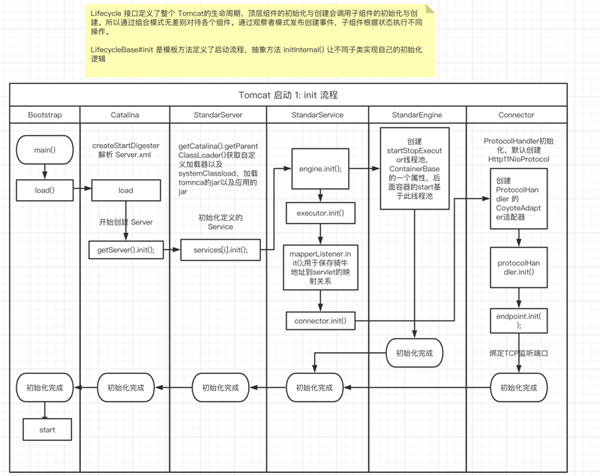
Tomcat 啟動流程
Tomcat 本生就是一個 Java 程序,所以 startup.sh 腳本就是啟動一個 JVM 來運行 Tomcat 的啟動類 Bootstrap。
Bootstrap 主要就是實例化 Catalina 和初始化 Tomcat 自定義的類加載器。熱加載與熱部署就是靠他實現。
Catalina: 解析 server.xml 創建 Server 組件,并且調用 Server.start() 方法。
Server:管理 Service 組件,調用 Server 的 start() 方法。
Service:主要職責就是管理簡介器的頂層容器 Engine,分別調用 Connector 和 Engine 的 start 方法。
Engine 容器主要就是組合模式將各個容器根據父子關系關聯,并且 Container 容器繼承了 Lifecycle 實現各個容器的初始化與啟動。Lifecycle 定義了 init()、start()、stop() 控制整個容器組件的生命周期實現一鍵啟停。
這里就是一個面向接口、單一職責的設計思想 ,Container 利用組合模式管理容器,LifecycleBase 抽象類繼承 Lifecycle 將各大容器生命周期統一管理這里便是,而實現初始化與啟動的過程又 LifecycleBase 運用了模板方法設計模式抽象出組件變化與不變的點,將不同組件的初始化延遲到具體子類實現。并且利用觀察者模式發布啟動事件解耦。
具體的 init 與 start 流程如下泳道圖所示:這是我在閱讀源碼 debug 所做的筆記,讀者朋友們不要怕筆記花費時間長,自己跟著 debug 慢慢記錄,相信會有更深的感悟。
init 流程
start 流程
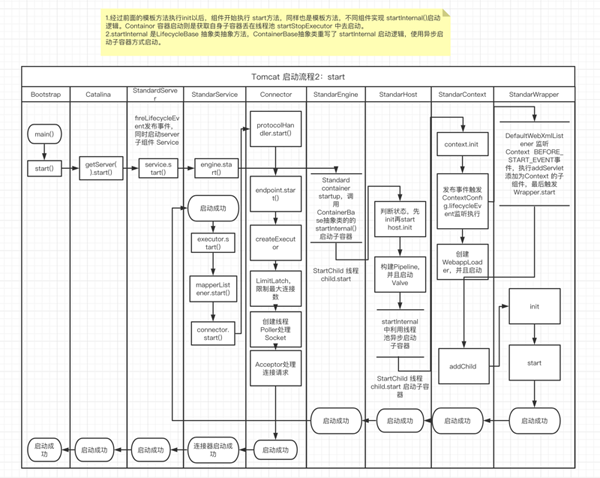
讀者朋友根據我的兩篇內容,抓住主線組件去 debug,然后跟著該泳道圖閱讀源碼,我相信都會有所收獲,并且事半功倍。在讀源碼的過程中,切勿進入某個細節,一定要先把各個組件抽象出來,了解每個組件的職責即可。最后在了解每個組件的職責與設計哲學之后再深入理解每個組件的實現細節,千萬不要一開始就想著深入理解具體一篇葉子。
每個核心類我在架構設計圖以及泳道圖都標識出來了,「碼哥字節」給大家分享下如何高效閱讀源碼,以及保持學習興趣的心得體會。
如何正確閱讀源碼
切勿陷入細節,不看全局:我還沒弄清楚森林長啥樣,就盯著葉子看 ,看不到全貌和整體設計思路。所以閱讀源碼學習的時候不要一開始就進入細節,而是宏觀看待整體架構設計思想,模塊之間的關系。
1.閱讀源碼之前,需要有一定的技術儲備
比如常用的設計模式,這個必須掌握,尤其是:模板方法、策略模式、單例、工廠、觀察者、動態代理、適配器、責任鏈、裝飾器。大家可以看 「碼哥字節」關于設計模式的歷史文章,打造好的基礎。
2.必須會使用這個框架/類庫,精通各種變通用法
魔鬼都在細節中,如果有些用法根本不知道,可能你能看明白代碼是什么意思,但是不知道它為什么這些寫。
3.先去找書,找資料,了解這個軟件的整體設計。
從全局的視角去看待,上帝視角理出主要核心架構設計,先森林后樹葉。都有哪些模塊? 模塊之間是怎么關聯的?怎么關聯的?
可能一下子理解不了,但是要建立一個整體的概念,就像一個地圖,防止你迷航。
在讀源碼的時候可以時不時看看自己在什么地方。就像「碼哥字節」給大家梳理好了 Tomcat 相關架構設計,然后自己再嘗試跟著 debug,這樣的效率如虎添翼。
4. 搭建系統,把源代碼跑起來!
Debug 是非常非常重要的手段, 你想通過只看而不運行就把系統搞清楚,那是根本不可能的!合理運用調用棧(觀察調用過程上下文)。
5.筆記
一個非常重要的工作就是記筆記(又是寫作!),畫出系統的類圖(不要依靠 IDE 給你生成的), 記錄下主要的函數調用, 方便后續查看。
文檔工作極為重要,因為代碼太復雜,人的大腦容量也有限,記不住所有的細節。 文檔可以幫助你記住關鍵點, 到時候可以回想起來,迅速地接著往下看。
要不然,你今天看的,可能到明天就忘個差不多了。所以朋友們記得收藏后多翻來看看,嘗試把源碼下載下來反復調試。
錯誤方式
陷入細節,不看全局:我還沒弄清楚森林長啥樣,就盯著葉子看 ,看不到全貌和整體設計思路。所以閱讀源碼學習的時候不要一開始就進入細節,而是宏觀看待整體架構設計思想,模塊之間的關系。
還沒學會用就研究如何設計:首先基本上框架都運用了設計模式,我們最起碼也要了解常用的設計模式,即使是“背”,也得了然于胸。在學習一門技術,我推薦先看官方文檔,看看有哪些模塊、整體設計思想。然后下載示例跑一遍,最后才是看源碼。
看源碼深究細節:到了看具體某個模塊源碼的時候也要下意識的不要去深入細節,重要的是學習設計思路,而不是具體一個方法實現邏輯。除非自己要基于源碼做二次開發,而且二次開發也是基于在了解扎鞥個架構的情況下才能深入細節。
組件設計-落實單一職責、面向接口思想
當我們接到一個功能需求的時候,最重要的就是抽象設計,將功能拆解主要核心組件,然后找到需求的變化與不變點,將相似功能內聚,功能之間若耦合,同時對外支持可拓展,對內關閉修改。努力做到一個需求下來的時候我們需要合理的抽象能力抽象出不同組件,而不是一鍋端將所有功能糅合在一個類甚至一個方法之中,這樣的代碼牽一發而動全身,無法拓展,難以維護和閱讀。
帶著問題我們來分析 Tomcat 如何設計組件完成連接與容器管理。
看看 Tomcat 如何實現將 Tomcat 啟動,并且又是如何接受請求,將請求轉發到我們的 Servlet 中。
Catalina
主要任務就是創建 Server,并不是簡單創建,而是解析 server.xml 文件把文件配置的各個組件意義創建出來,接著調用 Server 的 init() 和 start() 方法,啟動之旅從這里開始…,同時還要兼顧異常,比如關閉 Tomcat 還需要做到優雅關閉啟動過程創建的資源需要釋放,Tomcat 則是在 JVM 注冊一個「關閉鉤子」,源碼我都加了注釋,省略了部分無關代碼。同時通過 await() 監聽停止指令關閉 Tomcat。
/** * Start a new server instance. */ public void start() { // 若 server 為空,則解析 server.xml 創建 if (getServer() == null) { load(); } // 創建失敗則報錯并退出啟動 if (getServer() == null) { log.fatal("Cannot start server. Server instance is not configured."); return; } // 開始啟動 server try { getServer().start(); } catch (LifecycleException e) { log.fatal(sm.getString("catalina.serverStartFail"), e); try { // 異常則執行 destroy 銷毀資源 getServer().destroy(); } catch (LifecycleException e1) { log.debug("destroy() failed for failed Server ", e1); } return; } // 創建并注冊 JVM 關閉鉤子 if (useShutdownHook) { if (shutdownHook == null) { shutdownHook = new CatalinaShutdownHook(); } Runtime.getRuntime().addShutdownHook(shutdownHook); } // 通過 await 方法監聽停止請求 if (await) { await(); stop(); } }通過「關閉鉤子」,就是當 JVM 關閉的時候做一些清理工作,比如說釋放線程池,清理一些零時文件,刷新內存數據到磁盤中…...
「關閉鉤子」本質就是一個線程,JVM 在停止之前會嘗試執行這個線程。我們來看下 CatalinaShutdownHook 這個鉤子到底做了什么。
/** * Shutdown hook which will perform a clean shutdown of Catalina if needed. */ protected class CatalinaShutdownHook extends Thread { @Override public void run() { try { if (getServer() != null) { Catalina.this.stop(); } } catch (Throwable ex) { ... } } /** * 關閉已經創建的 Server 實例 */ public void stop() { try { // Remove the ShutdownHook first so that server.stop() // doesn't get invoked twice if (useShutdownHook) { Runtime.getRuntime().removeShutdownHook(shutdownHook); } } catch (Throwable t) { ...... } // 關閉 Server try { Server s = getServer(); LifecycleState sstate = s.getState(); // 判斷是否已經關閉,若是在關閉中,則不執行任何操作 if (LifecycleState.STOPPING_PREP.compareTo(state) <= 0 && LifecycleState.DESTROYED.compareTo(state) >= 0) { // Nothing to do. stop() was already called } else { s.stop(); s.destroy(); } } catch (LifecycleException e) { log.error("Catalina.stop", e); } }實際上就是執行了 Server 的 stop 方法,Server 的 stop 方法會釋放和清理所有的資源。
Server 組件
來體會下面向接口設計美,看 Tomcat 如何設計組件與接口,抽象 Server 組件,Server 組件需要生命周期管理,所以繼承 Lifecycle 實現一鍵啟停。
它的具體實現類是 StandardServer,如下圖所示,我們知道 Lifecycle 主要的方法是組件的 初始化、啟動、停止、銷毀,和 監聽器的管理維護,其實就是觀察者模式的設計,當觸發不同事件的時候發布事件給監聽器執行不同業務處理,這里就是如何解耦的設計哲學體現。
而 Server 自生則是負責管理 Service 組件。
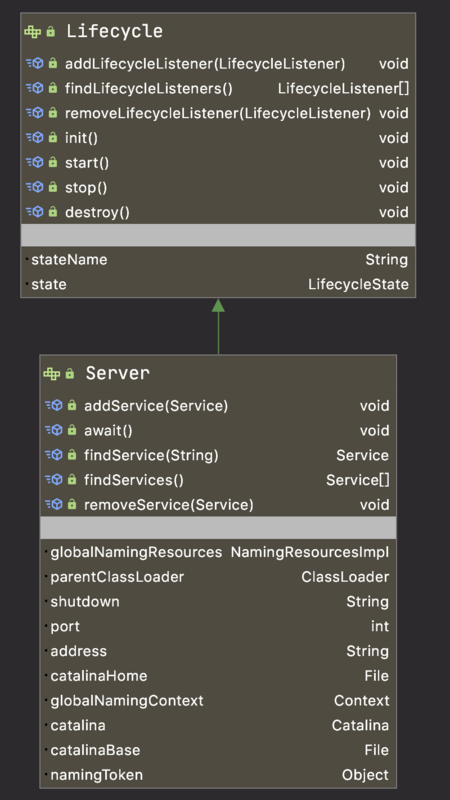
接著,我們再看 Server 組件的具體實現類是 StandardServer 有哪些功能,又跟哪些類關聯?
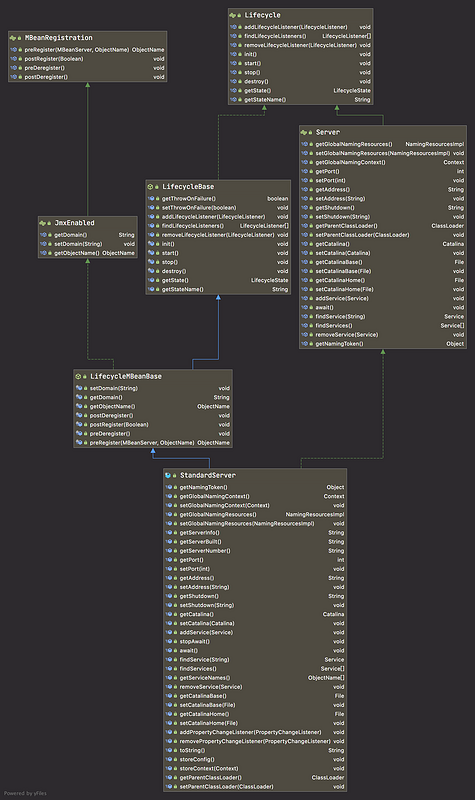
在閱讀源碼的過程中,我們一定要多關注接口與抽象類,接口是組件全局設計的抽象;而抽象類基本上是模板方法模式的運用,主要目的就是抽象整個算法流程,將變化點交給子類,將不變點實現代碼復用。
StandardServer 繼承了 LifeCycleBase,它的生命周期被統一管理,并且它的子組件是 Service,因此它還需要管理 Service 的生命周期,也就是說在啟動時調用 Service 組件的啟動方法,在停止時調用它們的停止方法。Server 在內部維護了若干 Service 組件,它是以數組來保存的,那 Server 是如何添加一個 Service 到數組中的呢?
/** * 添加 Service 到定義的數組中 * * @param service The Service to be added */ @Override public void addService(Service service) { service.setServer(this); synchronized (servicesLock) { // 創建一個 services.length + 1 長度的 results 數組 Service results[] = new Service[services.length + 1]; // 將老的數據復制到 results 數組 System.arraycopy(services, 0, results, 0, services.length); results[services.length] = service; services = results; // 啟動 Service 組件 if (getState().isAvailable()) { try { service.start(); } catch (LifecycleException e) { // Ignore } } // 觀察者模式運用,觸發監聽事件 support.firePropertyChange("service", null, service); } }從上面的代碼可以知道,并不是一開始就分配一個很長的數組,而是在新增過程中動態拓展長度,這里就是為了節省空間,對于我們平時開發是不是也要主要空間復雜度帶來的內存損耗,追求的就是極致的美。
除此之外,還有一個重要功能,上面 Caralina 的啟動方法的最后一行代碼就是調用了 Server 的 await 方法。
這個方法主要就是監聽停止端口,在 await 方法里會創建一個 Socket 監聽 8005 端口,并在一個死循環里接收 Socket 上的連接請求,如果有新的連接到來就建立連接,然后從 Socket 中讀取數據;如果讀到的數據是停止命令“SHUTDOWN”,就退出循環,進入 stop 流程。
Service
同樣是面向接口設計,Service 組件的具體實現類是 StandardService,Service 組件依然是繼承 Lifecycle 管理生命周期,這里不再累贅展示圖片關系圖。我們先來看看 Service 接口主要定義的方法以及成員變量。通過接口我們才能知道核心功能,在閱讀源碼的時候一定要多關注每個接口之間的關系,不要急著進入實現類。
public interface Service extends Lifecycle { // ----------主要成員變量 //Service 組件包含的頂層容器 Engine public Engine getContainer(); // 設置 Service 的 Engine 容器 public void setContainer(Engine engine); // 該 Service 所屬的 Server 組件 public Server getServer(); // --------------------------------------------------------- Public Methods // 添加 Service 關聯的連接器 public void addConnector(Connector connector); public Connector[] findConnectors(); // 自定義線程池 public void addExecutor(Executor ex); // 主要作用就是根據 url 定位到 Service,Mapper 的主要作用就是用于定位一個請求所在的組件處理 Mapper getMapper(); }接著再來細看 Service 的實現類:
public class StandardService extends LifecycleBase implements Service { // 名字 private String name = null; //Server 實例 private Server server = null; // 連接器數組 protected Connector connectors[] = new Connector[0]; private final Object connectorsLock = new Object(); // 對應的 Engine 容器 private Engine engine = null; // 映射器及其監聽器,又是觀察者模式的運用 protected final Mapper mapper = new Mapper(); protected final MapperListener mapperListener = new MapperListener(this); }StandardService 繼承了 LifecycleBase 抽象類,抽象類定義了 三個 final 模板方法定義生命周期,每個方法將變化點定義抽象方法讓不同組件時間自己的流程。這里也是我們學習的地方,利用模板方法抽象變與不變。
此外 StandardService 中還有一些我們熟悉的組件,比如 Server、Connector、Engine 和 Mapper。
那為什么還有一個 MapperListener?這是因為 Tomcat 支持熱部署,當 Web 應用的部署發生變化時,Mapper 中的映射信息也要跟著變化,MapperListener 就是一個監聽器,它監聽容器的變化,并把信息更新到 Mapper 中,這是典型的觀察者模式。下游服務根據多上游服務的動作做出不同處理,這就是觀察者模式的運用場景,實現一個事件多個監聽器觸發,事件發布者不用調用所有下游,而是通過觀察者模式觸發達到解耦。
Service 管理了 連接器以及 Engine 頂層容器,所以繼續進入它的 startInternal 方法,其實就是 LifecycleBase 模板定義的 抽象方法。看看他是怎么啟動每個組件順序。
protected void startInternal() throws LifecycleException { //1. 觸發啟動監聽器 setState(LifecycleState.STARTING); //2. 先啟動 Engine,Engine 會啟動它子容器,因為運用了組合模式,所以每一層容器在會先啟動自己的子容器。 if (engine != null) { synchronized (engine) { engine.start(); } } //3. 再啟動 Mapper 監聽器 mapperListener.start(); //4. 最后啟動連接器,連接器會啟動它子組件,比如 Endpoint synchronized (connectorsLock) { for (Connector connector: connectors) { if (connector.getState() != LifecycleState.FAILED) { connector.start(); } } } }Service 先啟動了 Engine 組件,再啟動 Mapper 監聽器,最后才是啟動連接器。這很好理解,因為內層組件啟動好了才能對外提供服務,才能啟動外層的連接器組件。而 Mapper 也依賴容器組件,容器組件啟動好了才能監聽它們的變化,因此 Mapper 和 MapperListener 在容器組件之后啟動。組件停止的順序跟啟動順序正好相反的,也是基于它們的依賴關系。
Engine
作為 Container 的頂層組件,所以 Engine 本質就是一個容器,繼承了 ContainerBase ,看到抽象類再次運用了模板方法設計模式。ContainerBase 使用一個 HashMap<String, Container> children = new HashMap<>(); 成員變量保存每個組件的子容器。同時使用 protected final Pipeline pipeline = new StandardPipeline(this); Pipeline 組成一個管道用于處理連接器傳過來的請求,責任鏈模式構建管道。
public class StandardEngine extends ContainerBase implements Engine { }Engine 的子容器是 Host,所以 children 保存的就是 Host。
我們來看看 ContainerBase 做了什么...
initInternal 定義了容器初始化,同時創建了專門用于啟動停止容器的線程池。
startInternal:容器啟動默認實現,通過組合模式構建容器父子關系,首先獲取自己的子容器,使用 startStopExecutor 啟動子容器。
public abstract class ContainerBase extends LifecycleMBeanBase implements Container { // 提供了默認初始化邏輯 @Override protected void initInternal() throws LifecycleException { BlockingQueue<Runnable> startStopQueue = new LinkedBlockingQueue<>(); // 創建線程池用于啟動或者停止容器 startStopExecutor = new ThreadPoolExecutor( getStartStopThreadsInternal(), getStartStopThreadsInternal(), 10, TimeUnit.SECONDS, startStopQueue, new StartStopThreadFactory(getName() + "-startStop-")); startStopExecutor.allowCoreThreadTimeOut(true); super.initInternal(); } // 容器啟動 @Override protected synchronized void startInternal() throws LifecycleException { // 獲取子容器并提交到線程池啟動 Container children[] = findChildren(); List<Future<Void>> results = new ArrayList<>(); for (Container child : children) { results.add(startStopExecutor.submit(new StartChild(child))); } MultiThrowable multiThrowable = null; // 獲取啟動結果 for (Future<Void> result : results) { try { result.get(); } catch (Throwable e) { log.error(sm.getString("containerBase.threadedStartFailed"), e); if (multiThrowable == null) { multiThrowable = new MultiThrowable(); } multiThrowable.add(e); } } ...... // 啟動 pipeline 管道,用于處理連接器傳遞過來的請求 if (pipeline instanceof Lifecycle) { ((Lifecycle) pipeline).start(); } // 發布啟動事件 setState(LifecycleState.STARTING); // Start our thread threadStart(); } }繼承了 LifecycleMBeanBase 也就是還實現了生命周期的管理,提供了子容器默認的啟動方式,同時提供了對子容器的 CRUD 功能。
Engine 在啟動 Host 容器就是 使用了 ContainerBase 的 startInternal 方法。Engine 自己還做了什么呢?
我們看下 構造方法,pipeline 設置了 setBasic,創建了 StandardEngineValve。
/** * Create a new StandardEngine component with the default basic Valve. */ public StandardEngine() { super(); pipeline.setBasic(new StandardEngineValve()); ..... }容器主要的功能就是處理請求,把請求轉發給某一個 Host 子容器來處理,具體是通過 Valve 來實現的。每個容器組件都有一個 Pipeline 用于組成一個責任鏈傳遞請求。而 Pipeline 中有一個基礎閥(Basic Valve),而 Engine 容器的基礎閥定義如下:
final class StandardEngineValve extends ValveBase { @Override public final void invoke(Request request, Response response) throws IOException, ServletException { // 選擇一個合適的 Host 處理請求,通過 Mapper 組件獲取到合適的 Host Host host = request.getHost(); if (host == null) { response.sendError (HttpServletResponse.SC_BAD_REQUEST, sm.getString("standardEngine.noHost", request.getServerName())); return; } if (request.isAsyncSupported()) { request.setAsyncSupported(host.getPipeline().isAsyncSupported()); } // 獲取 Host 容器的 Pipeline first Valve ,將請求轉發到 Host host.getPipeline().getFirst().invoke(request, response); }這個基礎閥實現非常簡單,就是把請求轉發到 Host 容器。處理請求的 Host 容器對象是從請求中拿到的,請求對象中怎么會有 Host 容器呢?這是因為請求到達 Engine 容器中之前,Mapper 組件已經對請求進行了路由處理,Mapper 組件通過請求的 URL 定位了相應的容器,并且把容器對象保存到了請求對象中。
組件設計總結
大家有沒有發現,Tomcat 的設計幾乎都是面向接口設計,也就是通過接口隔離功能設計其實就是單一職責的體現,每個接口抽象對象不同的組件,通過抽象類定義組件的共同執行流程。單一職責四個字的含義其實就是在這里體現出來了。在分析過程中,我們看到了觀察者模式、模板方法模式、組合模式、責任鏈模式以及如何抽象組件面向接口設計的設計哲學。
連接器之 I/O 模型與線程池設計
連接器主要功能就是接受 TCP/IP 連接,限制連接數然后讀取數據,最后將請求轉發到 Container 容器。所以這里必然涉及到 I/O 編程,今天帶大家一起分析 Tomcat 如何運用 I/O 模型實現高并發的,一起進入 I/O 的世界。
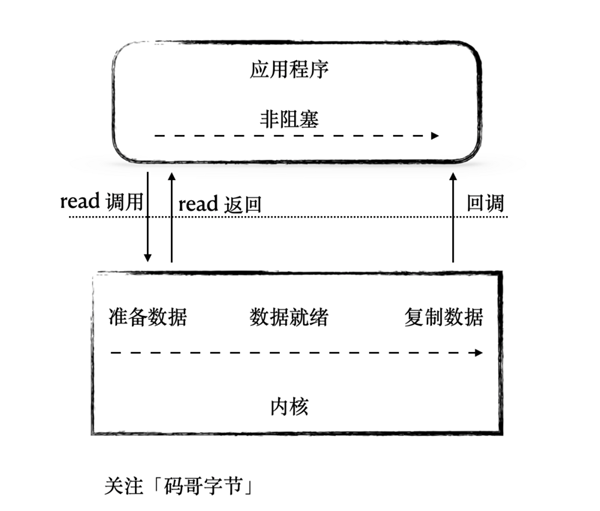
I/O 模型主要有 5 種:同步阻塞、同步非阻塞、I/O 多路復用、信號驅動、異步 I/O。是不是很熟悉但是又傻傻分不清他們有何區別?
所謂的I/O 就是計算機內存與外部設備之間拷貝數據的過程。
CPU 是先把外部設備的數據讀到內存里,然后再進行處理。請考慮一下這個場景,當程序通過 CPU 向外部設備發出一個讀指令時,數據從外部設備拷貝到內存往往需要一段時間,這個時候 CPU 沒事干了,程序是主動把 CPU 讓給別人?還是讓 CPU 不停地查:數據到了嗎,數據到了嗎……
這就是 I/O 模型要解決的問題。今天我會先說說各種 I/O 模型的區別,然后重點分析 Tomcat 的 NioEndpoint 組件是如何實現非阻塞 I/O 模型的。
I/O 模型
一個網絡 I/O 通信過程,比如網絡數據讀取,會涉及到兩個對象,分別是調用這個 I/O 操作的用戶線程和操作系統內核。一個進程的地址空間分為用戶空間和內核空間,用戶線程不能直接訪問內核空間。
網絡讀取主要有兩個步驟:
用戶線程等待內核將數據從網卡復制到內核空間。
內核將數據從內核空間復制到用戶空間。
同理,將數據發送到網絡也是一樣的流程,將數據從用戶線程復制到內核空間,內核空間將數據復制到網卡發送。
不同 I/O 模型的區別:實現這兩個步驟的方式不一樣。
對于同步,則指的應用程序調用一個方法是否立馬返回,而不需要等待。
對于阻塞與非阻塞:主要就是數據從內核復制到用戶空間的讀寫操作是否是阻塞等待的。
同步阻塞 I/O
用戶線程發起read調用的時候,線程就阻塞了,只能讓出 CPU,而內核則等待網卡數據到來,并把數據從網卡拷貝到內核空間,當內核把數據拷貝到用戶空間,再把剛剛阻塞的讀取用戶線程喚醒,兩個步驟的線程都是阻塞的。

同步非阻塞
用戶線程一直不停的調用read方法,如果數據還沒有復制到內核空間則返回失敗,直到數據到達內核空間。用戶線程在等待數據從內核空間復制到用戶空間的時間里一直是阻塞的,等數據到達用戶空間才被喚醒。循環調用read方法的時候不阻塞。
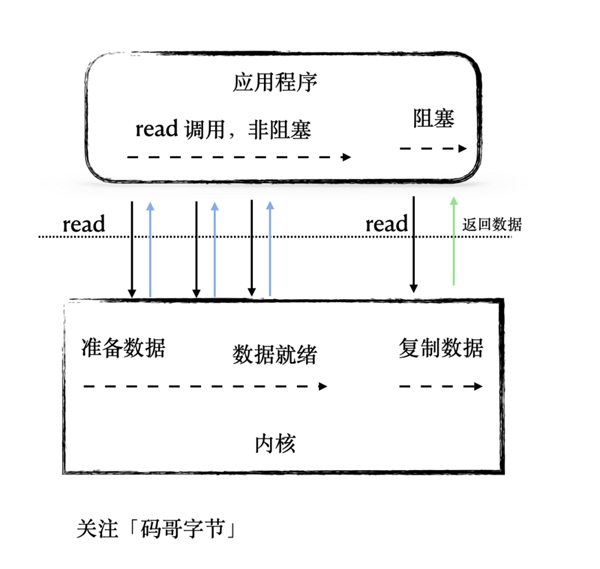
I/O 多路復用
用戶線程的讀取操作被劃分為兩步:
鴻蒙官方戰略合作共建——HarmonyOS技術社區
用戶線程先發起 select 調用,主要就是詢問內核數據轉備好了沒?當內核把數據準備好了就執行第二步。
用戶線程再發起 read 調用,在等待內核把數據從內核空間復制到用戶空間的時間里,發起 read 線程是阻塞的。
為何叫 I/O 多路復用,核心主要就是:一次 select 調用可以向內核查詢多個數據通道(Channel)的狀態,因此叫多路復用。
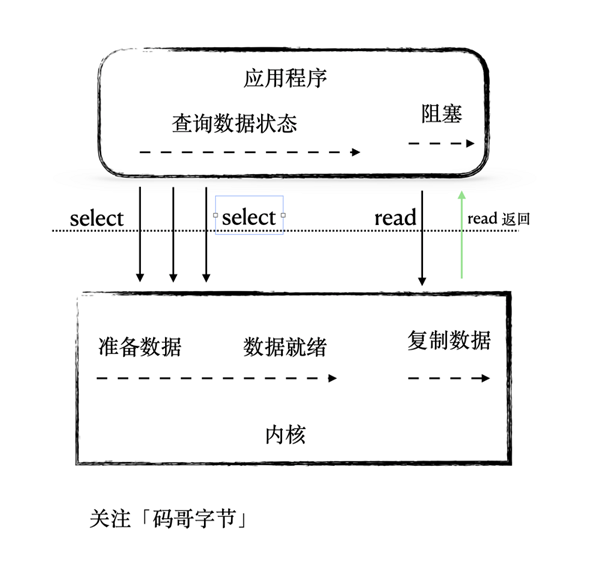
異步 I/O
用戶線程執行 read 調用的時候會注冊一個回調函數, read 調用立即返回,不會阻塞線程,在等待內核將數據準備好以后,再調用剛剛注冊的回調函數處理數據,在整個過程中用戶線程一直沒有阻塞。
Tomcat NioEndpoint
Tomcat 的 NioEndpoit 組件實際上就是實現了 I/O 多路復用模型,正式因為這個并發能力才足夠優秀。讓我們一起窺探下 Tomcat NioEndpoint 的設計原理。
對于 Java 的多路復用器的使用,無非是兩步:
鴻蒙官方戰略合作共建——HarmonyOS技術社區
創建一個 Seletor,在它身上注冊各種感興趣的事件,然后調用 select 方法,等待感興趣的事情發生。
感興趣的事情發生了,比如可以讀了,這時便創建一個新的線程從 Channel 中讀數據。
Tomcat 的 NioEndpoint 組件雖然實現比較復雜,但基本原理就是上面兩步。我們先來看看它有哪些組件,它一共包含 LimitLatch、Acceptor、Poller、SocketProcessor 和 Executor 共 5 個組件,它們的工作過程如下圖所示:
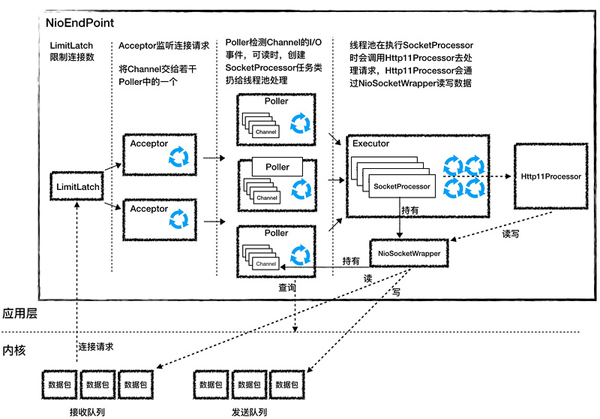
正是由于使用了 I/O 多路復用,Poller 內部本質就是持有 Java Selector 檢測 channel 的 I/O 時間,當數據可讀寫的時候創建 SocketProcessor 任務丟到線程池執行,也就是少量線程監聽讀寫事件,接著專屬的線程池執行讀寫,提高性能。
自定義線程池模型
為了提高處理能力和并發度, Web 容器通常會把處理請求的工作放在線程池來處理, Tomcat 拓展了 Java 原生的線程池來提升并發需求,在進入 Tomcat 線程池原理之前,我們先回顧下 Java 線程池原理。
Java 線程池
簡單的說,Java 線程池里內部維護一個線程數組和一個任務隊列,當任務處理不過來的時,就把任務放到隊列里慢慢處理。
ThreadPoolExecutor
來窺探線程池核心類的構造函數,我們需要理解每一個參數的作用,才能理解線程池的工作原理。
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) { ...... }corePoolSize:保留在池中的線程數,即使它們空閑,除非設置了 allowCoreThreadTimeOut,不然不會關閉。
maximumPoolSize:隊列滿后池中允許的最大線程數。
keepAliveTime、TimeUnit:如果線程數大于核心數,多余的空閑線程的保持的最長時間會被銷毀。unit 是 keepAliveTime 參數的時間單位。當設置 allowCoreThreadTimeOut(true) 時,線程池中 corePoolSize 范圍內的線程空閑時間達到 keepAliveTime 也將回收。
workQueue:當線程數達到 corePoolSize 后,新增的任務就放到工作隊列 workQueue 里,而線程池中的線程則努力地從 workQueue 里拉活來干,也就是調用 poll 方法來獲取任務。
ThreadFactory:創建線程的工廠,比如設置是否是后臺線程、線程名等。
RejectedExecutionHandler:拒絕策略,處理程序因為達到了線程界限和隊列容量執行拒絕策略。也可以自定義拒絕策略,只要實現 RejectedExecutionHandler 即可。默認的拒絕策略:AbortPolicy 拒絕任務并拋出 RejectedExecutionException 異常;CallerRunsPolicy 提交該任務的線程執行;``
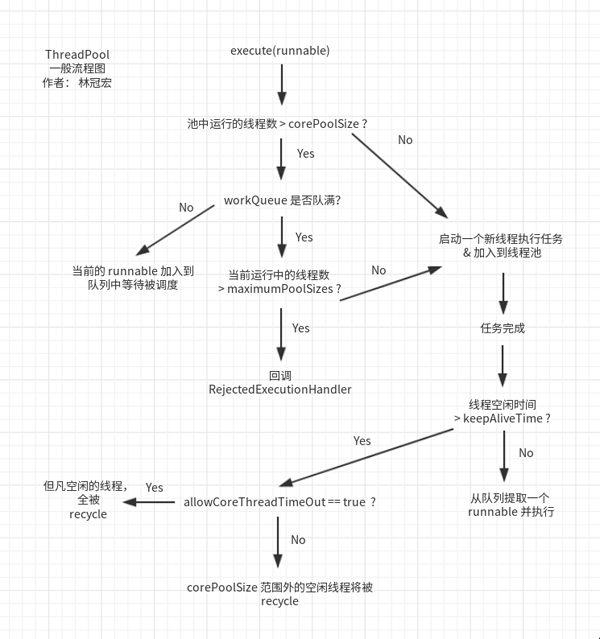
來分析下每個參數之間的關系:
提交新任務的時候,如果線程池數 < corePoolSize,則創建新的線程池執行任務,當線程數 = corePoolSize 時,新的任務就會被放到工作隊列 workQueue 中,線程池中的線程盡量從隊列里取任務來執行。
如果任務很多,workQueue 滿了,且 當前線程數 < maximumPoolSize 時則臨時創建線程執行任務,如果總線程數量超過 maximumPoolSize,則不再創建線程,而是執行拒絕策略。DiscardPolicy 什么都不做直接丟棄任務;DiscardOldestPolicy 丟棄最舊的未處理程序;
具體執行流程如下圖所示:
Tomcat 線程池
定制版的 ThreadPoolExecutor,繼承了 java.util.concurrent.ThreadPoolExecutor。 對于線程池有兩個很關鍵的參數:
線程個數。
隊列長度。
Tomcat 必然需要限定想著兩個參數不然在高并發場景下可能導致 CPU 和內存有資源耗盡的風險。繼承了 與 java.util.concurrent.ThreadPoolExecutor 相同,但實現的效率更高。
其構造方法如下,跟 Java 官方的如出一轍
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, RejectedExecutionHandler handler) { super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, handler); prestartAllCoreThreads(); }在 Tomcat 中控制線程池的組件是 StandardThreadExecutor , 也是實現了生命周期接口,下面是啟動線程池的代碼
@Override protected void startInternal() throws LifecycleException { // 自定義任務隊列 taskqueue = new TaskQueue(maxQueueSize); // 自定義線程工廠 TaskThreadFactory tf = new TaskThreadFactory(namePrefix,daemon,getThreadPriority()); // 創建定制版線程池 executor = new ThreadPoolExecutor(getMinSpareThreads(), getMaxThreads(), maxIdleTime, TimeUnit.MILLISECONDS,taskqueue, tf); executor.setThreadRenewalDelay(threadRenewalDelay); if (prestartminSpareThreads) { executor.prestartAllCoreThreads(); } taskqueue.setParent(executor); // 觀察者模式,發布啟動事件 setState(LifecycleState.STARTING); }其中的關鍵點在于:
Tomcat 有自己的定制版任務隊列和線程工廠,并且可以限制任務隊列的長度,它的最大長度是 maxQueueSize。
Tomcat 對線程數也有限制,設置了核心線程數(minSpareThreads)和最大線程池數(maxThreads)。
除此之外, Tomcat 在官方原有基礎上重新定義了自己的線程池處理流程,原生的處理流程上文已經說過。
前 corePoolSize 個任務時,來一個任務就創建一個新線程。
還有任務提交,直接放到隊列,隊列滿了,但是沒有達到最大線程池數則創建臨時線程救火。
線程總線數達到 maximumPoolSize ,直接執行拒絕策略。
Tomcat 線程池擴展了原生的 ThreadPoolExecutor,通過重寫 execute 方法實現了自己的任務處理邏輯:
前 corePoolSize 個任務時,來一個任務就創建一個新線程。
還有任務提交,直接放到隊列,隊列滿了,但是沒有達到最大線程池數則創建臨時線程救火。
線程總線數達到 maximumPoolSize ,繼續嘗試把任務放到隊列中。如果隊列也滿了,插入任務失敗,才執行拒絕策略。
最大的差別在于 Tomcat 在線程總數達到最大數時,不是立即執行拒絕策略,而是再嘗試向任務隊列添加任務,添加失敗后再執行拒絕策略。
代碼如下所示:
public void execute(Runnable command, long timeout, TimeUnit unit) { // 記錄提交任務數 +1 submittedCount.incrementAndGet(); try { // 調用 java 原生線程池來執行任務,當原生拋出拒絕策略 super.execute(command); } catch (RejectedExecutionException rx) { //總線程數達到 maximumPoolSize,Java 原生會執行拒絕策略 if (super.getQueue() instanceof TaskQueue) { final TaskQueue queue = (TaskQueue)super.getQueue(); try { // 嘗試把任務放入隊列中 if (!queue.force(command, timeout, unit)) { submittedCount.decrementAndGet(); // 隊列還是滿的,插入失敗則執行拒絕策略 throw new RejectedExecutionException("Queue capacity is full."); } } catch (InterruptedException x) { submittedCount.decrementAndGet(); throw new RejectedExecutionException(x); } } else { // 提交任務書 -1 submittedCount.decrementAndGet(); throw rx; } } }Tomcat 線程池是用 submittedCount 來維護已經提交到了線程池,這跟 Tomcat 的定制版的任務隊列有關。Tomcat 的任務隊列 TaskQueue 擴展了 Java 中的 LinkedBlockingQueue,我們知道 LinkedBlockingQueue 默認情況下長度是沒有限制的,除非給它一個 capacity。因此 Tomcat 給了它一個 capacity,TaskQueue 的構造函數中有個整型的參數 capacity,TaskQueue 將 capacity 傳給父類 LinkedBlockingQueue 的構造函數,防止無限添加任務導致內存溢出。而且默認是無限制,就會導致當前線程數達到核心線程數之后,再來任務的話線程池會把任務添加到任務隊列,并且總是會成功,這樣永遠不會有機會創建新線程了。
為了解決這個問題,TaskQueue 重寫了 LinkedBlockingQueue 的 offer 方法,在合適的時機返回 false,返回 false 表示任務添加失敗,這時線程池會創建新的線程。
public class TaskQueue extends LinkedBlockingQueue<Runnable> { ... @Override // 線程池調用任務隊列的方法時,當前線程數肯定已經大于核心線程數了 public boolean offer(Runnable o) { // 如果線程數已經到了最大值,不能創建新線程了,只能把任務添加到任務隊列。 if (parent.getPoolSize() == parent.getMaximumPoolSize()) return super.offer(o); // 執行到這里,表明當前線程數大于核心線程數,并且小于最大線程數。 // 表明是可以創建新線程的,那到底要不要創建呢?分兩種情況: //1. 如果已提交的任務數小于當前線程數,表示還有空閑線程,無需創建新線程 if (parent.getSubmittedCount()<=(parent.getPoolSize())) return super.offer(o); //2. 如果已提交的任務數大于當前線程數,線程不夠用了,返回 false 去創建新線程 if (parent.getPoolSize()<parent.getMaximumPoolSize()) return false; // 默認情況下總是把任務添加到任務隊列 return super.offer(o); } }只有當前線程數大于核心線程數、小于最大線程數,并且已提交的任務個數大于當前線程數時,也就是說線程不夠用了,但是線程數又沒達到極限,才會去創建新的線程。這就是為什么 Tomcat 需要維護已提交任務數這個變量,它的目的就是在任務隊列的長度無限制的情況下,讓線程池有機會創建新的線程。可以通過設置 maxQueueSize 參數來限制任務隊列的長度。
性能優化
線程池調優
跟 I/O 模型緊密相關的是線程池,線程池的調優就是設置合理的線程池參數。我們先來看看 Tomcat 線程池中有哪些關鍵參數:
| 參數 | 詳情 |
|---|---|
| threadPriority | 線程優先級,默認是 5 |
| daemon | 是否是 后臺線程,默認 true |
| namePrefix | 線程名前綴 |
| maxThreads | 最大線程數,默認 200 |
| minSpareThreads | 最小線程數(空閑超過一定時間會被回收),默認 25 |
| maxIdleTime | 線程最大空閑時間,超過該時間的會被回收,直到只有 minSpareThreads 個。默認是 1 分鐘 |
| maxQueueSize | 任務隊列最大長度 |
| prestartAllCoreThreads | 是否在線程池啟動的時候就創建 minSpareThreads 個線程,默認是 fasle |
這里面最核心的就是如何確定 maxThreads 的值,如果這個參數設置小了,Tomcat 會發生線程饑餓,并且請求的處理會在隊列中排隊等待,導致響應時間變長;如果 maxThreads 參數值過大,同樣也會有問題,因為服務器的 CPU 的核數有限,線程數太多會導致線程在 CPU 上來回切換,耗費大量的切換開銷。
線程 I/O 時間與 CPU 時間
至此我們又得到一個線程池個數的計算公式,假設服務器是單核的:
線程池大小 = (線程 I/O 阻塞時間 + 線程 CPU 時間 )/ 線程 CPU 時間
其中:線程 I/O 阻塞時間 + 線程 CPU 時間 = 平均請求處理時間。
Tomcat 內存溢出的原因分析及調優
JVM 在拋出 java.lang.OutOfMemoryError 時,除了會打印出一行描述信息,還會打印堆棧跟蹤,因此我們可以通過這些信息來找到導致異常的原因。在尋找原因前,我們先來看看有哪些因素會導致 OutOfMemoryError,其中內存泄漏是導致 OutOfMemoryError 的一個比較常見的原因。
其實調優很多時候都是在找系統瓶頸,假如有個狀況:系統響應比較慢,但 CPU 的用率不高,內存有所增加,通過分析 Heap Dump 發現大量請求堆積在線程池的隊列中,請問這種情況下應該怎么辦呢?可能是請求處理時間太長,去排查是不是訪問數據庫或者外部應用遇到了延遲。
java.lang.OutOfMemoryError: Java heap space
當 JVM 無法在堆中分配對象的會拋出此異常,一般有以下原因:
內存泄漏:本該回收的對象唄程序一直持有引用導致對象無法被回收,比如在線程池中使用 ThreadLocal、對象池、內存池。為了找到內存泄漏點,我們通過 jmap 工具生成 Heap Dump,再利用 MAT 分析找到內存泄漏點。jmap -dump:live,format=b,file=filename.bin pid
2. 內存不足:我們設置的堆大小對于應用程序來說不夠,修改 JVM 參數調整堆大小,比如 -Xms256m -Xmx2048m。
3. finalize 方法的過度使用。如果我們想在 Java 類實例被 GC 之前執行一些邏輯,比如清理對象持有的資源,可以在 Java 類中定義 finalize 方法,這樣 JVM GC 不會立即回收這些對象實例,而是將對象實例添加到一個叫“java.lang.ref.Finalizer.ReferenceQueue”的隊列中,執行對象的 finalize 方法,之后才會回收這些對象。Finalizer 線程會和主線程競爭 CPU 資源,但由于優先級低,所以處理速度跟不上主線程創建對象的速度,因此 ReferenceQueue 隊列中的對象就越來越多,最終會拋出 OutOfMemoryError。解決辦法是盡量不要給 Java 類定義 finalize 方法。
java.lang.OutOfMemoryError: GC overhead limit exceeded
垃圾收集器持續運行,但是效率很低幾乎沒有回收內存。比如 Java 進程花費超過 96%的 CPU 時間來進行一次 GC,但是回收的內存少于 3%的 JVM 堆,并且連續 5 次 GC 都是這種情況,就會拋出 OutOfMemoryError。
這個問題 IDE 解決方法就是查看 GC 日志或者生成 Heap Dump,先確認是否是內存溢出,不是的話可以嘗試增加堆大小。可以通過如下 JVM 啟動參數打印 GC 日志:
-verbose:gc //在控制臺輸出GC情況 -XX:+PrintGCDetails //在控制臺輸出詳細的GC情況 -Xloggc: filepath //將GC日志輸出到指定文件中
比如 可以使用 java -verbose:gc -Xloggc:gc.log -XX:+PrintGCDetails -jar xxx.jar 記錄 GC 日志,通過 GCViewer 工具查看 GC 日志,用 GCViewer 打開產生的 gc.log 分析垃圾回收情況。
java.lang.OutOfMemoryError: Requested array size exceeds VM limit
拋出這種異常的原因是“請求的數組大小超過 JVM 限制”,應用程序嘗試分配一個超大的數組。比如程序嘗試分配 128M 的數組,但是堆最大 100M,一般這個也是配置問題,有可能 JVM 堆設置太小,也有可能是程序的 bug,是不是創建了超大數組。
java.lang.OutOfMemoryError: MetaSpace
JVM 元空間的內存在本地內存中分配,但是它的大小受參數 MaxMetaSpaceSize 的限制。當元空間大小超過 MaxMetaSpaceSize 時,JVM 將拋出帶有 MetaSpace 字樣的 OutOfMemoryError。解決辦法是加大 MaxMetaSpaceSize 參數的值。
java.lang.OutOfMemoryError: Request size bytes for reason. Out of swap space
當本地堆內存分配失敗或者本地內存快要耗盡時,Java HotSpot VM 代碼會拋出這個異常,VM 會觸發“致命錯誤處理機制”,它會生成“致命錯誤”日志文件,其中包含崩潰時線程、進程和操作系統的有用信息。如果碰到此類型的 OutOfMemoryError,你需要根據 JVM 拋出的錯誤信息來進行診斷;或者使用操作系統提供的 DTrace 工具來跟蹤系統調用,看看是什么樣的程序代碼在不斷地分配本地內存。
java.lang.OutOfMemoryError: Unable to create native threads
Java 程序向 JVM 請求創建一個新的 Java 線程。
JVM 本地代碼(Native Code)代理該請求,通過調用操作系統 API 去創建一個操作系統級別的線程 Native Thread。
操作系統嘗試創建一個新的 Native Thread,需要同時分配一些內存給該線程,每一個 Native Thread 都有一個線程棧,線程棧的大小由 JVM 參數-Xss決定。
由于各種原因,操作系統創建新的線程可能會失敗,下面會詳細談到。
JVM 拋出“java.lang.OutOfMemoryError: Unable to create new native thread”錯誤。
這里只是概述場景,對于生產在線排查后續會陸續推出,受限于篇幅不再展開。關注「碼哥字節」給你硬貨來啃!
到此,關于“Tomcat高并發之如何理解道與性能調優”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





