溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Python中怎么實現一個多層感知器神經網絡,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
強大的庫已經存在了,如:TensorFlow,PyTorch,Keras等等。我將介紹在Python中創建多層感知器(MLP)神經網絡的基本知識。
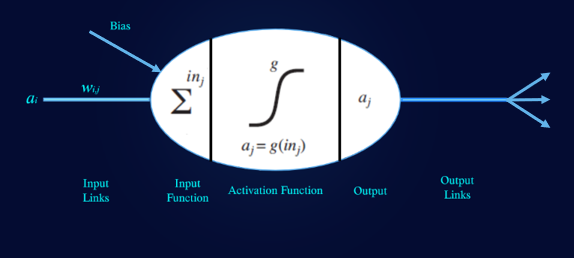
感知器是神經網絡的基本組成部分。感知器的輸入函數是權重,偏差和輸入數據的線性組合。具體來說:in_j = weight input + bias.(in_j =權重輸入+偏差)。在每個感知器上,我們都可以指定一個激活函數g。
激活函數是一種確保感知器“發射”或僅在達到一定輸入水平后才激活的數學方法。常見的非線性激活函數為S型,softmax,整流線性單位(ReLU)或簡單的tanH。
激活函數有很多選項,但是在本文中我們僅涉及Sigmoid和softmax。
圖1:感知器
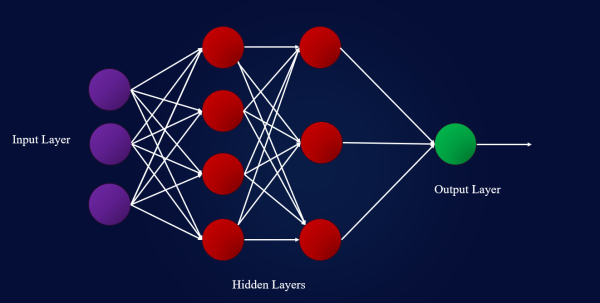
對于有監督的學習,我們稍后將輸入的數據通過一系列隱藏層轉發到輸出層。這稱為前向傳播。在輸出層,我們能夠輸出預測y。通過我們的預測y,我們可以計算誤差| y*-y | 并使誤差通過神經網絡向后傳播。這稱為反向傳播。通過隨機梯度下降(SGD)過程,將更新隱藏層中每個感知器的權重和偏差。
圖2:神經網絡的基本結構
現在我們已經介紹了基礎知識,讓我們實現一個神經網絡。我們的神經網絡的目標是對MNIST數據庫中的手寫數字進行分類。我將使用NumPy庫進行基本矩陣計算。
在我們的問題中,MNIST數據由 [748,1] 矩陣中的8位顏色通道表示。從本質上講,我們有一個 [748,1] 的數字矩陣,其始于[0,1,.... 255],其中0表示白色,255表示黑色。
結果
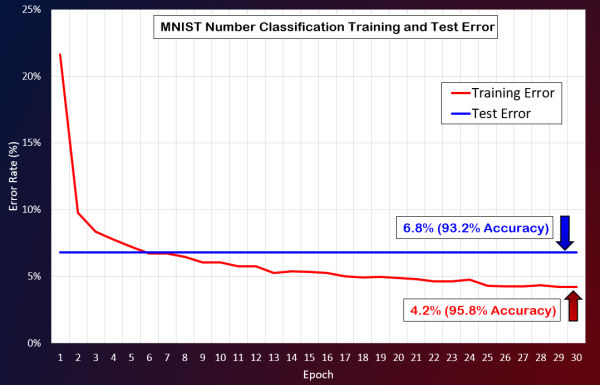
MNIST手寫數字數據庫包含60,000個用于訓練目的的手寫示例和10,000個用于測試目的的示例。在對60,000個示例進行了30個epoch的訓練之后,我在測試數據集上運行了經過訓練的神經網絡,并達到了93.2%的準確性。甚至可以通過調整超參數來進一步優化。
它是如何工作的?
本文分為5個部分。這些部分是:
鴻蒙官方戰略合作共建——HarmonyOS技術社區
激活函數
權重初始化
偏差初始化
訓練算法
進行預測
1. 激活函數
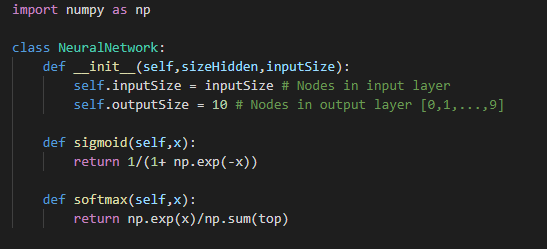
Sigmoid是由等式1 /(1+ exp(-x))定義的激活函數,將在隱藏層感知器中使用。
Softmax是一個激活函數,當我們要將輸入分為幾類時,它通常在輸出層中使用。在我們的例子中,我們希望將一個數字分成10個bucket[0,1,2,…,9]中的一個。它計算矩陣中每個條目的概率;概率將總計為1。具有最大概率的條目將對應于其預測,即0,1,…,9。Softmax定義為exp(x)/ sum(exp(x))。
圖3:激活函數的實現
2. 權重初始化
對于我們的每個隱藏層,我們將需要初始化權重矩陣。有幾種不同的方法可以做到這一點,這里是4。
零初始化-初始化所有權重= 0。
隨機初始化-使用隨機數初始化權重,而不是完全隨機。我們通常使用標準正態分布(均值0和方差1)中的隨機數。
Xavier初始化-使用具有設定方差的正態分布中的隨機數初始化權重。我們將基于上一層的大小設置方差。
如上所述,進入感知器的邊緣乘以權重矩陣。關鍵的一點是,矩陣的大小取決于當前圖層的大小以及它之前的圖層。明確地,權重矩陣的大小為[currentLayerSize,previousLayerSize]。
如上所述,進入感知器的邊緣乘以權重矩陣。關鍵的一點是,矩陣的大小取決于當前圖層的大小以及它之前的圖層。明確地,權重矩陣的大小為[currentLayerSize,previousLayerSize]。
假設我們有一個包含100個節點的隱藏層。我們的輸入層的大小為[748,1],而我們所需的輸出層的大小為[10,1]。輸入層和第一個隱藏層之間的權重矩陣的大小為[100,748]。隱藏層之間的每個權重矩陣的大小為[100,100]。最后,最終隱藏層和輸出層之間的權重矩陣的大小為[10,100]。
出于教育目的,我們將堅持使用單個隱藏層;在最終模型中,我們將使用多層。
圖4:權重初始化實現
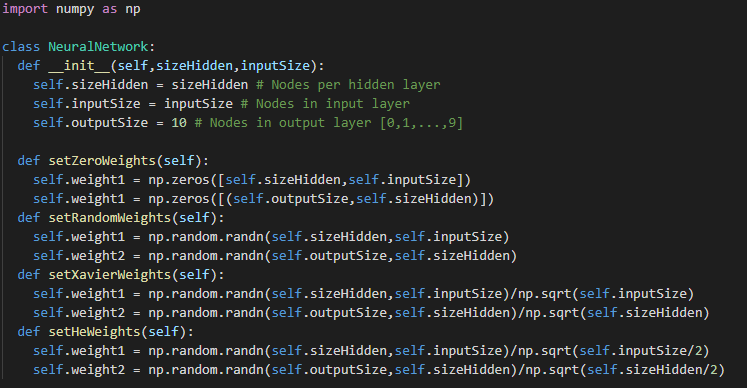
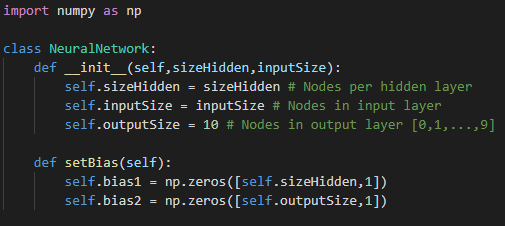
3. 偏差初始化
像權重初始化一樣,偏置矩陣的大小取決于圖層大小,尤其是當前圖層大小。偏置初始化的一種方法是將偏置設置為零。
對于我們的實現,我們將需要為每個隱藏層和輸出層提供一個偏差。偏置矩陣的大小為[100,1],基于每個隱藏層100個節點,而輸出層的大小為[10,1]。
圖5:偏置初始化實現
4. 訓練算法
前面已經說過,訓練是基于隨機梯度下降(SGD)的概念。在SGD中,我們一次只考慮一個訓練點。
在我們的示例中,我們將在輸出層使用softmax激活。將使用“交叉熵損失”公式來計算損失。對于SGD,我們將需要使用softmax來計算交叉熵損失的導數。也就是說,此導數減少為y -y,即預測y減去期望值y。
圖6:關于softmax激活的交叉熵損失及其導數
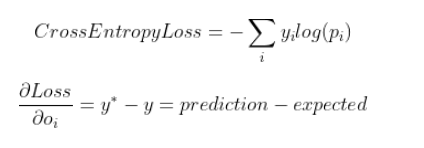
我們還需要編寫S型激活函數的導數。在圖7中,我定義了S型函數及其衍生函數
圖7:Sigmoid函數(上)及其導數(下)
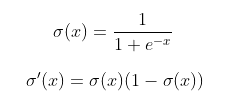
通常,神經網絡將允許用戶指定幾個“超參數”。在我們的實施中,我們將著重于允許用戶指定epoch,批處理大小,學習率和動量。還有其他優化技術!
學習率(LR):學習率是一個參數,用戶可以通過它指定網絡允許我們學習和更新其參數的速度。選擇一個好的學習率是一門藝術。如果LR太高,我們可能永遠不會收斂于良好的可接受的訓練錯誤。如果LR太低,我們可能會浪費大量的計算時間。
epoch:epoch是整個訓練集中的一個迭代。為了確保我們不會過度擬合早期樣本中的數據,我們會在每個時期之后對數據進行隨機排序。
批次大小:通過Epoc2h的每次迭代,我們將分批訓練數據。對于批次中的每個訓練點,我們將收集梯度,并在批次完成后更新權重/偏差。
動量:這是一個參數,我們將通過收集過去的梯度的移動平均值并允許在該方向上的運動來加速學習。在大多數情況下,這將導致更快的收斂。典型值范圍從0.5到0.9。
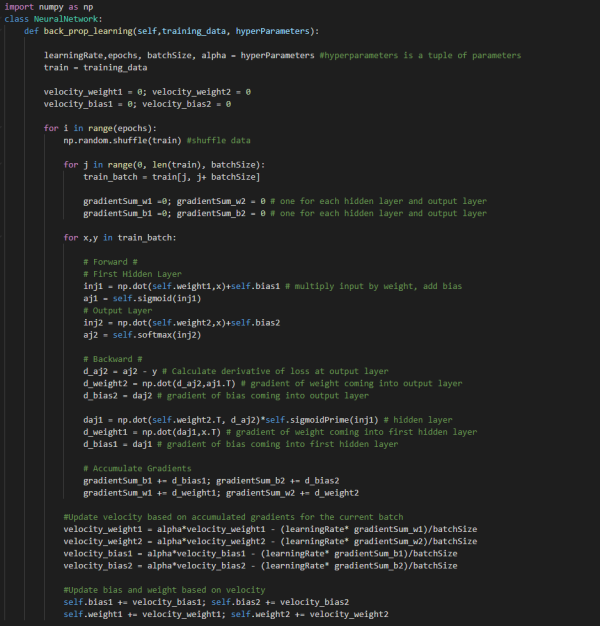
下面,我編寫了一些通用的偽代碼來模擬反向傳播學習算法的概況。為了便于閱讀,已將諸如計算輸出和將訓練數據分成批次之類的任務作為注釋編寫。

現在,我們將展示偽代碼的實現.
5. 做出預測
現在,我們僅缺少此實現的一個關鍵方面。預測算法。在編寫反向傳播算法的過程中,我們已經完成了大部分工作。我們只需要使用相同的前向傳播代碼即可進行預測。輸出層的softmax激活函數將計算大小為[10,1]的矩陣中每個條目的概率。
我們的目標是將數字分類為0到9。因此,aj2矩陣的索引將與預測相對應。概率最大的索引將由np.argmax()選擇,并將作為我們的預測。
關于Python中怎么實現一個多層感知器神經網絡就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





