溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“如何理解if-else涉及到分支預測”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“如何理解if-else涉及到分支預測”吧!
首先看一段經典的代碼,并統計它的執行時間:
// test_predict.cc #include <algorithm> #include <ctime> #include <iostream> int main() { const unsigned ARRAY_SIZE = 50000; int data[ARRAY_SIZE]; const unsigned DATA_STRIDE = 256; for (unsigned c = 0; c < ARRAY_SIZE; ++c) data[c] = std::rand() % DATA_STRIDE; std::sort(data, data + ARRAY_SIZE); { // 測試部分 clock_t start = clock(); long long sum = 0; for (unsigned i = 0; i < 100000; ++i) { for (unsigned c = 0; c < ARRAY_SIZE; ++c) { if (data[c] >= 128) sum += data[c]; } } double elapsedTime = static_cast<double>(clock() - start) / CLOCKS_PER_SEC; std::cout << elapsedTime << "\n"; std::cout << "sum = " << sum << "\n"; } return 0; } ~/test$ g++ test_predict.cc ;./a.out 7.95312 sum = 480124300000此程序的執行時間是7.9秒,如果把排序那一行代碼注釋掉,即
// std::sort(data, data + ARRAY_SIZE);
結果為:
~/test$ g++ test_predict.cc ;./a.out 24.2188 sum = 480124300000
改動后的程序執行時間變為了24秒。
其實只改動了一行代碼,程序執行時間卻有3倍的差距,而且看上去數組是否排序與程序執行速度貌似沒什么關系,這里面其實涉及到CPU分支預測的知識點。
提到分支預測,首先要介紹一個概念:流水線。
拿理發舉例,小理發店一般都是一個人工作,一個人洗剪吹一肩挑,而大理發店分工明確,洗剪吹都有特定的員工,第一個人在剪發的時候,第二個人就可以洗頭了,第一個人剪發結束吹頭發的時候,第二個人可以去剪發,第三個人就可以去洗頭了,極大的提高了效率。

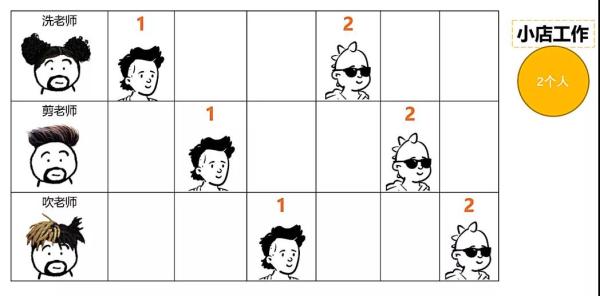
這里的洗剪吹就相當于是三級流水線,在CPU架構中也有流水線的概念,如圖:
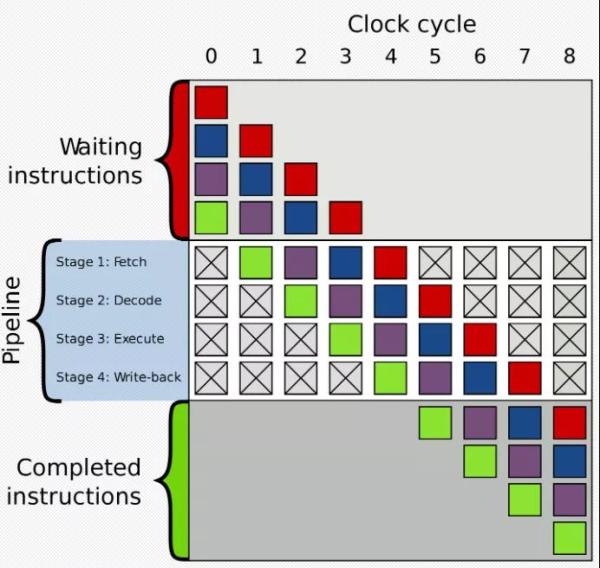
在執行指令的時候一般有以下幾個過程:
鴻蒙官方戰略合作共建——HarmonyOS技術社區
取指:Fetch
譯指:Decode
執行:execute
回寫:Write-back
流水線架構可以更好的壓榨流水線上的四個員工,讓他們不停的工作,使指令執行的效率更高。
再談分支預測,舉個經典的例子:
火車高速行駛的過程中遇到前方有個岔路口,假設火車內沒有任何通訊手段,那火車就需要在岔路口前停下,下車詢問別人應該選擇哪條路走,弄清楚路線后后再重新啟動火車繼續行駛。高速行駛的火車慢速停下,再重新啟動后加速,可以想象這個過程浪費了多少時間。
有個辦法,火車在遇到岔路口前可以猜一條路線,到路口時直接選擇這條路行駛,如果經過多個岔路口,每次做出選擇時都能選擇正確的路口行駛,這樣火車一路上都不需要減速,速度自然非常快。但如果火車開過頭才發現走錯路了,就需要倒車回到岔路口,選擇正確的路口繼續行駛,速度自然下降很多。所以預測的成功率非常重要,因為預測失敗的代價較高,預測成功則一帆風順。
計算機的分支預測就如同火車行駛中遇到了岔路口,預測成功則程序的執行效率大幅提高,預測失敗程序的執行效率則大幅下降。
CPU都是多級流水線架構運行,如果分支預測成功,很多指令都提前進入流水線流程中,則流水線中指令運行的非常順暢,而如果分支預測失敗,則需要清空流水線中的那些預測出來的指令,重新加載正確的指令到流水線中執行,然而現代CPU的流水線級數非常長,分支預測失敗會損失10-20個左右的時鐘周期,因此對于復雜的流水線,好的分支預測方法非常重要。
預測方法主要分為靜態分支預測和動態分支預測:
靜態分支預測:聽名字就知道,該策略不依賴執行環境,編譯器在編譯時就已經對各個分支做好了預測。
動態分支預測:即運行時預測,CPU會根據分支被選擇的歷史紀錄進行預測,如果最近多次都走了這個路口,那CPU做出預測時會優先考慮這個路口。
tips:這里只是簡單的介紹了分支預測的方法,更多的分支預測方法資料大家可關注公眾號回復分支預測關鍵字領取。
了解了分支預測的概念,我們回到最開始的問題,為什么同一個程序,排序和不排序的執行速度相差那么多。
因為程序中有個if條件判斷,對于不排序的程序,數據散亂分布,CPU進行分支預測比較困難,預測失敗的頻率較高,每次失敗都會浪費10-20個時鐘周期,影響程序運行的效率。而對于排序后的數據,CPU根據歷史記錄比較好判斷即將走哪個分支,大概前一半的數據都不會進入if分支,后一半的數據都會進入if分支,預測的成功率非常高,所以程序運行速度很快。
如何解決此問題?總體思路肯定是在程序中盡量減少分支的判斷,方法肯定是具體問題具體分析了,對于該示例程序,這里提供兩個思路削減if分支。
方法一:使用位操作:
int t = (data[c] - 128) >> 31; sum += ~t & data[c];
方法二:使用表結構:
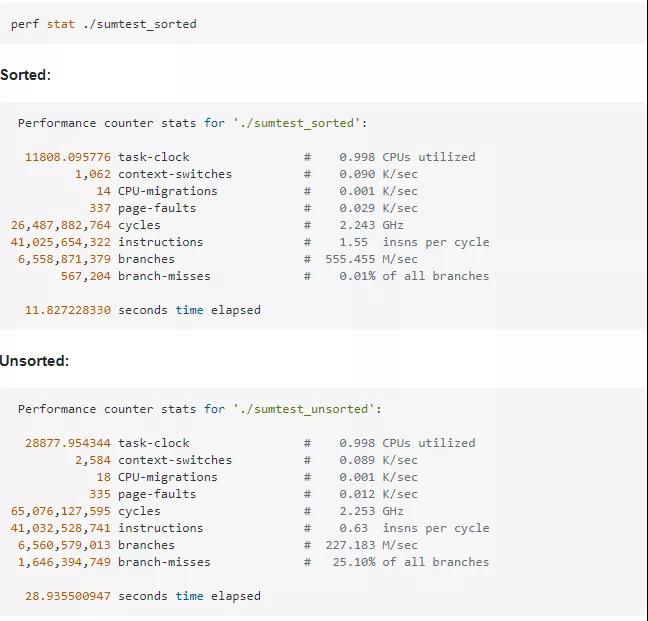
#include <algorithm> #include <ctime> #include <iostream> int main() { const unsigned ARRAY_SIZE = 50000; int data[ARRAY_SIZE]; const unsigned DATA_STRIDE = 256; for (unsigned c = 0; c < ARRAY_SIZE; ++c) data[c] = std::rand() % DATA_STRIDE; int lookup[DATA_STRIDE]; for (unsigned c = 0; c < DATA_STRIDE; ++c) { lookup[c] = (c >= 128) ? c : 0; } std::sort(data, data + ARRAY_SIZE); { // 測試部分 clock_t start = clock(); long long sum = 0; for (unsigned i = 0; i < 100000; ++i) { for (unsigned c = 0; c < ARRAY_SIZE; ++c) { // if (data[c] >= 128) sum += data[c]; sum += lookup[data[c]]; } } double elapsedTime = static_cast<double>(clock() - start) / CLOCKS_PER_SEC; std::cout << elapsedTime << "\n"; std::cout << "sum = " << sum << "\n"; } return 0; }其實Linux中有一些工具可以檢測出分支預測成功的次數,有valgrind和perf,使用方式如圖:
感謝各位的閱讀,以上就是“如何理解if-else涉及到分支預測”的內容了,經過本文的學習后,相信大家對如何理解if-else涉及到分支預測這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





