溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“一些前端基礎知識整理匯總”,在日常操作中,相信很多人在一些前端基礎知識整理匯總問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”一些前端基礎知識整理匯總”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
react 生命周期
React v16.0前的生命周期
初始化(initialization)階段
此階段只有一個生命周期方法:constructor。
constructor()
用來做一些組件的初始化工作,如定義this.state的初始內容。如果不初始化 state 或不進行方法綁定,則不需要為 React 組件實現構造函數。為什么必須先調用super(props)?因為子類自己的this對象,必須先通過父類的構造函數完成塑造,得到與父類同樣的實例屬性和方法,然后再對其進行加工,加上子類自己的實例屬性和方法。如果不調用super方法,子類就得不到this對象。
class Checkbox extends React.Component { constructor(props) { // ? 這時候還不能使用this super(props); // ? 現在開始可以使用this console.log(props); // ? {} console.log(this.props); // ? {} this.state = {}; } }為什么super要傳 props?
把 props 傳進 super 是必要的,這使得基類 React.Component 可以初始化 this.props。
然而,即便在調用 super() 時沒有傳入 props 參數,你依然能夠在 render 和其它方法中訪問 this.props。
其實是 React 在調用你的構造函數之后,馬上又給實例設置了一遍 props。
// React 內部 class Component { constructor(props) { this.props = props; // 初始化 this.props // ... } } // React 內部 const instance = new Button(props); instance.props = props; // 給實例設置 props // Button類組件 class Button extends React.Component { constructor(props) { super(); // ? 我們忘了傳入 props console.log(props); // ? {} console.log(this.props); // ? undefined } }掛載(Mounting)階段
此階段生命周期方法:componentWillMount => render => componentDidMount
1. componentWillMount():
在組件掛載到DOM前調用,且只會被調用一次。
每一個子組件render之前立即調用;
在此方法調用this.setState不會引起組件重新渲染,也可以把寫在這邊的內容提前到constructor()中。
2. render(): class 組件唯一必須實現的方法
當 render 被調用時,它會檢查 this.props 和 this.state 的變化并返回以下類型之一:
React 元素。通常通過 JSX 創建。例如,
會被 React 渲染為 DOM 節點, 會被 React 渲染為自定義組件,無論是
還是 均為 React 元素。
數組或 fragments。使得 render 方法可以返回多個元素。Fragments 允許你將子列表分組,而無需向 DOM 添加額外節點。
Portals。可以渲染子節點到不同的 DOM 子樹中。Portal 提供了一種將子節點渲染到存在于父組件以外的 DOM 節點的優秀的方案。
字符串或數值類型。它們在 DOM 中會被渲染為文本節點。
布爾類型或 null。什么都不渲染。
render() 函數應該為純函數,這意味著在不修改組件 state 的情況下,每次調用時都返回相同的結果,并且它不會直接與瀏覽器交互。不能在里面執行this.setState,會有改變組件狀態的副作用。
3. componentDidMount
會在組件掛載后(插入 DOM 樹中)立即調用, 且只會被調用一次。依賴于 DOM 節點的初始化應該放在這里。
render之后并不會立即調用,而是所有的子組件都render完之后才會調用。
更新(update)階段
此階段生命周期方法:componentWillReceiveProps => shouldComponentUpdate => componentWillUpdate => render => componentDidUpdate。
react組件更新機制
setState引起的state更新或父組件重新render引起的props更新,更新后的state和props相對之前無論是否有變化,都將引起子組件的重新render。
1. 父組件重新render
直接重新渲染。每當父組件重新render導致的重傳props,子組件將直接跟著重新渲染,無論props是否有變化。可通過shouldComponentUpdate方法優化。
更新state再渲染。在componentWillReceiveProps方法中,將props轉換成自己的state,調用 this.setState() 將不會引起第二次渲染。
因為componentWillReceiveProps中判斷props是否變化了,若變化了,this.setState將引起state變化,從而引起render,此時就沒必要再做第二次因重傳props引起的render了,不然重復做一樣的渲染了。
2. 自身setState
組件本身調用setState,無論state有沒有變化。可通過shouldComponentUpdate方法優化。
生命周期分析
1. componentWillReceiveProps(nextProps)
此方法只調用于props引起的組件更新過程中,響應 Props 變化之后進行更新的唯一方式。
參數nextProps是父組件傳給當前組件的新props。根據nextProps和this.props來判斷重傳的props是否改變,以及做相應的處理。
2. shouldComponentUpdate(nextProps, nextState)
根據 shouldComponentUpdate() 的返回值,判斷 React 組件的輸出是否受當前 state 或 props 更改的影響。默認行為是 state 每次發生變化組件都會重新渲染。
當 props 或 state 發生變化時,shouldComponentUpdate() 會在渲染執行之前被調用。返回值默認為 true。
首次渲染或使用 forceUpdate() 時不會調用該方法。
此方法可以將 this.props 與 nextProps 以及 this.state 與nextState 進行比較,返回true時當前組件將繼續執行更新過程,返回false則跳過更新,以此可用來減少組件的不必要渲染,優化組件性能。
請注意,返回 false 并不會阻止子組件在 state 更改時重新渲染。
如果在componentWillReceiveProps()中執行了this.setState,更新state,但在render前(如shouldComponentUpdate,componentWillUpdate),this.state依然指向更新前的state,不然nextState及當前組件的this.state的對比就一直是true了。
應該考慮使用內置的 PureComponent 組件,而不是手動編寫 shouldComponentUpdate()。PureComponent 會對 props 和 state 進行淺層比較,并減少了跳過必要更新的可能性。
3. componentWillUpdate(nextProps, nextState)
此方法在調用render方法前執行,在這邊可執行一些組件更新發生前的工作,一般較少用。
4. render
render同上
5. componentDidUpdate(prevProps, prevState)
此方法在組件更新后立即調用,可以操作組件更新的DOM。
prevProps和prevState這兩個參數指的是組件更新前的props和state。
卸載階段
此階段只有一個生命周期方法:componentWillUnmount
componentWillUnmount
此方法在組件被卸載前調用,可以在這里執行一些清理工作,比如清楚組件中使用的定時器,清楚componentDidMount中手動創建的DOM元素等,以避免引起內存泄漏。
componentWillUnmount() 中不應調用 setState(),因為該組件將永遠不會重新渲染。組件實例卸載后,將永遠不會再掛載它。
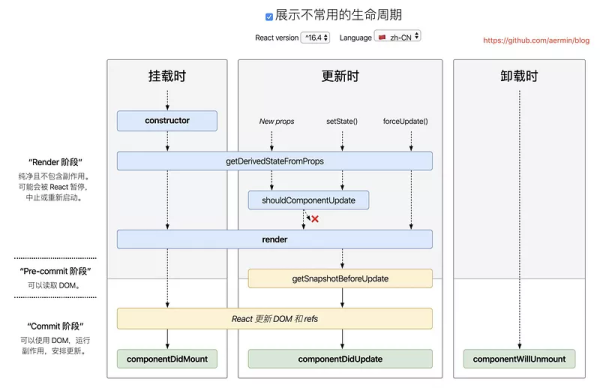
React v16.0 后的生命周期
React v16.0剛推出的時候,增加了一個componentDidCatch生命周期函數,這只是一個增量式修改,完全不影響原有生命周期函數;
React v16.3,引入了兩個新的生命周期:getDerivedStateFromProps,getSnapshotBeforeUpdate, 廢棄掉componentWillMount、componentWillReceiveProps 以及 componentWillUpdate 三個周期(直到React 17前還可以使用,只是會有一個警告)。
為什么要更改生命周期?
生命周期函數的更改是因為 16.3 采用了 Fiber 架構,在新的 Fiber 架構中,組件的更新分為了兩個階段:
鴻蒙官方戰略合作共建——HarmonyOS技術社區
render phase:這個階段決定究竟哪些組件會被更新。
commit phase:這個階段是 React 開始執行更新(比如插入,移動,刪除節點)。
commit phase 的執行很快,但是真實 DOM 的更新很慢,所以 React 在更新的時候會暫停再恢復組件的更新以免長時間的阻塞瀏覽器,這就意味著 render phase 可能會被執行多次(因為有可能被打斷再重新執行)。
constructor
componentWillMount
componentWillReceiveProps
componentWillUpdate
getDerivedStateFromProps
shouldComponentUpdate
render
這些生命周期都屬于 render phase,render phase 可能被多次執行,所以要避免在 render phase 中的生命周期函數中引入副作用。在 16.3 之前的生命周期很容易引入副作用,所以 16.3 之后引入新的生命周期來限制開發者引入副作用。
getDerivedStateFromProps(nextProps, prevState)
React v16.3中,static getDerivedStateFromProps只在組件創建和由父組件引發的更新中調用。如果不是由父組件引發,那么getDerivedStateFromProps也不會被調用,如自身setState引發或者forceUpdate引發。
在React v16.4中改正了這一點,static getDerivedStateFromProps會在調用 render 方法之前調用,并且在初始掛載及后續更新時都會被調用。
特點:
無副作用 。因為是處于 Fiber 的 render 階段,所以有可能會被多次執行。所以 API 被設計為了靜態函數,無法訪問到實例的方法,也沒有 ref 來操作 DOM,這就避免了實例方法帶來副作用的可能性。但是依舊可以從 props 中獲得方法觸發副作用,所以在執行可能觸發副作用的函數前要三思。
只用來更新 state 。其這個生命周期唯一的作用就是從 nextProps 和 prevState 中衍生出一個新的 state。它應返回一個對象來更新 state,或者返回null來不更新任何內容。
getDerivedStateFromProps前面要加上static保留字,聲明為靜態方法,不然會被react忽略掉。
getDerivedStateFromProps里面的this為undefined。
static靜態方法只能Class來調用,而實例是不能調用,所以React Class組件中,靜態方法getDerivedStateFromProps無權訪問Class實例的this,即this為undefined。
getSnapshotBeforeUpdate()
getSnapshotBeforeUpdate() 只會調用一次,在最近一次渲染輸出(提交到 DOM 節點)之前調用,,所以在這個生命周期能夠獲取這一次更新前的 DOM 的信息。此生命周期的任何返回值將作為 componentDidUpdate() 的第三個參數 “snapshot” 參數傳遞, 否則componentDidUpdate的第三個參數將為 undefined。
應返回 snapshot 的值(或 null)。
錯誤處理
當渲染過程,生命周期,或子組件的構造函數中拋出錯誤時,會調用如下方法:
static getDerivedStateFromError():此生命周期會在后代組件拋出錯誤后被調用。它將拋出的錯誤作為參數,并返回一個值以更新 state
componentDidCatch():此生命周期在后代組件拋出錯誤后被調用,它應該用于記錄錯誤之類的情況。
它接收兩個參數:
鴻蒙官方戰略合作共建——HarmonyOS技術社區
error —— 拋出的錯誤。
info —— 帶有 componentStack key 的對象
生命周期比較
16.0 前生命周期

16.0 后生命周期:
參考:
淺析 React v16.3 新生命周期函數
react 16做了哪些更新
鴻蒙官方戰略合作共建——HarmonyOS技術社區
react作為一個ui庫,將前端編程由傳統的命令式編程轉變為聲明式編程,即所謂的數據驅動視圖。如果直接更新真實dom,比如將生成的html直接采用innerHtml替換,會帶來重繪重排之類的性能問題。為了盡量提高性能,React團隊引入了虛擬dom,即采用js對象來描述dom樹,通過對比前后兩次的虛擬對象,來找到最小的dom操作(vdom diff),以此提高性能。
上面提到的reactDom diff,在react 16之前,這個過程我們稱之為stack reconciler,它是一個遞歸的過程,在樹很深的時候,單次diff時間過長會造成JS線程持續被占用,用戶交互響應遲滯,頁面渲染會出現明顯的卡頓,這在現代前端是一個致命的問題。
所以為了解決這種問題,react 團隊對整個架構進行了調整,引入了fiber架構,將以前的stack reconciler替換為fiber reconciler。采用增量式渲染。引入了任務優先級(expiration)和requestIdleCallback的循環調度算法,簡單來說就是將以前的一根筋diff更新,首先拆分成兩個階段:reconciliation與commit;第一個reconciliation階段是可打斷的,被拆分成一個個的小任務(fiber),在每一偵的渲染空閑期做小任務diff。然后是commit階段,這個階段是不拆分且不能打斷的,將diff節點的effectTag一口氣更新到頁面上。
由于reconciliation是可以被打斷的,且存在任務優先級的問題,所以會導致commit前的一些生命周期函數多次被執行, 如componentWillMount、componentWillReceiveProps 和 componetWillUpdate,但react官方已聲明,在React17中將會移除這三個生命周期函數。
由于每次喚起更新是從根節點(RootFiber)開始,為了更好的節點復用與性能優化。在react中始終存workInprogressTree(future vdom) 與 oldTree(current vdom)兩個鏈表,兩個鏈表相互引用。這無形中又解決了另一個問題,當workInprogressTree生成報錯時,這時也不會導致頁面渲染崩潰,而只是更新失敗,頁面仍然還在。
React hooks原理
在React 16前,函數式組件不能擁有狀態管理?因為16以前只有類組件有對應的實例,而16以后Fiber 架構的出現,讓每一個節點都擁有對應的實例,也就擁有了保存狀態的能力。
Hooks的本質就是閉包和兩級鏈表。
閉包是指有權訪問另一個函數作用域中變量或方法的函數,創建閉包的方式就是在一個函數內創建閉包函數,通過閉包函數訪問這個函數的局部變量, 利用閉包可以突破作用鏈域的特性,將函數內部的變量和方法傳遞到外部。
hooks 鏈表
一個組件包含的hooks 以鏈表的形式存儲在fiber節點的memoizedState屬性上,currentHook鏈表就是當前正在遍歷的fiber節點的。nextCurrentHook 就是即將被添加到正在遍歷fiber節點的hooks的新鏈表。
let currentHook: Hook | null = null; let nextCurrentHook: Hook | null = null; type Hooks = { memoizedState: any, // 指向當前渲染節點 Fiber baseState: any, // 初始化 initialState, 最新的state baseUpdate: Update<any> | null, // 當前需要更新的 Update ,每次更新完之后,會賦值上一個 update,方便 react 在渲染錯誤的邊緣,數據回溯 queue: UpdateQueue<any> | null,// 可以讓state變化的,即update或dispach產生的update next: Hook | null, // link 到下一個 hooks }state
其實state不是hooks獨有的,類操作的setState也存在。
memoizedState,cursor 是存在哪里的?如何和每個函數組件一一對應的?
react 會生成一棵組件樹(或Fiber 單鏈表),樹中每個節點對應了一個組件,hooks 的數據就作為組件的一個信息,存儲在這些節點上,伴隨組件一起出生,一起死亡。
為什么只能在函數最外層調用 Hook?
memoizedState 是按 hook定義的順序來放置數據的,如果 hook 順序變化,memoizedState 并不會感知到。
自定義的 Hook 是如何影響使用它的函數組件的?
共享同一個 memoizedState,共享同一個順序。
“Capture Value” 特性是如何產生的?
每一次 ReRender 的時候,都是重新去執行函數組件了,對于之前已經執行過的函數組件,并不會做任何操作。
react setState 異步更新
setState 實現原理
setState 通過一個隊列機制來實現 state 更新,當執行 setState() 時,會將需要更新的 state 淺合并后放入 狀態隊列,而不會立即更新 state,隊列機制可以高效的批量更新 state。如果不通過setState,直接修改this.state 的值,則不會放入狀態隊列,當下一次調用 setState 對狀態隊列進行合并時,之前對 this.state 的修改將會被忽略,造成無法預知的錯誤。
setState()有的同步有的異步?
在React中, 如果是由React引發的事件處理(比如通過onClick引發的事件處理),調用setState不會同步更新this.state,除此之外的setState調用會同步執行this.state 。
所謂“除此之外”,指的是繞過React通過addEventListener直接添加的事件處理函數,還有通過setTimeout/setInterval產生的異步調用。
原因: 在React的setState函數實現中,會根據一個變量isBatchingUpdates判斷是直接更新this.state還是放到隊列中回頭再說,而isBatchingUpdates默認是false,也就表示setState會同步更新this.state,但是,有一個函數batchedUpdates,這個函數會把isBatchingUpdates修改為true,而當React在調用事件處理函數之前就會調用這個batchedUpdates,造成的后果,就是由React控制的事件處理過程setState不會同步更新this.state。
setState的“異步”并不是說內部由異步代碼實現,其實本身執行的過程和代碼都是同步的,只是合成事件和鉤子函數的調用順序在更新之前,導致在合成事件和鉤子函數中沒法立馬拿到更新后的值,形式了所謂的“異步”,可以通過第二個參數 setState(partialState, callback) 中的callback拿到更新后的結果。
調用風險
當調用 setState 時,實際上是會執行 enqueueSetState 方法,并會對 partialState 及 _pendingStateQueue 隊列進行合并操作,最終通過 enqueueUpdate 執行 state 更新。
而 performUpdateIfNecessary 獲取 _pendingElement、 _pendingStateQueue、_pendingForceUpdate,并調用 reaciveComponent 和 updateComponent 來進行組件更新。
但,如果在 shouldComponentUpdate 或 componentWillUpdate 方法里調用 this.setState 方法,就會造成崩潰。
這是因為在 shouldComponentUpdate 或 componentWillUpdate 方法里調用 this.setState 時,this._pendingStateQueue!=null,則 performUpdateIfNecessary 方法就會調用 updateComponent 方法進行組件更新,而 updateComponent 方法又會調用 shouldComponentUpdate和componentWillUpdate 方法,因此造成循環調用,使得瀏覽器內存占滿后崩潰。
React Fiber
掉幀:在頁面元素很多,且需要頻繁刷新的場景下,React 15 會出現掉幀的現象,其根本原因,是大量的同步計算任務阻塞了瀏覽器的 UI 渲染。
默認情況下,JS 運算、頁面布局和頁面繪制都是運行在瀏覽器的主線程當中,他們之間是互斥的關系。
如果 JS 運算持續占用主線程,頁面就沒法得到及時的更新。
當我們調用setState更新頁面的時候,React 會遍歷應用的所有節點,計算出差異,然后再更新 UI,整個過程不能被打斷。
如果頁面元素很多,整個過程占用的時機就可能超過 16 毫秒,就容易出現掉幀的現象。
如何解決主線程長時間被 JS 運算?將JS運算切割為多個步驟,分批完成。在完成一部分任務之后,將控制權交回給瀏覽器,讓瀏覽器有時間進行頁面的渲染。等瀏覽器忙完之后,再繼續之前未完成的任務。
React 15 及以下版本通過遞歸的方式進行渲染,使用的是 JS 引擎自身的函數調用棧,它會一直執行到棧空為止。
而Fiber實現了自己的組件調用棧,它以鏈表的形式遍歷組件樹,可以靈活的暫停、繼續和丟棄執行的任務。實現方式是使用了瀏覽器的requestIdleCallback
window.requestIdleCallback()會在瀏覽器空閑時期依次調用函數,這就可以讓開發者在主事件循環中執行后臺或低優先級的任務,而且不會對像動畫和用戶交互這些延遲觸發但關鍵的事件產生影響。函數一般會按先進先調用的順序執行,除非函數在瀏覽器調用它之前就到了它的超時時間。
React 框架內部的運作可以分為 3 層:
Virtual DOM 層,描述頁面長什么樣。
Reconciler 層,負責調用組件生命周期方法,進行 Diff 運算等。
Renderer 層,根據不同的平臺,渲染出相應的頁面,比較常見的是 ReactDOM 和 ReactNative。
Fiber 表征reconciliation階段所能拆分的最小工作單元,其實指的是一種鏈表樹,它可以用一個純 JS 對象來表示:
const fiber = { stateNode: {}, // 節點實例 child: {}, // 子節點 sibling: {}, // 兄弟節點 return: {}, // 表示處理完成后返回結果所要合并的目標,通常指向父節點 };Reconciler區別
以前的 Reconciler 被命名為Stack Reconciler。Stack Reconciler 運作的過程是不能被打斷的,必須一條道走到黑;
Fiber Reconciler 每執行一段時間,都會將控制權交回給瀏覽器,可以分段執行;
從Stack Reconciler到Fiber Reconciler,源碼層面其實就是干了一件遞歸改循環的事情。
scheduling(調度)
scheduling(調度)是fiber reconciliation的一個過程,主要是進行任務分配,達到分段執行。任務的優先級有六種:
synchronous,與之前的Stack Reconciler操作一樣,同步執行
task,在next tick之前執行
animation,下一幀之前執行
high,在不久的將來立即執行
low,稍微延遲執行也沒關系
offscreen,下一次render時或scroll時才執行
優先級高的任務(如鍵盤輸入)可以打斷優先級低的任務(如Diff)的執行,從而更快的生效。
Fiber Reconciler 在執行過程中,會分為 2 個階段:
階段一,生成 Fiber 樹,得出需要更新的節點信息。這一步是一個漸進的過程,可以被打斷。
階段二,將需要更新的節點一次過批量更新,這個過程不能被打斷。
階段一可被打斷的特性,讓優先級更高的任務先執行,從框架層面大大降低了頁面掉幀的概率。
參考:
React Fiber 原理介紹
React Fiber
HOC 與render props區別
Render Props: 把將要包裹的組件作為props屬性傳入,然后容器組件調用這個屬性,并向其傳參。
實現方式:
1.通過props.children(props),props.children返回的是UI元素。 JSX 標簽中的所有內容都會作為一個 children prop 傳遞給 RenderProps組件。因為 RenderProps 將 {props.children} 渲染在一個
中,被傳遞的這些子組件最終都會出現在輸出結果中。
// 定義 const RenderProps = props => <div> {props.children(props)} </div> // 調用 <RenderProps> {() => <>Hello RenderProps</>} </RenderProps>2.通過props中的任何函數, 自行定義傳入內容
// 定義 const LoginForm = props => { const flag = false; const allProps = { flag, ...props }; if (flag) { return <>{props.login(allProps)}</> } else { return <>{props.notLogin(allProps)}</> } } // 調用 <LoginForm login={() => <h2>LOGIN</h2>} noLogin={() => <h2>NOT LOGIN</h2>} />優點:
1、支持ES6
2、不用擔心props命名問題,在render函數中只取需要的state
3、不會產生無用的組件加深層級
4、render props模式的構建都是動態的,所有的改變都在render中觸發,可以更好的利用組件內的生命周期。
HOC: 接受一個組件作為參數,返回一個新的組件的函數。
class Home extends React.Component { // UI } export default Connect()(Home);高階組件由于每次都會返回一個新的組件,對于react來說,這是不利于diff和狀態復用的,所以高階組件的包裝不能在render 方法中進行,而只能像上面那樣在組件聲明時包裹,這樣也就不利于動態傳參。
優點:
1、支持ES6
2、復用性強,HOC為純函數且返回值為組件,可以多層嵌套
3、支持傳入多個參數,增強了適用范圍
缺點:
1、當多個HOC一起使用時,無法直接判斷子組件的props是哪個HOC負責傳遞的
2、多個組件嵌套,容易產生同樣名稱的props
3、HOC可能會產生許多無用的組件,加深了組件的層級
總的來說,render props其實和高階組件類似,就是在puru component上增加state,響應react的生命周期。
React 通信
react的數據流是單向的,最常見的就是通過props由父組件向子組件傳值。
父向子通信:傳入props
子向父通信:父組件向子組件傳一個函數,然后通過這個函數的回調,拿到子組件傳過來的值
父向孫通信:利用context傳值。React.createContext()
兄弟間通信:
1、找一個相同的父組件,既可以用props傳遞數據,也可以用context的方式來傳遞數據。
2、用一些全局機制去實現通信,比如redux等
3、發布訂閱模式
react合成事件
React 合成事件(SyntheticEvent)是 React 模擬原生 DOM 事件所有能力的一個事件對象,即瀏覽器原生事件的跨瀏覽器包裝器。
為什么要使用合成事件?
1.進行瀏覽器兼容,實現更好的跨平臺
React 采用的是頂層事件代理機制,能夠保證冒泡一致性,可以跨瀏覽器執行。React 提供的合成事件用來抹平不同瀏覽器事件對象之間的差異,將不同平臺事件模擬合成事件。
2.避免垃圾回收
事件對象可能會被頻繁創建和回收,因此 React 引入事件池,在事件池中獲取或釋放事件對象。即 React 事件對象不會被釋放掉,而是存放進一個數組中,當事件觸發,就從這個數組中彈出,避免頻繁地去創建和銷毀(垃圾回收)。
3.方便事件統一管理和事務機制
實現原理
在 React 中,“合成事件”會以事件委托方式綁定在 document 對象上,并在組件卸載(unmount)階段自動銷毀綁定的事件。
合成事件和原生事件
當真實 DOM 元素觸發事件,會冒泡到 document 對象后,再處理 React 事件;所以會先執行原生事件,然后處理 React 事件;最后真正執行 document 上掛載的事件。
合成事件和原生事件最好不要混用。原生事件中如果執行了stopPropagation方法,則會導致其他React事件失效。因為所有元素的事件將無法冒泡到document上,所有的 React 事件都將無法被注冊。
合成事件的事件池
合成事件對象池,是 React 事件系統提供的一種性能優化方式。合成事件對象在事件池統一管理,不同類型的合成事件具有不同的事件池。
react 虛擬dom
什么是虛擬dom?
在 React 中,render 執行的結果得到的并不是真正的 DOM 節點,而是輕量級的 JavaScript 對象,我們稱之為 virtual DOM。它通過JS的Object對象模擬DOM中的節點,然后再通過特定的render方法將其渲染成真實的DOM節點。
虛擬 DOM 是 React 的一大亮點,具有batching(批處理) 和高效的 Diff 算法。batching 把所有的 DOM 操作搜集起來,一次性提交給真實的 DOM。diff 算法時間復雜度也從標準的的 Diff 算法的 O(n^3) 降到了 O(n)。
batching(批處理)
主要思想是,無論setState您在React事件處理程序或同步生命周期方法中進行多少次調用,它都將被批處理成一個更新, 最終只有一次重新渲染。
虛擬 DOM 與 原生 DOM
如果沒有 Virtual DOM,就需要直接操作原生 DOM。在一個大型列表所有數據都變了的情況下,直接重置 innerHTML還算合理,但是,只有一行數據發生變化時,它也需要重置整個 innerHTML,這就造成了大量浪費。
innerHTML 和 Virtual DOM 的重繪性能消耗:
innerHTML: render html string + 重新創建所有 DOM 元素
Virtual DOM: render Virtual DOM + diff + 必要的 DOM 更新
Virtual DOM render + diff 顯然比渲染 html 字符串要慢,但是它依然是純 js 層面的計算,比起后面的 DOM 操作來說,依然便宜了太多。innerHTML 的總計算量不管是 js 計算還是 DOM 操作都是和整個界面的大小相關,但 Virtual DOM 的計算量只有 js 計算和界面大小相關,DOM 操作是和數據的變動量相關。

虛擬 DOM 與 MVVM
相比起 React,其他 MVVM 系框架比如 Angular, Knockout , Vue ,Avalon 采用的都是數據綁定。通過 Directive/Binding 對象,觀察數據變化并保留對實際 DOM 元素的引用,當有數據變化時進行對應的操作。MVVM 的變化檢查是數據層面的,而 React 的檢查是 DOM 結構層面的。
MVVM 的性能也根據變動檢測的實現原理有所不同:Angular 依賴于臟檢查;Knockout/Vue/Avalon 采用了依賴收集。
臟檢查:scope digest(watcher count) ) + 必要 DOM 更新
依賴收集:重新收集依賴(data change) ) + 必要 DOM 更新
Angular 最不效率的地方在于任何小變動都有的和 watcher 數量相關的性能代價,當所有數據都變了的時候,Angular更有效。依賴收集在初始化和數據變化的時候都需要重新收集依賴,這個代價在小量更新的時候幾乎可以忽略,但在數據量龐大的時候也會產生一定的消耗。
性能比較
在比較性能的時候,要分清楚初始渲染、小量數據更新、大量數據更新這些不同的場合。Virtual DOM、臟檢查 MVVM、數據收集 MVVM 在不同場合各有不同的表現和不同的優化需求。
Virtual DOM 為了提升小量數據更新時的性能,也需要針對性的優化,比如 shouldComponentUpdate 或是 immutable data。
初始渲染:Virtual DOM > 臟檢查 >= 依賴收集
小量數據更新:依賴收集 >> Virtual DOM + 優化 > 臟檢查(無法優化)> Virtual DOM 無優化
大量數據更新:臟檢查 + 優化 >= 依賴收集 + 優化 > Virtual DOM(無法/無需優化)>> MVVM 無優化
diff 算法
傳統 diff 算法通過循環遞歸對節點進行依次對比,算法復雜度達到 O(n^3),其中 n 是樹中節點的總數。O(n^3) 意味著如果要展示1000個節點,就要依次執行上十億次的比較, 這是無法滿足現代前端性能要求的。
diff 算法主要包括幾個步驟:
用 JS 對象的方式來表示 DOM 樹的結構,然后根據這個對象構建出真實的 DOM 樹,插到文檔中。
當狀態變更的時候,重新構造一棵新的對象樹。然后用新的樹和舊的樹進行比較,記錄兩棵樹的差異, 最后把所記錄的差異應用到所構建的真正的DOM樹上,視圖更新。
diff 策略
React 通過制定大膽的diff策略,將diff算法復雜度從 O(n^3) 轉換成 O(n) 。
React 通過分層求異的策略,對 tree diff 進行算法優化;
React 通過相同類生成相似樹形結構,不同類生成不同樹形結構的策略,對 component diff 進行算法優化;
React 通過設置唯一 key的策略,對 element diff 進行算法優化;
tree diff(層級比較)
React 對樹進行分層比較,兩棵樹只會對同一層次的節點進行比較。
當發現節點已經不存在,則該節點及其子節點會被完全刪除掉,不會進行進一步的比較。
這樣只需要對樹進行一次遍歷,便能完成整個 DOM 樹的比較。
當出現節點跨層級移動時,并不會出現移動操作,而是以該節點為根節點的樹被重新創建,這是一種影響 React 性能的操作,因此 React 官方建議不要進行 DOM 節點跨層級的操作。
先進行樹結構的層級比較,對同一個父節點下的所有子節點進行比較;
接著看節點是什么類型的,是組件就做 Component Diff;
如果節點是標簽或者元素,就做 Element Diff;
注意:在開發組件時,保持穩定的 DOM 結構會有助于性能的提升。例如,可以通過 CSS 隱藏或顯示節點,而不是真的移除或添加 DOM 節點。
component diff(組件比較)
如果是同一類型的組件,按照原策略繼續比較 virtual DOM tree。
如果不是,則將該組件判斷為 dirty component,替換整個組件下的所有子節點。舉個例子,當一個元素從 變成
對于同一類型的組件,有可能其 Virtual DOM 沒有任何變化,如果能夠確切的知道這點那可以節省大量的 diff 運算時間。因此 React 允許用戶通過 shouldComponentUpdate() 來判斷該組件是否需要進行 diff。
對于兩個不同類型但結構相似的組件,不會比較二者的結構,而且替換整個組件的所有內容。不同類型的 component 是很少存在相似 DOM tree 的機會,因此這種極端因素很難在實現開發過程中造成重大影響的。
element diff (元素比較)
當節點處于同一層級時,React diff 提供了三種節點操作,分別為:INSERT_MARKUP(插入)、MOVE_EXISTING(移動)和 REMOVE_NODE(刪除)。
INSERT_MARKUP,新的 component 類型不在老集合里, 即是全新的節點,需要對新節點執行插入操作。
MOVE_EXISTING,在老集合有新 component 類型,且 element 是可更新的類型,這種情況下需要做移動操作,可以復用以前的 DOM 節點。
REMOVE_NODE,老 component 類型,在新集合里也有,但對應的 element 不同則不能直接復用和更新,需要執行刪除操作,或者老 component 不在新集合里的,也需要執行刪除操作。
<ul> <li>Duke</li> <li>Villanova</li> </ul> <ul> <li>Connecticut</li> <li>Duke</li> <li>Villanova</li> </ul>
React 并不會意識到應該保留<li>Duke</li>和<li>Villanova</li>,而是會重建每一個子元素,不會進行移動 DOM 操作。
key 優化
為了解決上述問題,React 引入了 key 屬性, 對同一層級的同組子節點,添加唯一 key 進行區分。
當子元素擁有 key 時,React 使用 key 來匹配原有樹上的子元素以及最新樹上的子元素。如果有相同的節點,無需進行節點刪除和創建,只需要將老集合中節點的位置進行移動,更新為新集合中節點的位置。
在開發過程中,盡量減少類似將最后一個節點移動到列表首部的操作,當節點數量過大或更新操作過于頻繁時,在一定程度上會影響 React 的渲染性能。
key 不需要全局唯一,但在列表中需要保持唯一。
Key 應該具有穩定,可預測,以及列表內唯一的特質。不穩定的 key(比如通過 Math.random() 生成的)會導致許多組件實例和 DOM 節點被不必要地重新創建,這可能導致性能下降和子組件中的狀態丟失。
react與vue區別
1. 監聽數據變化的實現原理不同
Vue通過 getter/setter以及一些函數的劫持,能精確知道數據變化。
React默認是通過比較引用的方式(diff)進行的,如果不優化可能導致大量不必要的VDOM的重新渲染。
2. 數據流不同
Vue1.0中可以實現兩種雙向綁定:父子組件之間props可以雙向綁定;組件與DOM之間可以通過v-model雙向綁定。
Vue2.x中父子組件之間不能雙向綁定了(但是提供了一個語法糖自動幫你通過事件的方式修改)。
React一直不支持雙向綁定,提倡的是單向數據流,稱之為onChange/setState()模式。
3. HoC和mixins
Vue組合不同功能的方式是通過mixin,Vue中組件是一個被包裝的函數,并不簡單的就是我們定義組件的時候傳入的對象或者函數。
React組合不同功能的方式是通過HoC(高階組件)。
4. 模板渲染方式的不同
模板的語法不同,React是通過JSX渲染模板, Vue是通過一種拓展的HTML語法進行渲染。
模板的原理不同,React通過原生JS實現模板中的常見語法,比如插值,條件,循環等。而Vue是在和組件JS代碼分離的單獨的模板中,通過指令來實現的,比如 v-if 。
舉個例子,說明React的好處:react中render函數是支持閉包特性的,所以我們import的組件在render中可以直接調用。但是在Vue中,由于模板中使用的數據都必須掛在 this 上進行一次中轉,所以我們import 一個組件完了之后,還需要在 components 中再聲明下。
5. 渲染過程不同
Vue可以更快地計算出Virtual DOM的差異,這是由于它會跟蹤每一個組件的依賴關系,不需要重新渲染整個組件樹。
React當狀態被改變時,全部子組件都會重新渲染。通過shouldComponentUpdate這個生命周期方法可以進行控制,但Vue將此視為默認的優化。
6. 框架本質不同
Vue本質是MVVM框架,由MVC發展而來;
React是前端組件化框架,由后端組件化發展而來。
性能優化
1. 靜態資源使用 CDN
CDN是一組分布在多個不同地理位置的 Web 服務器。當服務器離用戶越遠時,延遲越高。
2. 無阻塞
頭部內聯的樣式和腳本會阻塞頁面的渲染,樣式放在頭部并使用link方式引入,腳本放在尾部并使用異步方式加載
3. 壓縮文件
壓縮文件可以減少文件下載時間。
1.在 webpack 可以使用如下插件進行壓縮:
JavaScript:UglifyPlugin
CSS :MiniCssExtractPlugin
HTML:HtmlWebpackPlugin
2.使用 gzip 壓縮。通過向 HTTP 請求頭中的 Accept-Encoding 頭添加 gzip 標識來開啟這一功能。
4. 圖片優化
鴻蒙官方戰略合作共建——HarmonyOS技術社區
圖片懶加載
響應式圖片:瀏覽器根據屏幕大小自動加載合適的圖片。
降低圖片質量:方法有兩種,一是通過 webpack 插件 image-webpack-loader,二是通過在線網站進行壓縮。
5. 減少重繪重排
降低 CSS 選擇器的復雜性
使用 transform 和 opacity 屬性更改來實現動畫
用 JavaScript 修改樣式時,最好不要直接寫樣式,而是替換 class 來改變樣式。
如果要對 DOM 元素執行一系列操作,可以將 DOM 元素脫離文檔流,修改完成后,再將它帶回文檔。推薦使用隱藏元素(display:none)或文檔碎片(DocumentFragement),都能很好的實現這個方案。
6. 使用 requestAnimationFrame 來實現視覺變化
window.requestAnimationFrame() 告訴瀏覽器——你希望執行一個動畫,并且要求瀏覽器在下次重繪之前調用指定的回調函數更新動畫。該方法需要傳入一個回調函數作為參數,該回調函數會在瀏覽器下一次重繪之前執行
7. webpack 打包, 添加文件緩存
index.html 設置成 no-cache,這樣每次請求的時候都會比對一下 index.html 文件有沒變化,如果沒變化就使用緩存,有變化就使用新的 index.html 文件。
其他所有文件一律使用長緩存,例如設置成緩存一年 maxAge: 1000 * 60 * 60 * 24 * 365。
前端代碼使用 webpack 打包,根據文件內容生成對應的文件名,每次重新打包時只有內容發生了變化,文件名才會發生變化。
max-age: 設置緩存存儲的最大周期,超過這個時間緩存被認為過期(單位秒)。在這個時間前,瀏覽器讀取文件不會發出新請求,而是直接使用緩存。
指定 no-cache 表示客戶端可以緩存資源,每次使用緩存資源前都必須重新驗證其有效性
輸入url后發生了什么
鴻蒙官方戰略合作共建——HarmonyOS技術社區
DNS域名解析;
建立TCP連接(三次握手);
發送HTTP請求;
服務器處理請求;
返回響應結果;
關閉TCP連接(四次握手);
瀏覽器解析HTML;
瀏覽器布局渲染;
1. DNS域名解析:拿到服務器ip
客戶端收到你輸入的域名地址后,它首先去找本地的hosts文件,檢查在該文件中是否有相應的域名、IP對應關系,如果有,則向其IP地址發送請求,如果沒有,再去找DNS服務器。
2. 建立TCP鏈接:客戶端鏈接服務器
TCP提供了一種可靠、面向連接、字節流、傳輸層的服務。對于客戶端與服務器的TCP鏈接,必然要說的就是『三次握手』。“3次握手”的作用就是雙方都能明確自己和對方的收、發能力是正常的。
客戶端發送一個帶有SYN標志的數據包給服務端,服務端收到后,回傳一個帶有SYN/ACK標志的數據包以示傳達確認信息,最后客戶端再回傳一個帶ACK標志的數據包,代表握手結束,連接成功。
SYN —— 用于初如化一個連接的序列號。
ACK —— 確認,使得確認號有效。
RST —— 重置連接。
FIN —— 該報文段的發送方已經結束向對方發送數據。
客戶端:“你好,在家不。” -- SYN
服務端:“在的,你來吧。” -- SYN + ACK
客戶端:“好嘞。” -- ACK
3. 發送HTTP請求
4. 服務器處理請求
5. 返回響應結果
6. 關閉TCP連接(需要4次握手)
為了避免服務器與客戶端雙方的資源占用和損耗,當雙方沒有請求或響應傳遞時,任意一方都可以發起關閉請求。
關閉連接時,服務器收到對方的FIN報文時,僅僅表示客戶端不再發送數據了但是還能接收數據,而服務器也未必全部數據都發送給客戶端,所以服務器可以立即關閉,也可以發送一些數據給對方后,再發送FIN報文給對方來表示同意現在關閉連接,因此,己方ACK和FIN一般都會分開發送,從而導致多了一次。
客戶端:“兄弟,我這邊沒數據要傳了,咱關閉連接吧。” -- FIN + seq
服務端:“收到,我看看我這邊有木有數據了。” -- ACK + seq + ack
服務端:“兄弟,我這邊也沒數據要傳你了,咱可以關閉連接了。” - FIN + ACK + seq + ack
客戶端:“好嘞。” -- ACK + seq + ack
7. 瀏覽器解析HTML
瀏覽器需要加載解析的不僅僅是HTML,還包括CSS、JS,以及還要加載圖片、視頻等其他媒體資源。
瀏覽器通過解析HTML,生成DOM樹,解析CSS,生成CSSOM樹,然后通過DOM樹和CSSPOM樹生成渲染樹。渲染樹與DOM樹不同,渲染樹中并沒有head、display為none等不必顯示的節點。
瀏覽器的解析過程并非是串連進行的,比如在解析CSS的同時,可以繼續加載解析HTML,但在解析執行JS腳本時,會停止解析后續HTML,會出現阻塞問題。
8. 瀏覽器渲染頁面
根據渲染樹布局,計算CSS樣式,即每個節點在頁面中的大小和位置等幾何信息。HTML默認是流式布局的,CSS和js會打破這種布局,改變DOM的外觀樣式以及大小和位置。最后瀏覽器繪制各個節點,將頁面展示給用戶。
replaint:屏幕的一部分重畫,不影響整體布局,比如某個CSS的背景色變了,但元素的幾何尺寸和位置不變。
reflow:意味著元素的幾何尺寸變了,需要重新計算渲染樹。
參考:
細說瀏覽器輸入URL后發生了什么
瀏覽器輸入 URL 后發生了什么?
前端路由
什么是路由
路由是用來跟后端服務器進行交互的一種方式,通過不同的路徑請求不同的資源。
路由這概念最開始是在后端出現, 在前后端不分離的時期, 由后端來控制路由, 服務器接收客戶端的請求,解析對應的url路徑, 并返回對應的頁面/資源。
前端路由
Ajax,全稱 Asynchronous JavaScript And XML,是瀏覽器用來實現異步加載的一種技術方案。
在Ajax沒有出現時期,大多數的網頁都是通過直接返回 HTML,用戶的每次更新操作都需要重新刷新頁面,及其影響交互體驗。為了解決這個問題,提出了Ajax(異步加載方案), 有了 Ajax 后,用戶交互就不用每次都刷新頁面。后來出現SPA單頁應用。
SPA 中用戶的交互是通過 JS 改變 HTML 內容來實現的,頁面本身的 url 并沒有變化,這導致了兩個問題:
SPA 無法記住用戶的操作記錄,無論是刷新、前進還是后退,都無法展示用戶真實的期望內容。
SPA 中雖然由于業務的不同會有多種頁面展示形式,但只有一個 url,對 SEO 不友好,不方便搜索引擎進行收錄。
前端路由就是為了解決上述問題而出現的。
前端路由的實現方式
前端路由的實現實際上是檢測 url 的變化,截獲 url 地址,解析來匹配路由規則。有下面兩種實現方式:
1. Hash模式
hash 就是指 url 后的 # 號以及后面的字符。 #后面 hash 值的變化,并不會導致瀏覽器向服務器發出請求,瀏覽器不發請求,也就不會刷新頁面。
hash 的改變會觸發 hashchange 事件,可以用onhashchange事件來監聽hash值的改變。
// 監聽hash變化,點擊瀏覽器的前進后退會觸發 window.onhashchange = function() { ... } window.addEventListener('hashchange', function(event) { ...}, false);2.History 模式
在 HTML5 之前,瀏覽器就已經有了 history 對象。但在早期的 history 中只能用于多頁面的跳轉:
history.go(-1); // 后退一頁 history.go(2); // 前進兩頁 history.forward(); // 前進一頁 history.back(); // 后退一頁
在 HTML5 的規范中,history 新增了幾個 API:
history.pushState(); // 向當前瀏覽器會話的歷史堆棧中添加一個狀態 history.replaceState();// 修改了當前的歷史記錄項(不是新建一個) history.state // 返回一個表示歷史堆棧頂部的狀態的值
由于 history.pushState() 和 history.replaceState() 可以改變 url 同時,不會刷新頁面,所以在 HTML5 中的 histroy 具備了實現前端路由的能力。
window對象提供了onpopstate事件來監聽歷史棧的改變,一旦歷史棧信息發生改變, 便會觸發該事件。
調用history.pushState()或history.replaceState()不會觸發popstate事件。只有在做出瀏覽器動作時,才會觸發該事件,例如執行history.back()或history.forward()后觸發 window.onpopstate事件。
// 歷史棧改變 window.onpopstate = function() { ... }注意:pushState() 不會造成 hashchange 事件調用, 即使新的URL和之前的URL只是錨的數據不同。
兩種模式對比

前端路由實踐
vue-router/react-router 都是基于前端路由的原理實現的~
react-router常用的 history 有三種形式:
browserHistory: 使用瀏覽器中的History API 用于處理 URL。history 在 DOM 上的實現,用于支持 HTML5 history API 的瀏覽器。
hashHistory: 使用 URL 中的 hash(#)部分去創建路由。history 在 DOM 上的實現,用于舊版瀏覽器。
createMemoryHistory: 不會在地址欄被操作或讀取,history 在內存上的實現,用于測試或非 DOM 環境(例如 React Native)。
Babel Plugin與preset區別
Babel是代碼轉換器,比如將ES6轉成ES5,或者將JSX轉成JS等。借助Babel,開發者可以提前用上新的JS特性。
原始代碼 --> [Babel Plugin] --> 轉換后的代碼
Plugin
實現Babel代碼轉換功能的核心,就是Babel插件(plugin)。Babel插件一般盡可能拆成小的力度,開發者可以按需引進, 既提高了性能,也提高了擴展性。比如對ES6轉ES5的功能,Babel官方拆成了20+個插件。開發者想要體驗ES6的箭頭函數特性,那只需要引入transform-es2015-arrow-functions插件就可以,而不是加載ES6全家桶。
Preset
可以簡單的把Babel Preset視為Babel Plugin的集合。想要將所有ES6的代碼轉成ES5,逐個插件引入的效率比較低下, 就可以采用Babel Preset。比如babel-preset-es2015就包含了所有跟ES6轉換有關的插件。
Plugin與Preset執行順序
可以同時使用多個Plugin和Preset,此時,它們的執行順序非常重要。
鴻蒙官方戰略合作共建——HarmonyOS技術社區
先執行完所有Plugin,再執行Preset。
多個Plugin,按照聲明次序順序執行。
多個Preset,按照聲明次序逆序執行。
比如.babelrc配置如下,那么執行的順序為:
鴻蒙官方戰略合作共建——HarmonyOS技術社區
Plugin:transform-react-jsx、transform-async-to-generator
Preset:es2016、es2015
{ "presets": [ "es2015", "es2016" ], "plugins": [ "transform-react-jsx", "transform-async-to-generator" ] }怎樣開發和部署前端代碼
為了進一步提升網站性能,會把靜態資源和動態網頁分集群部署,靜態資源會被部署到CDN節點上,網頁中引用的資源也會變成對應的部署路徑。當需要更新靜態資源的時候,同時也會更新html中的引用。
如果同時改了頁面結構和樣式,也更新了靜態資源對應的url地址,現在要發布代碼上線,是先上線頁面,還是先上線靜態資源?
鴻蒙官方戰略合作共建——HarmonyOS技術社區
先部署頁面,再部署資源:在二者部署的時間間隔內,如果有用戶訪問頁面,就會在新的頁面結構中加載舊的資源,并且把這個舊版本的資源當做新版本緩存起來,其結果就是:用戶訪問到了一個樣式錯亂的頁面,除非手動刷新,否則在資源緩存過期之前,頁面會一直執行錯誤。
先部署資源,再部署頁面:在部署時間間隔之內,有舊版本資源本地緩存的用戶訪問網站,由于請求的頁面是舊版本的,資源引用沒有改變,瀏覽器將直接使用本地緩存,這種情況下頁面展現正常;但沒有本地緩存或者緩存過期的用戶訪問網站,就會出現舊版本頁面加載新版本資源的情況,導致頁面執行錯誤,但當頁面完成部署,這部分用戶再次訪問頁面又會恢復正常了。
這個奇葩問題,起源于資源的 覆蓋式發布,用 待發布資源 覆蓋 已發布資源,就有這種問題。
解決它也好辦,就是實現 非覆蓋式發布。用文件的摘要信息來對資源文件進行重命名,把摘要信息放到資源文件發布路徑中,這樣,內容有修改的資源就變成了一個新的文件發布到線上,不會覆蓋已有的資源文件。
上線過程中,先全量部署靜態資源,再灰度部署頁面,整個問題就比較完美的解決了。
大公司的靜態資源優化方案,基本上要實現這么幾個東西:
鴻蒙官方戰略合作共建——HarmonyOS技術社區
配置超長時間的本地緩存 —— 節省帶寬,提高性能
采用內容摘要作為緩存更新依據 —— 精確的緩存控制
靜態資源CDN部署 —— 優化網絡請求
更改資源發布路徑實現非覆蓋式發布 —— 平滑升級
大數相加
function add(a, b){ const maxLength = Math.max(a.length, b.length); a = a.padStart(maxLength, 0); b = b.padStart(maxLength, 0); let t = 0; let f = 0; let sum = ""; for (let i = maxLength - 1; i >= 0; i--) { t = parseInt(a[i]) + parseInt(b[i]) + f; f = Math.floor(t / 10); sum = `${t % 10}${sum}`; } if (f === 1){ sum = "1" + sum; } return sum; }斐波那契數列求和
function fib(n) { if (n <= 0) { return 0; } let n1 = 1; let n2 = 1; let sum = 1; for(let i = 3; i <= n; i++) { [n1, n2] = [n2, sum]; sum = n1 + n2; } return sum; };到此,關于“一些前端基礎知識整理匯總”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





