溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Python中怎么實現內存管理,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
對象的內存使用
賦值語句是語言最常見的功能了。但即使是最簡單的賦值語句,也可以很有內涵。Python的賦值語句就很值得研究。
a = 1
整數1為一個對象。而a是一個引用。利用賦值語句,引用a指向對象1。Python是動態類型的語言(參考動態類型),對象與引用分離。Python像使用“筷子”那樣,通過引用來接觸和翻動真正的食物——對象。

引用和對象
為了探索對象在內存的存儲,我們可以求助于Python的內置函數id()。它用于返回對象的身份(identity)。其實,這里所謂的身份,就是該對象的內存地址。
a = 1 print(id(a)) print(hex(id(a)))
在我的計算機上,它們返回的是:
11246696 '0xab9c68'
分別為內存地址的十進制和十六進制表示。
在Python中,整數和短小的字符,Python都會緩存這些對象,以便重復使用。當我們創建多個等于1的引用時,實際上是讓所有這些引用指向同一個對象。
a = 1 b = 1 print(id(a)) print(id(b))
上面程序返回
11246696 11246696
可見a和b實際上是指向同一個對象的兩個引用。
為了檢驗兩個引用指向同一個對象,我們可以用is關鍵字。is用于判斷兩個引用所指的對象是否相同。
# True a = 1 b = 1 print(a is b) # True a = "good" b = "good" print(a is b) # False a = "very good morning" b = "very good morning" print(a is b) # False a = [] b = [] print(a is b)
上面的注釋為相應的運行結果。可以看到,由于Python緩存了整數和短字符串,因此每個對象只存有一份。比如,所有整數1的引用都指向同一對象。即使使用賦值語句,也只是創造了新的引用,而不是對象本身。長的字符串和其它對象可以有多個相同的對象,可以使用賦值語句創建出新的對象。
在Python中,每個對象都有存有指向該對象的引用總數,即引用計數(reference count)。
我們可以使用sys包中的getrefcount(),來查看某個對象的引用計數。需要注意的是,當使用某個引用作為參數,傳遞給getrefcount()時,參數實際上創建了一個臨時的引用。因此,getrefcount()所得到的結果,會比期望的多1。
from sys import getrefcount a = [1, 2, 3] print(getrefcount(a)) b = a print(getrefcount(b))
由于上述原因,兩個getrefcount將返回2和3,而不是期望的1和2。
對象引用對象
Python的一個容器對象(container),比如表、詞典等,可以包含多個對象。實際上,容器對象中包含的并不是元素對象本身,是指向各個元素對象的引用。
我們也可以自定義一個對象,并引用其它對象:
class from_obj(object): def __init__(self, to_obj): self.to_obj = to_obj b = [1,2,3] a = from_obj(b) print(id(a.to_obj)) print(id(b))
可以看到,a引用了對象b。
對象引用對象,是Python最基本的構成方式。即使是a = 1這一賦值方式,實際上是讓詞典的一個鍵值"a"的元素引用整數對象1。該詞典對象用于記錄所有的全局引用。該詞典引用了整數對象1。我們可以通過內置函數globals()來查看該詞典。
當一個對象A被另一個對象B引用時,A的引用計數將增加1。
from sys import getrefcount a = [1, 2, 3] print(getrefcount(a)) b = [a, a] print(getrefcount(a))
由于對象b引用了兩次a,a的引用計數增加了2。
容器對象的引用可能構成很復雜的拓撲結構。我們可以用objgraph包來繪制其引用關系,比如
x = [1, 2, 3] y = [x, dict(key1=x)] z = [y, (x, y)] import objgraph objgraph.show_refs([z], filename='ref_topo.png')
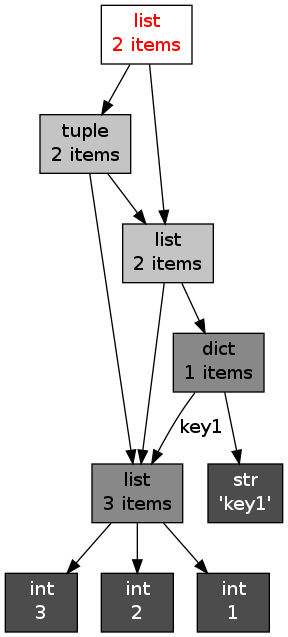
objgraph是Python的一個第三方包。安裝之前需要安裝xdot。
sudo apt-get install xdot sudo pip install objgraph
objgraph官網:http://mg.pov.lt/objgraph/
兩個對象可能相互引用,從而構成所謂的引用環(reference cycle)。
a = [] b = [a] a.append(b)
即使是一個對象,只需要自己引用自己,也能構成引用環。
a = [] a.append(a) print(getrefcount(a))
引用環會給垃圾回收機制帶來很大的麻煩,我將在后面詳細敘述這一點。
引用減少
某個對象的引用計數可能減少。比如,可以使用del關鍵字刪除某個引用:
from sys import getrefcount a = [1, 2, 3] b = a print(getrefcount(b)) del a print(getrefcount(b))
del也可以用于刪除容器元素中的元素,比如:
a = [1,2,3] del a[0] print(a)
如果某個引用指向對象A,當這個引用被重新定向到某個其他對象B時,對象A的引用計數減少:
from sys import getrefcount a = [1, 2, 3] b = a print(getrefcount(b)) a = 1 print(getrefcount(b))
垃圾回收
吃太多,總會變胖,Python也是這樣。當Python中的對象越來越多,它們將占據越來越大的內存。不過你不用太擔心Python的體形,它會乖巧的在適當的時候“減肥”,啟動垃圾回收(garbage collection),將沒用的對象清除。在許多語言中都有垃圾回收機制,比如Java和Ruby。盡管最終目的都是塑造苗條的提醒,但不同語言的減肥方案有很大的差異 。

從基本原理上,當Python的某個對象的引用計數降為0時,說明沒有任何引用指向該對象,該對象就成為要被回收的垃圾了。比如某個新建對象,它被分配給某個引用,對象的引用計數變為1。如果引用被刪除,對象的引用計數為0,那么該對象就可以被垃圾回收。比如下面的表:
a = [1, 2, 3] del a
del a后,已經沒有任何引用指向之前建立的[1, 2, 3]這個表。用戶不可能通過任何方式接觸或者動用這個對象。這個對象如果繼續待在內存里,就成了不健康的脂肪。當垃圾回收啟動時,Python掃描到這個引用計數為0的對象,就將它所占據的內存清空。
然而,減肥是個昂貴而費力的事情。垃圾回收時,Python不能進行其它的任務。頻繁的垃圾回收將大大降低Python的工作效率。如果內存中的對象不多,就沒有必要總啟動垃圾回收。所以,Python只會在特定條件下,自動啟動垃圾回收。當Python運行時,會記錄其中分配對象(object allocation)和取消分配對象(object deallocation)的次數。當兩者的差值高于某個閾值時,垃圾回收才會啟動。
我們可以通過gc模塊的get_threshold()方法,查看該閾值:
import gc print(gc.get_threshold())
返回(700, 10, 10),后面的兩個10是與分代回收相關的閾值,后面可以看到。700即是垃圾回收啟動的閾值。可以通過gc中的set_threshold()方法重新設置。
我們也可以手動啟動垃圾回收,即使用gc.collect()。
分代回收
Python同時采用了分代(generation)回收的策略。這一策略的基本假設是,存活時間越久的對象,越不可能在后面的程序中變成垃圾。我們的程序往往會產生大量的對象,許多對象很快產生和消失,但也有一些對象長期被使用。出于信任和效率,對于這樣一些“長壽”對象,我們相信它們的用處,所以減少在垃圾回收中掃描它們的頻率。

小家伙要多檢查
Python將所有的對象分為0,1,2三代。所有的新建對象都是0代對象。當某一代對象經歷過垃圾回收,依然存活,那么它就被歸入下一代對象。垃圾回收啟動時,一定會掃描所有的0代對象。如果0代經過一定次數垃圾回收,那么就啟動對0代和1代的掃描清理。當1代也經歷了一定次數的垃圾回收后,那么會啟動對0,1,2,即對所有對象進行掃描。
這兩個次數即上面get_threshold()返回的(700, 10, 10)返回的兩個10。也就是說,每10次0代垃圾回收,會配合1次1代的垃圾回收;而每10次1代的垃圾回收,才會有1次的2代垃圾回收。
同樣可以用set_threshold()來調整,比如對2代對象進行更頻繁的掃描。
import gc gc.set_threshold(700, 10, 5)
孤立的引用環
引用環的存在會給上面的垃圾回收機制帶來很大的困難。這些引用環可能構成無法使用,但引用計數不為0的一些對象。
a = [] b = [a] a.append(b) del a del b
上面我們先創建了兩個表對象,并引用對方,構成一個引用環。刪除了a,b引用之后,這兩個對象不可能再從程序中調用,就沒有什么用處了。但是由于引用環的存在,這兩個對象的引用計數都沒有降到0,不會被垃圾回收。
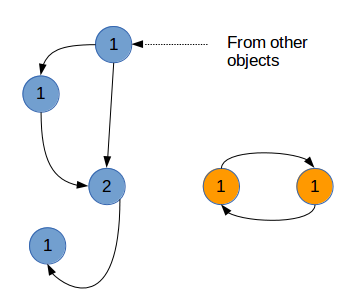
孤立的引用環
為了回收這樣的引用環,Python復制每個對象的引用計數,可以記為gc_ref。假設,每個對象i,該計數為gc_ref_i。Python會遍歷所有的對象i。對于每個對象i引用的對象j,將相應的gc_ref_j減1。
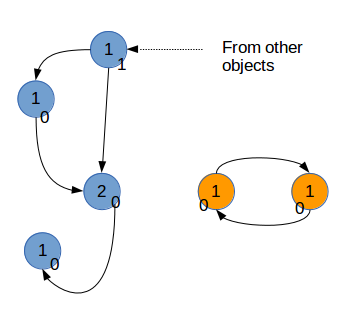
遍歷后的結果
在結束遍歷后,gc_ref不為0的對象,和這些對象引用的對象,以及繼續更下游引用的對象,需要被保留。而其它的對象則被垃圾回收。
關于Python中怎么實現內存管理就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





