溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“常用數據科學Python庫有哪些”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
Pandas
Pandas庫[3]對于致力于探索性數據分析的數據科學家來說是一個必不可少的庫。顧名思義,它使用pandas來分析你的數據,或者更具體地說,pandas數據幀。
以下是一些你可以從HTML報表中訪問和查看的功能:
類型推斷
唯一值
缺少值
分位數統計(例如,中位數)
描述性統計
直方圖
相關性(如皮爾遜)
文本分析
如何安裝?
使用pip:
pip install -U pandas-profiling[notebook] jupyter nbextension enable --py widgetsnbextension 這種方式對我也很管用: pip install pandas-profiling import pandas_profiling
例子:
下面是我們可以從profile report功能訪問的可視化示例之一。可以看到一個易于理解的彩色的相關性可視化圖。
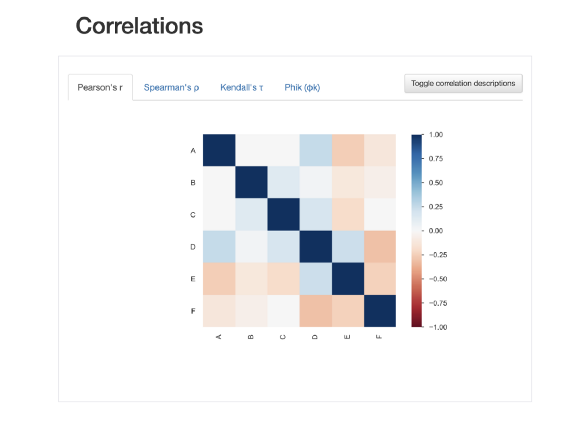
局限性:
如果有一個大的數據集,這個概要報告可能需要相當長的時間。我的解決方案是要么簡單地使用較小的數據集,要么對整個數據集進行采樣。
NLTK
通常與nltk相關的術語是NLP,或者自然語言處理,它是數據科學(和其他學科)的一個分支,它更容易地包含對文本的處理。導入nltk之后,你可以更輕松地分析文本。
以下是你可以使用nltk訪問的一些功能:
標記化文本(例如,[“標記化”,“文本”])
詞性標記
詞干提取和詞形還原
如何安裝:
pip install nltk import nltk
例子:
import nltk thing_to_tokenize = “a long sentence with words” tokens = nltk.word_tokenize(thing_to_tokenize) tokens returns: [“a”, “long”, “sentence”, “with”, “words”]
我們需分開每個單詞,以便對其進行分析。
在某些情況下需要分隔單詞。然后它們可以被標記、計數,機器學習算法的新指標可以使用這些輸入來創建預測。利用nltk的另一個有用的特性是文本可以用于情感分析。情感分析在很多企業中都很重要,尤其是那些有客戶評論的企業。現在我們討論情感分析,讓我們看看另一個有助于快速情感分析的庫。
TextBlob
TextBlob[8]與nltk有很多相同的優點,但是它的情感分析功能非常出色。除了分析之外,它還具有利用樸素貝葉斯和決策樹支持分類的功能。
以下是你可以使用TextBlob訪問的一些功能:
標記化
詞性標注
分類
拼寫更正
情感分析
如何安裝:
pip install textblob from textblob import TextBlob
例子:
情感分析:
review = TextBlob(“here is a great text blob about wonderful Data Science”) review.sentiment returns: Sentiment(polarity=0.80, subjectivity = 0.44)
正常浮點范圍為[-1.0,1.0],而積極情感介于[0.0,1.0]之間。
分類:
from textblob.classifiers import NaiveBayesClassifier training_data = [(‘sentence example good one’, ‘pos’), (‘sentence example great two’, ‘pos’), (‘sentence example bad three’, ‘neg’), (‘sentence example worse four’, ‘neg’)] testing_data = [(‘sentence example good’, ‘pos’), (‘sentence example great’, ‘pos’)] cl = NaiveBayesClassifier(training_data)
你可以使用這個分類器對文本進行分類,該分類器將返回“pos”或“neg”輸出。
這些來自textblob的簡單代碼提供了非常強大和有用的情感分析和分類。
pyLDAvis
另一個使用NLP的工具是pyLDAvis[10]。它是一個交互式主題模型可視化工具的庫。例如,當我使用LDA(潛Dirichlet分布)執行主題模型時,我通常會看到單元格中的主題輸出,這可能很難閱讀。然而當它出現在一個很好的視覺總結中時,它會更有益,也更容易消化,就像pyLDAvis一樣。
以下是你可以使用pyLDAvis訪問的一些功能:
顯示了前30個最突出的術語
有一個交互式調整器,允許你滑動相關性度量
顯示x軸上的PC1和y軸上的PC2的熱門主題
顯示與大小對應的主題
總的來說,這是一種讓人印象深刻的主題可視化方式,這是其他任何庫都無法做到的。
如何安裝:
pip install pyldavis import pyldavis
例子:
為了看到最好的例子,這里有一個Jupyter Notebook[11]參考資料,它展示了這個數據科學庫的許多獨特和有益的特性: https://nbviewer.jupyter.org/github/bmabey/pyLDAvis/blob/master/notebooks/pyLDAvis_overview.ipynb
NetworkX
這個數據科學包NetworkX[13],將其優勢集中在生物、社會和基礎設施網絡可視化上。
以下是你可以使用NetworkX訪問的一些功能:
創建圖形、節點和邊
檢驗圖的元素
圖結構
圖的屬性
多重圖
圖形生成器和操作
如何安裝:
pip install networkx import networkx
例子:
創建圖形
import networkx graph = networkx.Graph()
你可以與其他庫協作,例如matplotlib.pyplot也可以創建圖形的可視化(以數據科學家習慣于看到的方式)。
“常用數據科學Python庫有哪些”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





