溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹StampedLock怎么用,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
面對臨界區資源管理的問題,大體上有2套思路:
第一就是使用悲觀的策略,悲觀者這樣認為:在每一次訪問臨界區的共享變量,總是有人會和我沖突,因此,每次訪問我必須先鎖住整個對象,完成訪問后再解鎖。
而與之相反的樂天派卻認為,雖然臨界區的共享變量會沖突,但是沖突應該是小概率事件,大部分情況下,應該不會發生,所以,我可以先訪問了再說,如果等我用完了數據還沒人沖突,那么我的操作就是成功;如果我使用完成后,發現有人沖突,那么我要么再重試一次,要么切換為悲觀的策略。

從這里不難看到,重入鎖以及synchronized 是一種典型的悲觀策略。聰明的你一定也猜到了,StampedLock就是提供了一種樂觀鎖的工具,因此,它是對重入鎖的一個重要的補充。
在StampedLock的文檔中就提供了一個非常好的例子,讓我們可以很快的理解StampedLock的使用。下面讓我看一下這個例子,有關它的說明,都寫在注釋中了。
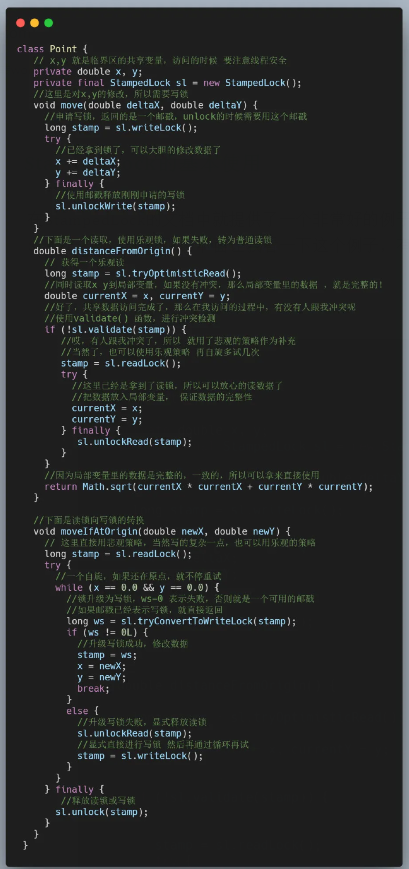
這里再說明一下validate()方法的含義,函數簽名長這樣:
public boolean validate(long stamp)
它的接受參數是上次鎖操作返回的郵戳,如果在調用validate()之前,這個鎖沒有寫鎖申請過,那就返回true,這也表示鎖保護的共享數據并沒有被修改,因此之前的讀取操作是肯定能保證數據完整性和一致性的。
反之,如果鎖在validate()之前有寫鎖申請成功過,那就表示,之前的數據讀取和寫操作沖突了,程序需要進行重試,或者升級為悲觀鎖。
從上面的例子其實不難看到,就編程復雜度來說,StampedLock其實是要比重入鎖復雜的多,代碼也沒有以前那么簡潔了。
最本質的原因,就是為了提升性能!一般來說,這種樂觀鎖的性能要比普通的重入鎖快幾倍,而且隨著線程數量的不斷增加,性能的差距會越來越大。
簡而言之,在大量并發的場景中StampedLock的性能是碾壓重入鎖和讀寫鎖的。
但畢竟,世界上沒有十全十美的東西,StampedLock也并非全能,它的缺點如下:
編碼比較麻煩,如果使用樂觀讀,那么沖突的場景要應用自己處理
它是不可重入的,如果一不小心在同一個線程中調用了兩次,那么你的世界就清凈了。。。。。
它不支持wait/notify機制
如果以上3點對你來說都不是問題,那么我相信StampedLock應該成為你的首選。
為了幫助大家更好的理解StampedLock,這里再簡單給大家介紹一下它的內部實現和數據結構。
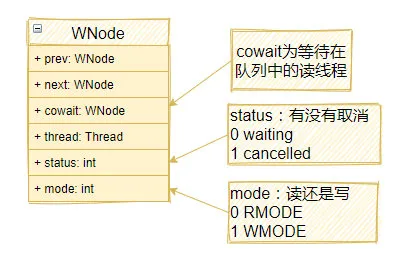
在StampedLock中,有一個隊列,里面存放著等待在鎖上的線程。該隊列是一個鏈表,鏈表中的元素是一個叫做WNode的對象:
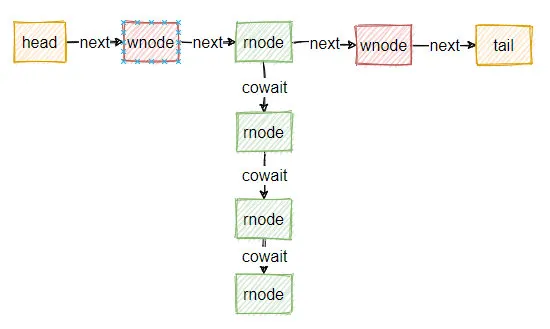
當隊列中有若干個線程等待時,整個隊列可能看起來像這樣的:
除了這個等待隊列,StampedLock中另外一個特別重要的字段就是long state, 這是一個64位的整數,StampedLock對它的使用是非常巧妙的。
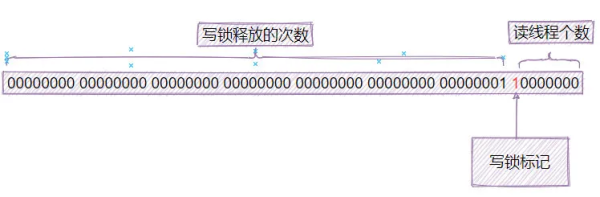
state 的初始值是:
private static final int LG_READERS = 7; private static final long WBIT = 1L << LG_READERS; private static final long ORIGIN = WBIT << 1;
也就是 ...0001 0000 0000 (前面的0太多了,不寫了,湊足64個吧~),為什么這里不用0做初始值呢?因為0有特殊的含義,為了避免沖突,所以選擇了一個非零的數字。
如果有寫鎖占用,那么就讓第7位設置為1 ...0001 1000 0000,也就是加上WBIT。
每次釋放寫鎖,就加1,但不是state直接加,而是去掉最后一個字節,只使用前面的7個字節做統計。因此,釋放寫鎖后,state就變成了:...0010 0000 0000, 再加一次鎖,又變成:...0010 1000 0000,以此類推。
這是因為整個state 的狀態判斷都是基于CAS操作的。而普通的CAS操作可能會遇到ABA的問題,如果不記錄次數,那么當寫鎖釋放掉,申請到,再釋放掉時,我們將無法判斷數據是否被寫過。而這里記錄了釋放的次數,因此出現"釋放->申請->釋放"的時候,CAS操作就可以檢查到數據的變化,從而判斷寫操作已經有發生,作為一個樂觀鎖來說,就可以準確判斷沖突已經產生,剩下的就是交給應用來解決沖突即可。因此,這里記錄釋放鎖的次數,是為了精確地監控線程沖突。
而state剩下的那一個字節的其中7位,用來記錄讀鎖的線程數量,由于只有7位,因此只能記錄可憐的126個,看下面代碼中的RFULL,就是讀線程滿載的數量。超過了怎么辦呢,多余的部分就記錄在readerOverflow字段中。
private static final long WBIT = 1L << LG_READERS; private static final long RBITS = WBIT - 1L; private static final long RFULL = RBITS - 1L; private transient int readerOverflow;
總結一下,state變量的結構如下:
在了解了StampedLock的內部數據結構之后,讓我們再來看一下有關寫鎖的申請和釋放吧!首先是寫鎖的申請:
public long writeLock() { long s, next; return ((((s = state) & ABITS) == 0L && //有沒有讀寫鎖被占用,如果沒有,就設置上寫鎖標記 U.compareAndSwapLong(this, STATE, s, next = s + WBIT)) ? //如果寫鎖占用成功范圍next,如果失敗就進入acquireWrite()進行鎖的占用。 next : acquireWrite(false, 0L)); }如果CAS設置state失敗,表示寫鎖申請失敗,這時,會調用acquireWrite()進行申請或者等待。acquireWrite()大體做了下面幾件事情:
1.入隊
如果頭結點等于尾結點wtail == whead, 表示快輪到我了,所以進行自旋等待,搶到就結束了
如果wtail==null ,說明隊列都沒初始化,就初始化一下隊列
如果隊列中有其他等待結點,那么只能老老實實入隊等待了
2.阻塞并等待
如果頭結點等于前置結點(h = whead) == p), 那說明也快輪到我了,不斷進行自旋等待爭搶
否則喚醒頭結點中的讀線程
如果搶占不到鎖,那么就park()當前線程
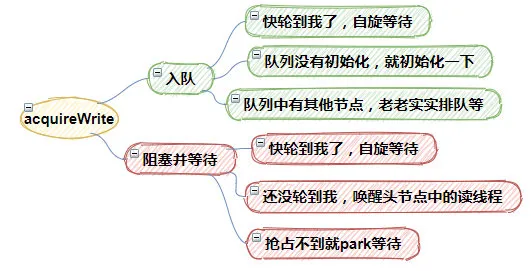
簡單地說,acquireWrite()函數就是用來爭搶鎖的,它的返回值就是代表當前鎖狀態的郵戳,同時,為了提高鎖的性能,acquireWrite()使用大量的自旋重試,因此,它的代碼看起來有點晦澀難懂。
寫鎖的釋放如下所示,unlockWrite()的傳入參數是申請鎖時得到的郵戳:
public void unlockWrite(long stamp) { WNode h; //檢查鎖的狀態是否正常 if (state != stamp || (stamp & WBIT) == 0L) throw new IllegalMonitorStateException(); // 設置state中標志位為0,同時也起到了增加釋放鎖次數的作用 state = (stamp += WBIT) == 0L ? ORIGIN : stamp; // 頭結點不為空,嘗試喚醒后續的線程 if ((h = whead) != null && h.status != 0) //喚醒(unpark)后續的一個線程 release(h); }獲取讀鎖的代碼如下:
public long readLock() { long s = state, next; //如果隊列中沒有寫鎖,并且讀線程個數沒有超過126,直接獲得鎖,并且讀線程數量加1 return ((whead == wtail && (s & ABITS) < RFULL && U.compareAndSwapLong(this, STATE, s, next = s + RUNIT)) ? //如果爭搶失敗,進入acquireRead()爭搶或者等待 next : acquireRead(false, 0L)); }acquireRead()的實現相當復雜,大體上分為這么幾步:
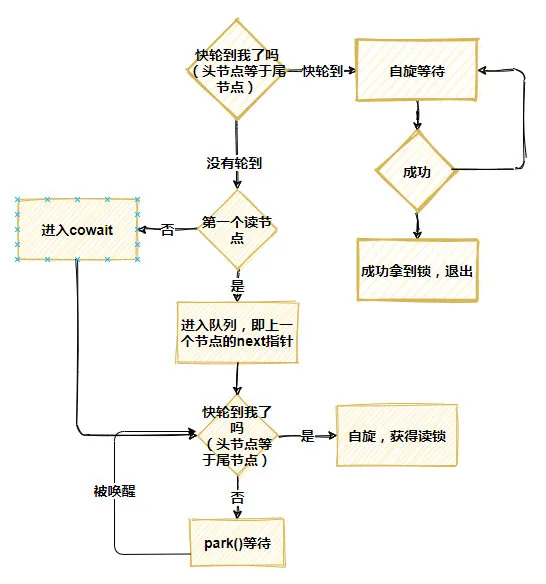
總之,就是自旋,自旋再自旋,通過不斷的自旋來盡可能避免線程被真的掛起,只有當自旋充分失敗后,才會真正讓線程去等待。
下面是釋放讀鎖的過程:

StampedLock固然是個好東西,但是由于它特別復雜,難免也會出現一些小問題。下面這個例子,就演示了StampedLock悲觀鎖瘋狂占用CPU的問題:
public class StampedLockTest { public static void main(String[] args) throws InterruptedException { final StampedLock lock = new StampedLock(); Thread t1 = new Thread(() -> { // 獲取寫鎖 lock.writeLock(); // 模擬程序阻塞等待其他資源 LockSupport.park(); }); t1.start(); // 保證t1獲取寫鎖 Thread.sleep(100); Thread t2 = new Thread(() -> { // 阻塞在悲觀讀鎖 lock.readLock(); }); t2.start(); // 保證t2阻塞在讀鎖 Thread.sleep(100); // 中斷線程t2,會導致線程t2所在CPU飆升 t2.interrupt(); t2.join(); } }上述代碼中,在中斷t2后,t2的CPU占用率就會沾滿100%。而這時候,t2正阻塞在readLock()函數上,換言之,在受到中斷后,StampedLock的讀鎖有可能會占滿CPU。這是什么原因呢?機制的小傻瓜一定想到了,這是因為StampedLock內太多的自旋引起的!沒錯,你的猜測是正確的。
如果沒有中斷,那么阻塞在readLock()上的線程在經過幾次自旋后,會進入park()等待,一旦進入park()等待,就不會占用CPU了。但是park()這個函數有一個特點,就是一旦線程被中斷,park()就會立即返回,返回還不算,它也不給你拋點異常啥的,那這就尷尬了。本來呢,你是想在鎖準備好的時候,unpark()的線程的,但是現在鎖沒好,你直接中斷了,park()也返回了,但是,畢竟鎖沒好,所以就又去自旋了。
轉著轉著,又轉到了park()函數,但悲催的是,線程的中斷標記一直打開著,park()就阻塞不住了,于是乎,下一個自旋又開始了,沒完沒了的自旋停不下來了,所以CPU就爆滿了。
要解決這個問題,本質上需要在StampedLock內部,在park()返回時,需要判斷中斷標記為,并作出正確的處理,比如,退出,拋異常,或者把中斷位給清理一下,都可以解決問題。
但很不幸,至少在JDK8里,還沒有這樣的處理。因此就出現了上面的,中斷readLock()后,CPU爆滿的問題。請大家一定要注意。
以上是“StampedLock怎么用”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





