溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了Python中怎么定位元素,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
確定網站沒有設置反爬措施,是否能直接返回待解析的內容:
import requests url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text print(response)
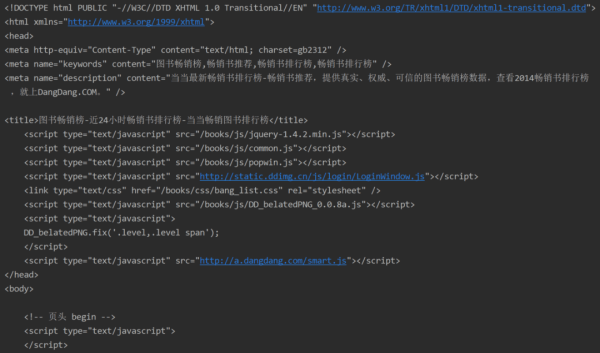
仔細檢查后發現需要的數據都在返回內容中,說明不需要特別考慮反爬舉措
審查網頁元素后可以發現,書目信息都包含在 li 中,從屬于 class 為 bang_list clearfix bang_list_mode 的 ul 中
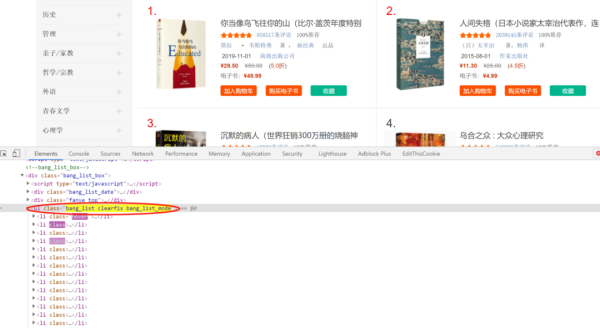
進一步審查也可以發現書名在的相應位置,這是多種解析方法的重要基礎

1. 傳統 BeautifulSoup 操作
經典的 BeautifulSoup 方法借助 from bs4 import BeautifulSoup,然后通過 soup = BeautifulSoup(html, "lxml") 將文本轉換為特定規范的結構,利用 find 系列方法進行解析,代碼如下:
import requests from bs4 import BeautifulSoup url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text def bs_for_parse(response): soup = BeautifulSoup(response, "lxml") li_list = soup.find('ul', class_='bang_list clearfix bang_list_mode').find_all('li') # 鎖定ul后獲取20個li for li in li_list: title = li.find('div', class_='name').find('a')['title'] # 逐個解析獲取書名 print(title) if __name__ == '__main__': bs_for_parse(response)
成功獲取了 20 個書名,有些書面顯得冗長可以通過正則或者其他字符串方法處理,本文不作詳細介紹
2. 基于 BeautifulSoup 的 CSS 選擇器
這種方法實際上就是 PyQuery 中 CSS 選擇器在其他模塊的遷移使用,用法是類似的。關于 CSS 選擇器詳細語法可以參考:http://www.w3school.com.cn/cssref/css_selectors.asp由于是基于 BeautifulSoup 所以導入的模塊以及文本結構轉換都是一致的:
import requests from bs4 import BeautifulSoup url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text def css_for_parse(response): soup = BeautifulSoup(response, "lxml") print(soup) if __name__ == '__main__': css_for_parse(response)
然后就是通過 soup.select 輔以特定的 CSS 語法獲取特定內容,基礎依舊是對元素的認真審查分析:
import requests from bs4 import BeautifulSoup from lxml import html url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text def css_for_parse(response): soup = BeautifulSoup(response, "lxml") li_list = soup.select('ul.bang_list.clearfix.bang_list_mode > li') for li in li_list: title = li.select('div.name > a')[0]['title'] print(title) if __name__ == '__main__': css_for_parse(response)3. XPath
XPath 即為 XML 路徑語言,它是一種用來確定 XML 文檔中某部分位置的計算機語言,如果使用 Chrome 瀏覽器建議安裝 XPath Helper 插件,會大大提高寫 XPath 的效率。
之前的爬蟲文章基本都是基于 XPath,大家相對比較熟悉因此代碼直接給出:
import requests from lxml import html url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text def xpath_for_parse(response): selector = html.fromstring(response) books = selector.xpath("//ul[@class='bang_list clearfix bang_list_mode']/li") for book in books: title = book.xpath('div[@class="name"]/a/@title')[0] print(title) if __name__ == '__main__': xpath_for_parse(response)4. 正則表達式如果對 HTML 語言不熟悉,那么之前的幾種解析方法都會比較吃力。這里也提供一種萬能解析大法:正則表達式,只需要關注文本本身有什么特殊構造文法,即可用特定規則獲取相應內容。依賴的模塊是 re
首先重新觀察直接返回的內容中,需要的文字前后有什么特殊:
import requests import re url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text print(response)


觀察幾個數目相信就有答案了:<div class="name"><a href="http://product.dangdang.com/xxxxxxxx.html" target="_blank" title="xxxxxxx">
書名就藏在上面的字符串中,蘊含的網址鏈接中末尾的數字會隨著書名而改變。
分析到這里正則表達式就可以寫出來了:
import requests import re url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text def re_for_parse(response): reg = '<div class="name"><a href="http://product.dangdang.com/\d+.html" target="_blank" title="(.*?)">' for title in re.findall(reg, response): print(title) if __name__ == '__main__': re_for_parse(response)
可以發現正則寫法是最簡單的,但是需要對于正則規則非常熟練。所謂正則大法好!
當然,不論哪種方法都有它所適用的場景,在真實操作中我們也需要在分析網頁結構來判斷如何高效的定位元素,最后附上本文介紹的四種方法的完整代碼,大家可以自行操作一下來加深體會
import requests from bs4 import BeautifulSoup from lxml import html import re url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text def bs_for_parse(response): soup = BeautifulSoup(response, "lxml") li_list = soup.find('ul', class_='bang_list clearfix bang_list_mode').find_all('li') for li in li_list: title = li.find('div', class_='name').find('a')['title'] print(title) def css_for_parse(response): soup = BeautifulSoup(response, "lxml") li_list = soup.select('ul.bang_list.clearfix.bang_list_mode > li') for li in li_list: title = li.select('div.name > a')[0]['title'] print(title) def xpath_for_parse(response): selector = html.fromstring(response) books = selector.xpath("//ul[@class='bang_list clearfix bang_list_mode']/li") for book in books: title = book.xpath('div[@class="name"]/a/@title')[0] print(title) def re_for_parse(response): reg = '<div class="name"><a href="http://product.dangdang.com/\d+.html" target="_blank" title="(.*?)">' for title in re.findall(reg, response): print(title) if __name__ == '__main__': # bs_for_parse(response) # css_for_parse(response) # xpath_for_parse(response) re_for_parse(response)上述內容就是Python中怎么定位元素,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





