溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關Selenium中怎么實現網頁元素定位,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
除了根據元素的id值來查找元素外,Selenium還提供了很多查找元素的方法:
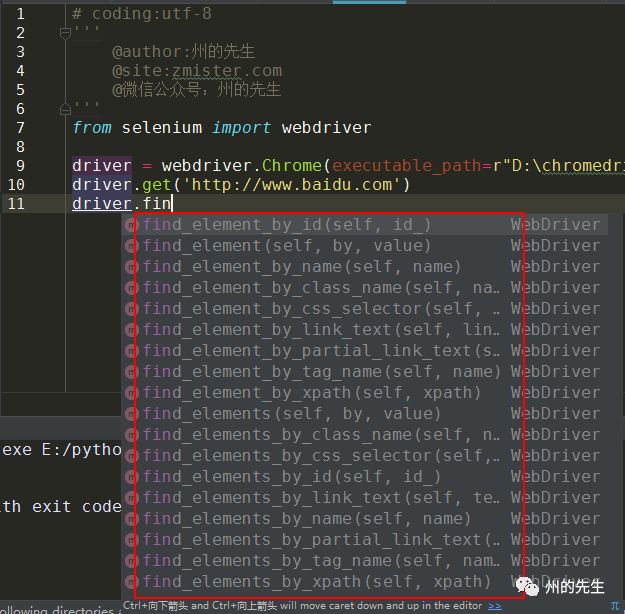
從上圖中可以看到,Selenium提供了近二十個find_element族的方法來供我們在頁面中查找元素,其中包括id、name、類名、css選擇器、鏈接文本、標簽名、xpath等。
定位單個匹配元素的方法有:
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
定位多個匹配元素的方法有:
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
我們可以根據不同頁面的不同情況來查找定位到我們所需要的頁面元素。
如果你知道元素的id屬性值,那么可以使用find_element_by_id()方法來定位元素,其將返回id屬性值與該位置匹配的第一個元素。
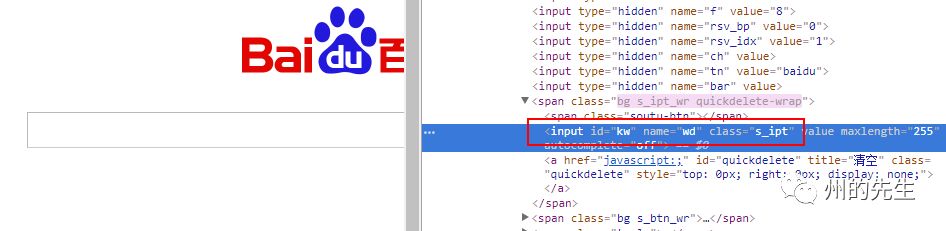
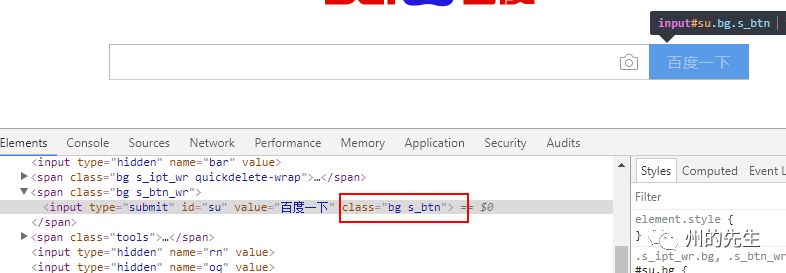
百度首頁的搜索框結構如下圖:
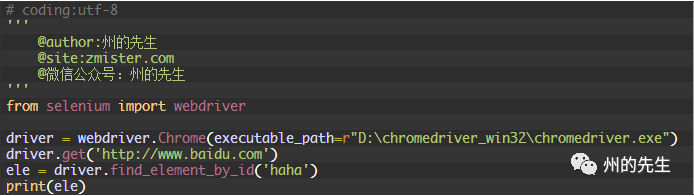
ele返回的是一個對應的element元素:

如果沒有元素匹配傳入的id值,將會拋出一個NoSuchElementException異常:
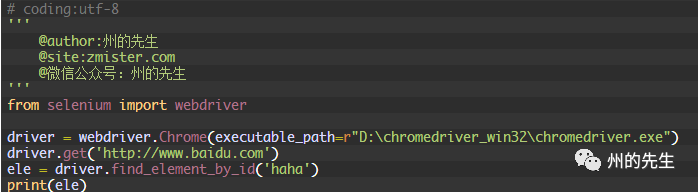
運行代碼,因為沒有匹配的id值,所以拋出了異常:

如果你知道元素的name屬性值,那么可以使用find_element_by_name()方法獲取第一個匹配name屬性值的元素:
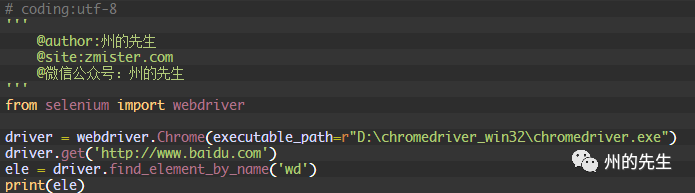
ele返回匹配到的element元素:
C:\Python35\python.exe E:/pythonproject/selenium_env/code/2.py
<selenium.webdriver.remote.webelement.WebElement (session="23d00cea9ce99d36ffcac96cfb3ca12c", element="0.7355927465563321-1")>
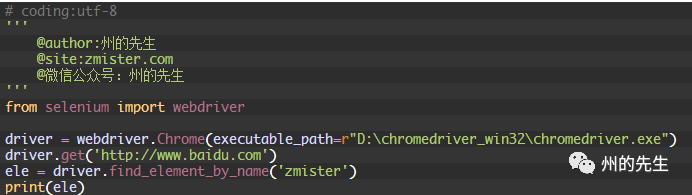
如果定位一個沒有的name屬性值,那么也會拋出NoSuchElementException異常:

XPath是用于在XML文檔中查找節點的一種語言。由于HTML可以是XML(XHTML)的實現,因此我們可以利用這種強大的語言在網頁中進行元素的定位。XPath擴展并支持了通過id或name屬性定位的簡單方法,并提供了各種新的操作,例如在頁面上查找第三個復選框等。
使用Xpath的一個原因是,有時候頁面上我們需要定位的元素并沒有id屬性和name屬性,這時候就可以用Xpath以絕對路徑的方式進行元素定位,或者是通過id或name屬性值定位到父元素再取到子元素。
對于Xpath的知識,在此不做介紹,有需要的同學看看專門介紹Xpath的網站或教程,比如:
W3schhool Xpath教程
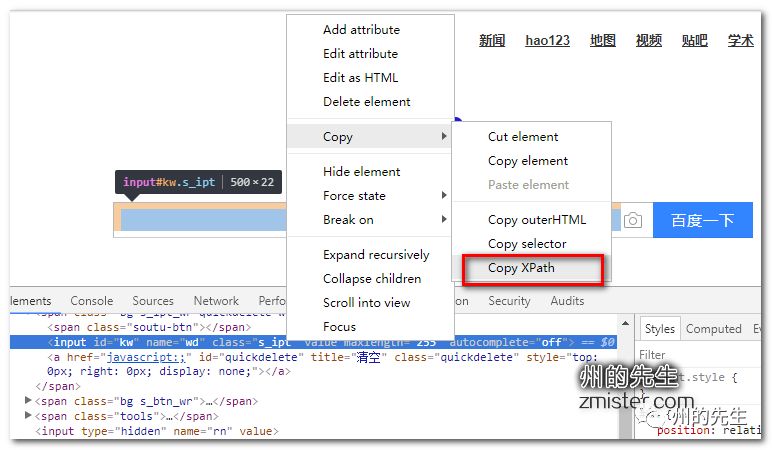
在此我們簡單介紹一下如何快速地通過瀏覽器獲取到頁面元素的Xpath路徑。在瀏覽器中打開網頁調試控制臺,在需要定位的元素上,單擊鼠標右鍵,會出現一個選項欄,在“copy”中選擇“Copy XPath”即可:
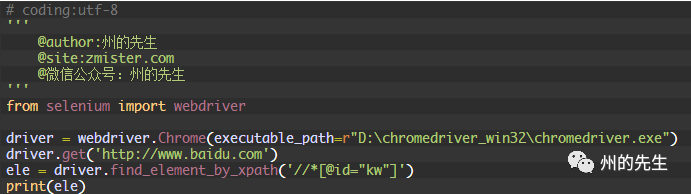
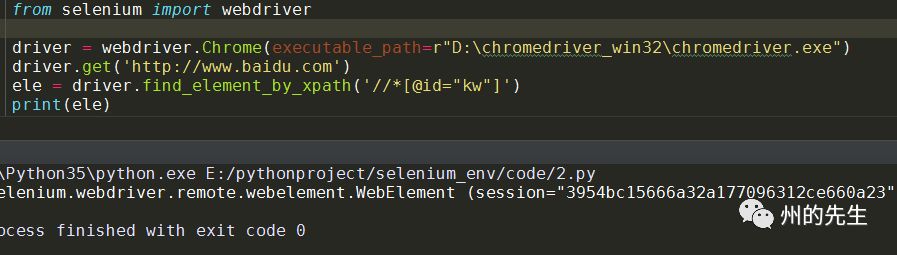
這樣,我們通過XPath路徑也能夠定位到百度首頁搜索框:
當我們想通過元素的標簽名稱來定位一個元素時,可以使用find_element_by_tag_name()這個方法,其將返回具有給定標簽名稱的第一個元素:
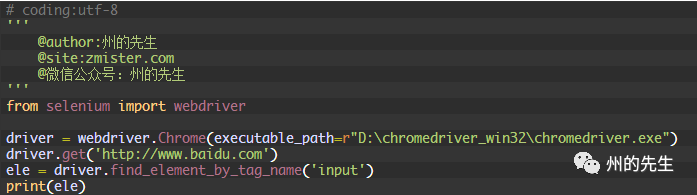
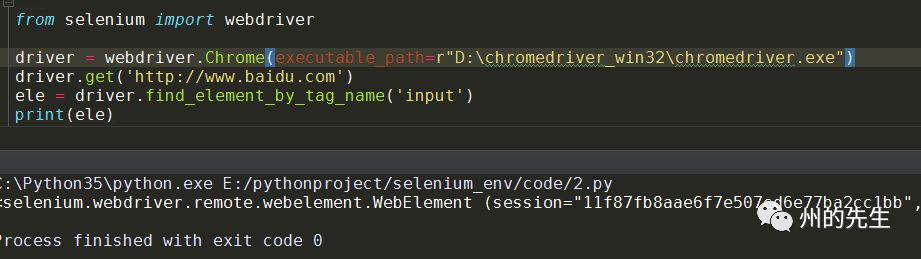
在這里,我們直接通過input的元素標簽名來進行定位,因為百度首頁上第一個input為搜索框,所以我們也能夠定位到:
如果匹配不到,同樣會拋出NoSuchElementException異常。
如果我們想通過元素的class屬性值來定位,那么可以使用find_element_by_class_name()方法。其將返回匹配的第一個元素,如果沒有匹配的元素,同樣會拋出NoSuchElementException異常:
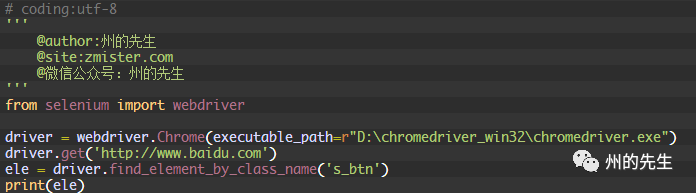
在這里,我們通過class類名定位了百度首頁的搜索按鈕。
CSS選擇器是一種通過元素的CSS屬性值來定位元素的語法,我們可以使用find_element_by_css_selector()方法通過css選擇器定位元素:
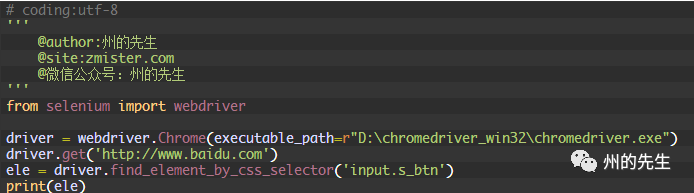
CSS選擇器的絕對語法我們可以通過瀏覽器調試控制臺中的“Copy”獲取到:
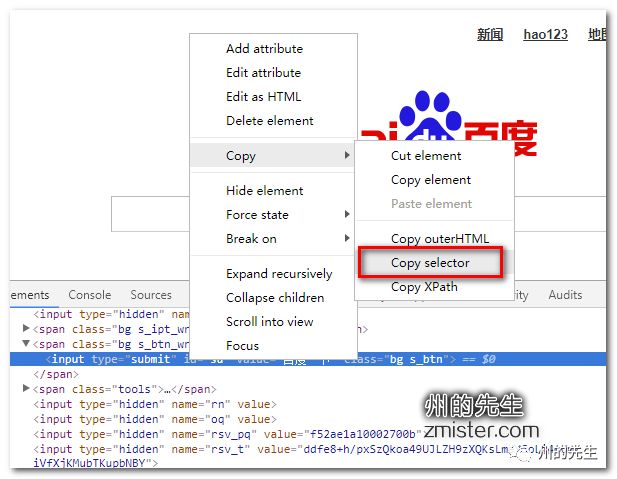
除了上述的元素定位方式,我們還可以通過a標簽上的文字進行元素定位,使用的是find_element_by_link_text()方法。
在百度首頁的最頂部,是有一排鏈接的,如下圖:

如果我們需要定位到“地圖”那個鏈接元素上,就可以這樣操作:
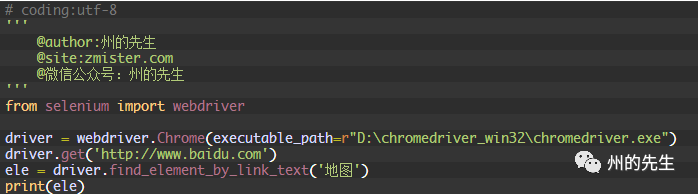
這樣就成功的地位到了元素:

同樣的,如果匹配不到,也會拋出NoSuchElementException異常:
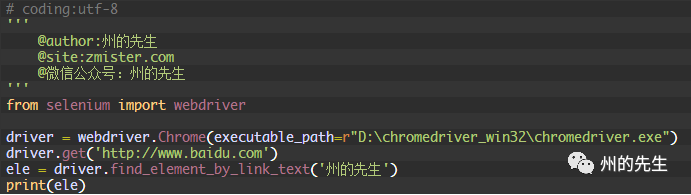
匹配不到鏈接文字為“州的先生”的元素:

上述就是小編為大家分享的Selenium中怎么實現網頁元素定位了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





