溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Linux性能分析工具有哪些,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
出于對Linux操作系統的興趣,以及對底層知識的強烈欲望,因此整理了這篇文章。本文也可以作為檢驗基礎知識的指標,另外文章涵蓋了一個系統的方方面面。如果沒有完善的計算機系統知識,網絡知識和操作系統知識,文檔中的工具,是不可能完全掌握的,另外對系統性能分析和優化是一個長期的系列。
首先來看一張圖:
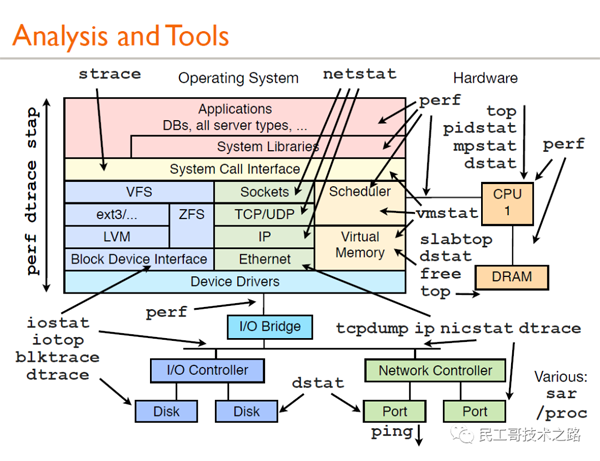
上圖是Brendan Gregg 的一次性能分析的分享,這里面的所有工具都可以通過man來獲得它的幫助文檔,下問簡單介紹介紹一下常規的用法:
vmstat(VirtualMeomoryStatistics,虛擬內存統計) 是Linux中監控內存的常用工具,可對操作系統的虛擬內存、進程、CPU等的整體情況進行監視。
vmstat的常規用法:vmstat interval times即每隔interval秒采樣一次,共采樣times次,如果省略times,則一直采集數據,直到用戶手動停止為止。簡單舉個例子:

可以使用ctrl+c停止vmstat采集數據。
第一行顯示了系統自啟動以來的平均值,第二行開始顯示現在正在發生的情況,接下來的行會顯示每5秒間隔發生了什么,每一列的含義在頭部,如下所示:
procs:r這一列顯示了多少進程在等待cpu,b列顯示多少進程正在不可中斷的休眠(等待IO)。
memory:swapd列顯示了多少塊被換出了磁盤(頁面交換),剩下的列顯示了多少塊是空閑的(未被使用),多少塊正在被用作緩沖區,以及多少正在被用作操作系統的緩存。
swap:顯示交換活動:每秒有多少塊正在被換入(從磁盤)和換出(到磁盤)。
io:顯示了多少塊從塊設備讀取(bi)和寫出(bo),通常反映了硬盤I/O。
system:顯示每秒中斷(in)和上下文切換(cs)的數量。
cpu:顯示所有的cpu時間花費在各類操作的百分比,包括執行用戶代碼(非內核),執行系統代碼(內核),空閑以及等待IO。
內存不足的表現:free memory急劇減少,回收buffer和cacher也無濟于事,大量使用交換分區(swpd),頁面交換(swap)頻繁,讀寫磁盤數量(io)增多,缺頁中斷(in)增多,上下文切換(cs)次數增多,等待IO的進程數(b)增多,大量CPU時間用于等待IO(wa)
iostat用于報告中央處理器(CPU)統計信息和整個系統、適配器、tty 設備、磁盤和 CD-ROM 的輸入/輸出統計信息,默認顯示了與vmstat相同的cpu使用信息,使用以下命令顯示擴展的設備統計:

第一行顯示的是自系統啟動以來的平均值,然后顯示增量的平均值,每個設備一行。
常見linux的磁盤IO指標的縮寫習慣:rq是request,r是read,w是write,qu是queue,sz是size,a是verage,tm是time,svc是service。
rrqm/s和wrqm/s:每秒合并的讀和寫請求,“合并的”意味著操作系統從隊列中拿出多個邏輯請求合并為一個請求到實際磁盤。
r/s和w/s:每秒發送到設備的讀和寫請求數。
rsec/s和wsec/s:每秒讀和寫的扇區數。
avgrq –sz:請求的扇區數。
avgqu –sz:在設備隊列中等待的請求數。
await:每個IO請求花費的時間。
svctm:實際請求(服務)時間。
%util:至少有一個活躍請求所占時間的百分比。
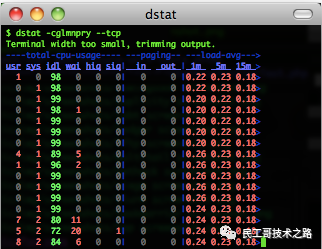
dstat顯示了cpu使用情況,磁盤io情況,網絡發包情況和換頁情況,輸出是彩色的,可讀性較強,相對于vmstat和iostat的輸入更加詳細且較為直觀。在使用時,直接輸入命令即可,當然也可以使用特定參數。
如下:dstat –cdlmnpsy
iotop命令是專門顯示硬盤IO的命令,界面風格類似top命令,可以顯示IO負載具體是由哪個進程產生的。是一個用來監視磁盤I/O使用狀況的top類工具,具有與top相似的UI,其中包括PID、用戶、I/O、進程等相關信息。
可以以非交互的方式使用:
iotop –bod interval,查看每個進程的I/O,可以使用pidstat,pidstat –d instat
pidstat主要用于監控全部或指定進程占用系統資源的情況,如CPU,內存、設備IO、任務切換、線程等。
使用方法:
pidstat –d interval #統計CPU使用信息 pidstat –u interval #統計內存信息 Pidstat –r interval
top命令的匯總區域顯示了五個方面的系統性能信息:
負載:時間,登陸用戶數,系統平均負載;
進程:運行,睡眠,停止,僵尸;
cpu:用戶態,核心態,NICE,空閑,等待IO,中斷等;
內存:總量,已用,空閑(系統角度),緩沖,緩存;
交換分區:總量,已用,空閑
任務區域默認顯示:進程ID,有效用戶,進程優先級,NICE值,進程使用的虛擬內存,物理內存和共享內存,進程狀態,CPU占用率,內存占用率,累計CPU時間,進程命令行信息。
htop 是Linux系統中的一個互動的進程查看器,一個文本模式的應用程序(在控制臺或者X終端中),需要ncurses。
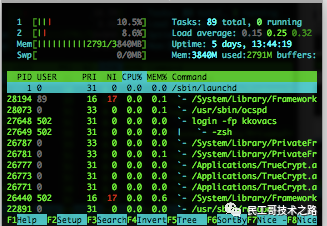
Htop可讓用戶交互式操作,支持顏色主題,可橫向或縱向滾動瀏覽進程列表,并支持鼠標操作。
與top相比,htop有以下優點:
可以橫向或者縱向滾動瀏覽進程列表,以便看到所有的進程和完整的命令行。
在啟動上,比top更快。
殺進程時不需要輸入進程號。
htop支持鼠標操作。
mpstat 是Multiprocessor Statistics的縮寫,是實時系統監控工具。其報告與CPU的一些統計信息,這些信息存放在/proc/stat文件中。在多CPUs系統里,其不但能查看所有CPU的平均狀況信息,而且能夠查看特定CPU的信息。常見用法:
mpstat –P ALL interval times
Netstat用于顯示與IP、TCP、UDP和ICMP協議相關的統計數據,一般用于檢驗本機各端口的網絡連接情況。
常見用法:
netstat –npl #可以查看你要打開的端口是否已經打開。 netstat –rn #打印路由表信息。 netstat –in #提供系統上的接口信息,打印每個接口的MTU,輸入分組數,輸入錯誤,輸出分組數,輸出錯誤,沖突以及當前的輸出隊列的長度。
ps參數太多,具體使用方法可以參考man ps,
常用的方法:
ps aux #hsserver ps –ef |grep #hundsun #殺掉某一程序的方法 ps aux | grep mysqld | grep –v grep | awk ‘{print $2 }’ xargs kill -9 #殺掉僵尸進程 ps –eal | awk ‘{if ($2 == “Z”){print $4}}’ | xargs kill -9
跟蹤程序執行過程中產生的系統調用及接收到的信號,幫助分析程序或命令執行中遇到的異常情況。
舉例:查看mysqld在linux上加載哪種配置文件,可以通過運行下面的命令:
strace –e stat64 mysqld –print –defaults > /dev/null
能夠打印系統總共運行了多長時間和系統的平均負載,uptime命令最后輸出的三個數字的含義分別是1分鐘,5分鐘,15分鐘內系統的平均負荷。
lsof(list open files)是一個列出當前系統打開文件的工具。通過lsof工具能夠查看這個列表對系統檢測及排錯,常見的用法:
#查看文件系統阻塞 lsof /boot #查看端口號被哪個進程占用 lsof -i : 3306 #查看用戶打開哪些文件 lsof –u username #查看進程打開哪些文件 lsof –p 4838 #查看遠程已打開的網絡鏈接 lsof –i @192.168.34.128
perf是Linux kernel自帶的系統性能優化工具。優勢在于與Linux Kernel的緊密結合,它可以最先應用到加入Kernel的new feature,用于查看熱點函數,查看cashe miss的比率,從而幫助開發者來優化程序性能。
性能調優工具如 perf,Oprofile 等的基本原理都是對被監測對象進行采樣,最簡單的情形是根據 tick 中斷進行采樣,即在 tick 中斷內觸發采樣點,在采樣點里判斷程序當時的上下文。假如一個程序 90% 的時間都花費在函數 foo() 上,那么 90% 的采樣點都應該落在函數 foo() 的上下文中。運氣不可捉摸,但我想只要采樣頻率足夠高,采樣時間足夠長,那么以上推論就比較可靠。因此,通過 tick 觸發采樣,我們便可以了解程序中哪些地方最耗時間,從而重點分析。
匯總:結合以上常用的性能測試命令并聯系文初的性能分析工具的圖,就可以初步了解到性能分析過程中哪個方面的性能使用哪方面的工具(命令)。
熟練并精通了第二部分的性能分析命令工具,引入幾個性能測試的工具,介紹之前先簡單了解幾個性能測試工具:
一款隨 Linux 內核代碼一同發布和維護的性能診斷工具,由內核社區維護和發展。Perf 不僅可以用于應用程序的性能統計分析,也可以應用于內核代碼的性能統計和分析。
一款使用bcc進行的性能追蹤的工具,eBPF map可以使用定制的eBPF程序被廣泛應用于內核調優方面,也可以讀取用戶級的異步代碼。重要的是這個外部的數據可以在用戶空間管理。這個k-v格式的map數據體是通過在用戶空間調用bpf系統調用創建、添加、刪除等操作管理的。
一款基于 perf_events (perf) 和 ftrace 的Linux性能分析調優工具集。Perf-Tools 依賴庫少,使用簡單。支持Linux 3.2 及以上內核版本。
一款使用eBPF的perf性能分析工具。一個用于創建高效的內核跟蹤和操作程序的工具包,包括幾個有用的工具和示例。利用擴展的BPF(伯克利數據包過濾器),正式稱為eBPF,一個新的功能,首先被添加到Linux 3.15。多用途需要Linux 4.1以上BCC。
一種新型的linux腳本動態性能跟蹤工具。允許用戶跟蹤Linux內核動態。ktap是設計給具有互操作性,允許用戶調整操作的見解,排除故障和延長內核和應用程序。它類似于Linux和Solaris DTrace SystemTap。
是一款使用perf,system tap,ktap可視化的圖形軟件,允許最頻繁的代碼路徑快速準確地識別,可以是使用github.com/brendangregg/flamegraph中的開發源代碼的程序生成。
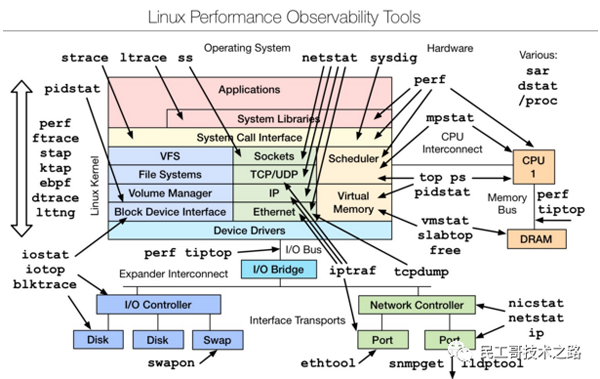
uptime、top(htop)、mpstat、isstat、vmstat、free、ping、nicstat、dstat。
sar、netstat、pidstat、strace、tcpdump、blktrace、iotop、slabtop、sysctl、/proc。
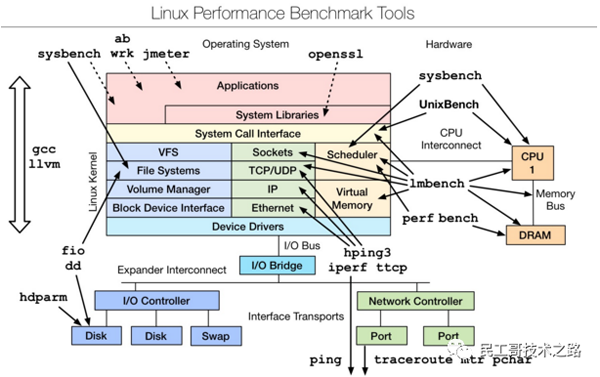
是一款性能測評工具,對于不同模塊的性能測試可以使用相應的工具,想要深入了解,可以參考最下文的附件文檔。
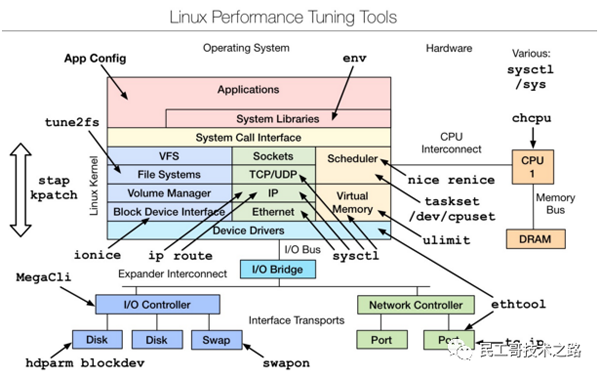
是一款性能調優工具,主要是從linux內核源碼層進行的調優,想要深入了解,可以參考下文附件文檔。
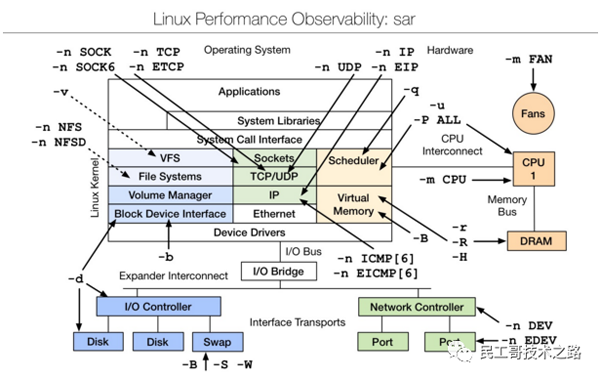
sar(System Activity Reporter系統活動情況報告)是目前LINUX上最為全面的系統性能分析工具之一,可以從多方面對系統的活動進行報告,包括:文件的讀寫情況、系統調用的使用情況、磁盤I/O、CPU效率、內存使用狀況、進程活動及IPC有關的活動等方面。
sar的常歸使用方式:
sar [options] [-A] [-o file] t [n]
其中:
t #為采樣間隔,n為采樣次數,默認值是1; -o file #表示將命令結果以二進制格式存放在文件中,file 是文件名。 options #為命令行選項
看完上述內容,你們掌握Linux性能分析工具有哪些的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





