溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“如何使用Unsafe類”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“如何使用Unsafe類”吧!

首先我們來嘗試獲取一個Unsafe實例,如果按照new的方式去創建對象,不好意思,編譯器會報錯提示你:
Unsafe() has private access in 'sun.misc.Unsafe'
查看Unsafe類的源碼,可以看到它被final修飾不允許被繼承,并且構造函數為private類型,即不允許我們手動調用構造方法進行實例化,只有在static靜態代碼塊中,以單例的方式初始化了一個Unsafe對象:
public final class Unsafe { private static final Unsafe theUnsafe; ... private Unsafe() { } ... static { theUnsafe = new Unsafe(); } }在Unsafe類中,提供了一個靜態方法getUnsafe,看上去貌似可以用它來獲取Unsafe實例:
@CallerSensitive public static Unsafe getUnsafe() { Class var0 = Reflection.getCallerClass(); if (!VM.isSystemDomainLoader(var0.getClassLoader())) { throw new SecurityException("Unsafe"); } else { return theUnsafe; } }但是如果我們直接調用這個靜態方法,會拋出異常:
Exception in thread "main" java.lang.SecurityException: Unsafe at sun.misc.Unsafe.getUnsafe(Unsafe.java:90) at com.cn.test.GetUnsafeTest.main(GetUnsafeTest.java:12)
這是因為在getUnsafe方法中,會對調用者的classLoader進行檢查,判斷當前類是否由Bootstrap classLoader加載,如果不是的話那么就會拋出一個SecurityException異常。也就是說,只有啟動類加載器加載的類才能夠調用Unsafe類中的方法,來防止這些方法在不可信的代碼中被調用。
那么,為什么要對Unsafe類進行這么謹慎的使用限制呢,說到底,還是因為它實現的功能過于底層,例如直接進行內存操作、繞過jvm的安全檢查創建對象等等,概括的來說,Unsafe類實現功能可以被分為下面8類:
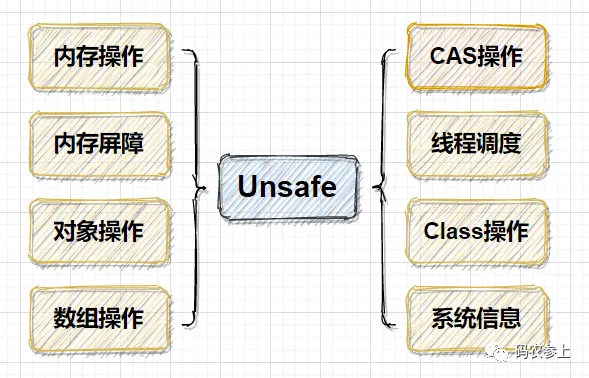
看到上面的這些功能,你是不是已經有些迫不及待想要試一試了。那么如果我們執意想要在自己的代碼中調用Unsafe類的方法,應該怎么獲取一個它的實例對象呢,答案是利用反射獲得Unsafe類中已經實例化完成的單例對象:
public static Unsafe getUnsafe() throws IllegalAccessException { Field unsafeField = Unsafe.class.getDeclaredField("theUnsafe"); //Field unsafeField = Unsafe.class.getDeclaredFields()[0]; //也可以這樣,作用相同 unsafeField.setAccessible(true); Unsafe unsafe =(Unsafe) unsafeField.get(null); return unsafe; }在獲取到Unsafe的實例對象后,我們就可以使用它為所欲為了,先來嘗試使用它對一個對象的屬性進行讀寫:
public void fieldTest(Unsafe unsafe) throws NoSuchFieldException { User user=new User(); long fieldOffset = unsafe.objectFieldOffset(User.class.getDeclaredField("age")); System.out.println("offset:"+fieldOffset); unsafe.putInt(user,fieldOffset,20); System.out.println("age:"+unsafe.getInt(user,fieldOffset)); System.out.println("age:"+user.getAge()); }運行代碼輸出如下,可以看到通過Unsafe類的objectFieldOffset方法獲取了對象中字段的偏移地址,這個偏移地址不是內存中的絕對地址而是一個相對地址,之后再通過這個偏移地址對int類型字段的屬性值進行了讀寫操作,通過結果也可以看到Unsafe的方法和類中的get方法獲取到的值是相同的。
offset:12 age:20 age:20
在上面的例子中調用了Unsafe類的putInt和getInt方法,看一下源碼中的方法:
public native int getInt(Object o, long offset); public native void putInt(Object o, long offset, int x);
先說作用,getInt用于從對象的指定偏移地址處讀取一個int,putInt用于在對象指定偏移地址處寫入一個int,并且即使類中的這個屬性是private私有類型的,也可以對它進行讀寫。但是有細心的小伙伴可能發現了,這兩個方法相對于我們平常寫的普通方法,多了一個native關鍵字修飾,并且沒有具體的方法邏輯,那么它是怎么實現的呢?
在java中,這類方法被稱為native方法(Native Method),簡單的說就是由java調用非java代碼的接口,被調用的方法是由非java 語言實現的,例如它可以由C或C++語言來實現,并編譯成DLL,然后直接供java進行調用。native方法是通過JNI(Java Native Interface)實現調用的,從 java1.1開始 JNI 標準就是java平臺的一部分,它允許java代碼和其他語言的代碼進行交互。

Unsafe類中的很多基礎方法都屬于native方法,那么為什么要使用native方法呢?原因可以概括為以下幾點:
需要用到 java 中不具備的依賴于操作系統的特性,java在實現跨平臺的同時要實現對底層的控制,需要借助其他語言發揮作用
對于其他語言已經完成的一些現成功能,可以使用java直接調用
程序對時間敏感或對性能要求非常高時,有必要使用更加底層的語言,例如C/C++甚至是匯編
在juc包的很多并發工具類在實現并發機制時,都調用了native方法,通過它們打破了java運行時的界限,能夠接觸到操作系統底層的某些功能。對于同一個native方法,不同的操作系統可能會通過不同的方式來實現,但是對于使用者來說是透明的,最終都會得到相同的結果,至于java如何實現的通過JNI調用其他語言的代碼,不是本文的重點,會在后續的文章中具體學習。
在對Unsafe的基礎有了一定了解后,我們來看一下它的基本應用。由于篇幅有限,不能對所有方法進行介紹,如果大家有學習的需要,可以下載openJDK的源碼進行學習。
如果你是一個寫過c或者c++的程序員,一定對內存操作不會陌生,而在java中是不允許直接對內存進行操作的,對象內存的分配和回收都是由jvm自己實現的。但是在Unsafe中,提供的下列接口可以直接進行內存操作:
//分配新的本地空間 public native long allocateMemory(long bytes); //重新調整內存空間的大小 public native long reallocateMemory(long address, long bytes); //將內存設置為指定值 public native void setMemory(Object o, long offset, long bytes, byte value); //內存拷貝 public native void copyMemory(Object srcBase, long srcOffset,Object destBase, long destOffset,long bytes); //清除內存 public native void freeMemory(long address);
使用下面的代碼進行測試:
private void memoryTest() { int size = 4; long addr = unsafe.allocateMemory(size); long addr3 = unsafe.reallocateMemory(addr, size * 2); System.out.println("addr: "+addr); System.out.println("addr3: "+addr3); try { unsafe.setMemory(null,addr ,size,(byte)1); for (int i = 0; i < 2; i++) { unsafe.copyMemory(null,addr,null,addr3+size*i,4); } System.out.println(unsafe.getInt(addr)); System.out.println(unsafe.getLong(addr3)); }finally { unsafe.freeMemory(addr); unsafe.freeMemory(addr3); } }先看結果輸出:
addr: 2433733895744 addr3: 2433733894944 16843009 72340172838076673
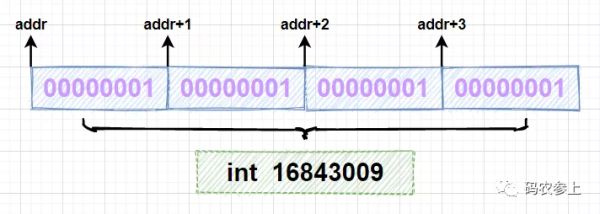
分析一下運行結果,首先使用allocateMemory方法申請4字節長度的內存空間,在循環中調用setMemory方法向每個字節寫入內容為byte類型的1,當使用Unsafe調用getInt方法時,因為一個int型變量占4個字節,會一次性讀取4個字節,組成一個int的值,對應的十進制結果為16843009,可以通過圖示理解這個過程:
在代碼中調用reallocateMemory方法重新分配了一塊8字節長度的內存空間,通過比較addr和addr3可以看到和之前申請的內存地址是不同的。在代碼中的第二個for循環里,調用copyMemory方法進行了兩次內存的拷貝,每次拷貝內存地址addr開始的4個字節,分別拷貝到以addr3和addr3+4開始的內存空間上:
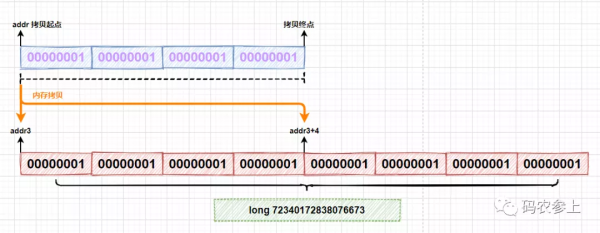
拷貝完成后,使用getLong方法一次性讀取8個字節,得到long類型的值為72340172838076673。
需要注意,通過這種方式分配的內存屬于堆外內存,是無法進行垃圾回收的,需要我們把這些內存當做一種資源去手動調用freeMemory方法進行釋放,否則會產生內存泄漏。通用的操作內存方式是在try中執行對內存的操作,最終在finally塊中進行內存的釋放。
在介紹內存屏障前,需要知道編譯器和CPU會在保證程序輸出結果一致的情況下,會對代碼進行重排序,從指令優化角度提升性能。而指令重排序可能會帶來一個不好的結果,導致CPU的高速緩存和內存中數據的不一致,而內存屏障(Memory Barrier)就是通過組織屏障兩邊的指令重排序從而避免編譯器和硬件的不正確優化情況。
在硬件層面上,內存屏障是CPU為了防止代碼進行重排序而提供的指令,不同的硬件平臺上實現內存屏障的方法可能并不相同。在java8中,引入了3個內存屏障的函數,它屏蔽了操作系統底層的差異,允許在代碼中定義、并統一由jvm來生成內存屏障指令,來實現內存屏障的功能。Unsafe中提供了下面三個內存屏障相關方法:
//禁止讀操作重排序 public native void loadFence(); //禁止寫操作重排序 public native void storeFence(); //禁止讀、寫操作重排序 public native void fullFence();
內存屏障可以看做對內存隨機訪問的操作中的一個同步點,使得此點之前的所有讀寫操作都執行后才可以開始執行此點之后的操作。以loadFence方法為例,它會禁止讀操作重排序,保證在這個屏障之前的所有讀操作都已經完成,并且將緩存數據設為無效,重新從主存中進行加載。
看到這估計很多小伙伴們會想到volatile關鍵字了,如果在字段上添加了volatile關鍵字,就能夠實現字段在多線程下的可見性。基于讀內存屏障,我們也能實現相同的功能。下面定義一個線程方法,在線程中去修改flag標志位,注意這里的flag是沒有被volatile修飾的:
@Getter class ChangeThread implements Runnable{ /**volatile**/ boolean flag=false; @Override public void run() { try { Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("subThread change flag to:" + flag); flag = true; } }在主線程的while循環中,加入內存屏障,測試是否能夠感知到flag的修改變化:
public static void main(String[] args){ ChangeThread changeThread = new ChangeThread(); new Thread(changeThread).start(); while (true) { boolean flag = changeThread.isFlag(); unsafe.loadFence(); //加入讀內存屏障 if (flag){ System.out.println("detected flag changed"); break; } } System.out.println("main thread end"); }運行結果:
subThread change flag to:false detected flag changed main thread end
而如果刪掉上面代碼中的loadFence方法,那么主線程將無法感知到flag發生的變化,會一直在while中循環。可以用圖來表示上面的過程:
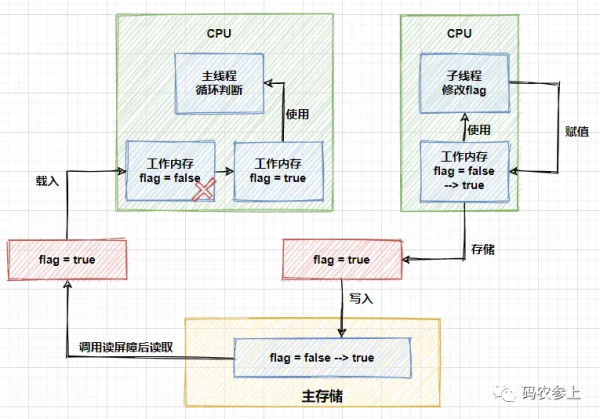
了解java內存模型(JMM)的小伙伴們應該清楚,運行中的線程不是直接讀取主內存中的變量的,只能操作自己工作內存中的變量,然后同步到主內存中,并且線程的工作內存是不能共享的。上面的圖中的流程就是子線程借助于主內存,將修改后的結果同步給了主線程,進而修改主線程中的工作空間,跳出循環。
a、對象成員屬性的內存偏移量獲取,以及字段屬性值的修改,在上面的例子中我們已經測試過了。除了前面的putInt、getInt方法外,Unsafe提供了全部8種基礎數據類型以及Object的put和get方法,并且所有的put方法都可以越過訪問權限,直接修改內存中的數據。閱讀openJDK源碼中的注釋發現,基礎數據類型和Object的讀寫稍有不同,基礎數據類型是直接操作的屬性值(value),而Object的操作則是基于引用值(reference value)。下面是Object的讀寫方法:
//在對象的指定偏移地址獲取一個對象引用 public native Object getObject(Object o, long offset); //在對象指定偏移地址寫入一個對象引用 public native void putObject(Object o, long offset, Object x);
除了對象屬性的普通讀寫外,Unsafe還提供了volatile讀寫和有序寫入方法。volatile讀寫方法的覆蓋范圍與普通讀寫相同,包含了全部基礎數據類型和Object類型,以int類型為例:
//在對象的指定偏移地址處讀取一個int值,支持volatile load語義 public native int getIntVolatile(Object o, long offset); //在對象指定偏移地址處寫入一個int,支持volatile store語義 public native void putIntVolatile(Object o, long offset, int x);
相對于普通讀寫來說,volatile讀寫具有更高的成本,因為它需要保證可見性和有序性。在執行get操作時,會強制從主存中獲取屬性值,在使用put方法設置屬性值時,會強制將值更新到主存中,從而保證這些變更對其他線程是可見的。
有序寫入的方法有以下三個:
public native void putOrderedObject(Object o, long offset, Object x); public native void putOrderedInt(Object o, long offset, int x); public native void putOrderedLong(Object o, long offset, long x);
有序寫入的成本相對volatile較低,因為它只保證寫入時的有序性,而不保證可見性,也就是一個線程寫入的值不能保證其他線程立即可見。為了解決這里的差異性,需要對內存屏障的知識點再進一步進行補充,首先需要了解兩個指令的概念:
Load:將主內存中的數據拷貝到處理器的緩存中
Store:將處理器緩存的數據刷新到主內存中
順序寫入與volatile寫入的差別在于,在順序寫時加入的內存屏障類型為StoreStore類型,而在volatile寫入時加入的內存屏障是StoreLoad類型,如下圖所示:

在有序寫入方法中,使用的是StoreStore屏障,該屏障確保Store1立刻刷新數據到內存,這一操作先于Store2以及后續的存儲指令操作。而在volatile寫入中,使用的是StoreLoad屏障,該屏障確保Store1立刻刷新數據到內存,這一操作先于Load2及后續的裝載指令,并且,StoreLoad屏障會使該屏障之前的所有內存訪問指令,包括存儲指令和訪問指令全部完成之后,才執行該屏障之后的內存訪問指令。
綜上所述,在上面的三類寫入方法中,在寫入效率方面,按照put、putOrder、putVolatile的順序效率逐漸降低,
b、使用Unsafe的allocateInstance方法,允許我們使用非常規的方式進行對象的實例化,首先定義一個實體類,并且在構造函數中對其成員變量進行賦值操作:
@Data public class A { private int b; public A(){ this.b =1; } }分別基于構造函數、反射以及Unsafe方法的不同方式創建對象進行比較:
public void objTest() throws Exception{ A a1=new A(); System.out.println(a1.getB()); A a2 = A.class.newInstance(); System.out.println(a2.getB()); A a3= (A) unsafe.allocateInstance(A.class); System.out.println(a3.getB()); }打印結果分別為1、1、0,說明通過allocateInstance方法創建對象過程中,不會調用類的構造方法。使用這種方式創建對象時,只用到了Class對象,所以說如果想要跳過對象的初始化階段或者跳過構造器的安全檢查,就可以使用這種方法。在上面的例子中,如果將A類的構造函數改為private類型,將無法通過構造函數和反射創建對象,但allocateInstance方法仍然有效。
在Unsafe中,可以使用arrayBaseOffset方法可以獲取數組中第一個元素的偏移地址,使用arrayIndexScale方法可以獲取數組中元素間的偏移地址增量。使用下面的代碼進行測試:
private void arrayTest() { String[] array=new String[]{"str1str1str","str2","str3"}; int baseOffset = unsafe.arrayBaseOffset(String[].class); System.out.println(baseOffset); int scale = unsafe.arrayIndexScale(String[].class); System.out.println(scale); for (int i = 0; i < array.length; i++) { int offset=baseOffset+scale*i; System.out.println(offset+" : "+unsafe.getObject(array,offset)); } }上面代碼的輸出結果為:
16 4 16 : str1str1str 20 : str2 24 : str3
通過配合使用數組偏移首地址和各元素間偏移地址的增量,可以方便的定位到數組中的元素在內存中的位置,進而通過getObject方法直接獲取任意位置的數組元素。需要說明的是,arrayIndexScale獲取的并不是數組中元素占用的大小,而是地址的增量,按照openJDK中的注釋,可以將它翻譯為元素尋址的轉換因子(scale factor for addressing elements)。在上面的例子中,第一個字符串長度為11字節,但其地址增量仍然為4字節。
那么,基于這兩個值是如何實現的尋址和數組元素的訪問呢,這里需要借助一點在前面的文章中講過的Java對象內存布局的知識,先把上面例子中的String數組對象的內存布局畫出來,就很方便大家理解了:
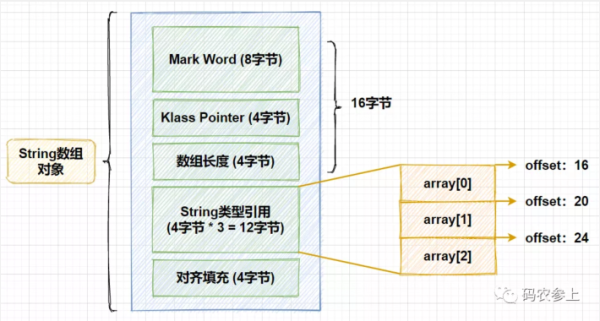
在String數組對象中,對象頭包含3部分,mark word標記字占用8字節,klass point類型指針占用4字節,數組對象特有的數組長度部分占用4字節,總共占用了16字節。第一個String的引用類型相對于對象的首地址的偏移量是就16,之后每個元素在這個基礎上加4,正好對應了我們上面代碼中的尋址過程,之后再使用前面說過的getObject方法,通過數組對象可以獲得對象在堆中的首地址,再配合對象中變量的偏移量,就能獲得每一個變量的引用。
在juc包的并發工具類中大量地使用了CAS操作,像在前面介紹synchronized和AQS的文章中也多次提到了CAS,其作為樂觀鎖在并發工具類中廣泛發揮了作用。在Unsafe類中,提供了compareAndSwapObject、compareAndSwapInt、compareAndSwapLong方法來實現的對Object、int、long類型的CAS操作。以compareAndSwapInt方法為例:
public final native boolean compareAndSwapInt(Object o, long offset,int expected,int x);
參數中o為需要更新的對象,offset是對象o中整形字段的偏移量,如果這個字段的值與expected相同,則將字段的值設為x這個新值,并且此更新是不可被中斷的,也就是一個原子操作。下面是一個使用compareAndSwapInt的例子:
private volatile int a; public static void main(String[] args){ CasTest casTest=new CasTest(); new Thread(()->{ for (int i = 1; i < 5; i++) { casTest.increment(i); System.out.print(casTest.a+" "); } }).start(); new Thread(()->{ for (int i = 5 ; i <10 ; i++) { casTest.increment(i); System.out.print(casTest.a+" "); } }).start(); } private void increment(int x){ while (true){ try { long fieldOffset = unsafe.objectFieldOffset(CasTest.class.getDeclaredField("a")); if (unsafe.compareAndSwapInt(this,fieldOffset,x-1,x)) break; } catch (NoSuchFieldException e) { e.printStackTrace(); } } }運行代碼會依次輸出:
1 2 3 4 5 6 7 8 9
在上面的例子中,使用兩個線程去修改int型屬性a的值,并且只有在a的值等于傳入的參數x減一時,才會將a的值變為x,也就是實現對a的加一的操作。流程如下所示:
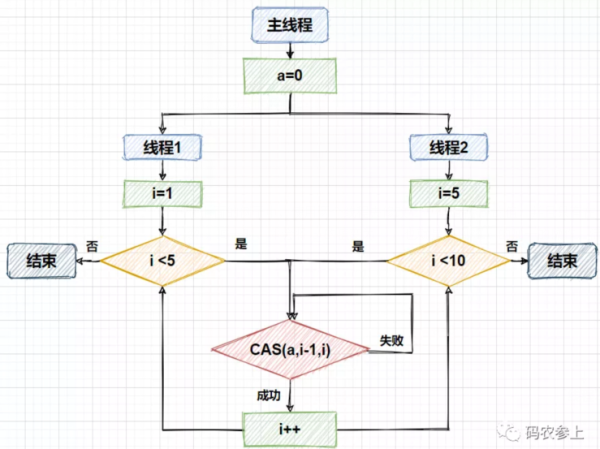
需要注意的是,在調用compareAndSwapInt方法后,會直接返回true或false的修改結果,因此需要我們在代碼中手動添加自旋的邏輯。在AtomicInteger類的設計中,也是采用了將compareAndSwapInt的結果作為循環條件,直至修改成功才退出死循環的方式來實現的原子性的自增操作。
Unsafe類中提供了park、unpark、monitorEnter、monitorExit、tryMonitorEnter方法進行線程調度,在前面介紹AQS的文章中我們提到過使用LockSupport掛起或喚醒指定線程,看一下LockSupport的源碼,可以看到它也是調用的Unsafe類中的方法:
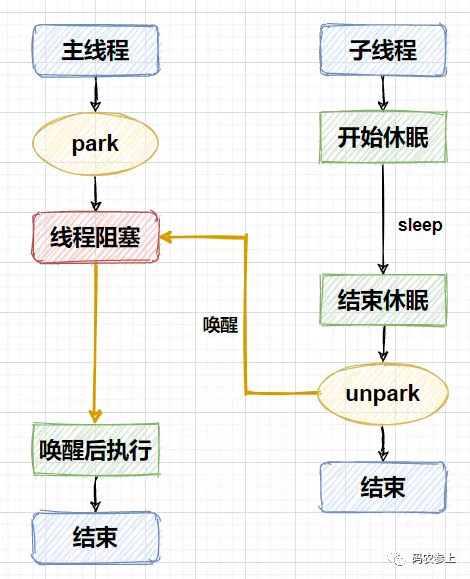
public static void park(Object blocker) { Thread t = Thread.currentThread(); setBlocker(t, blocker); UNSAFE.park(false, 0L); setBlocker(t, null); } public static void unpark(Thread thread) { if (thread != null) UNSAFE.unpark(thread); }LockSupport的park方法調用了Unsafe的park方法來阻塞當前線程,此方法將線程阻塞后就不會繼續往后執行,直到有其他線程調用unpark方法喚醒當前線程。下面的例子對Unsafe的這兩個方法進行測試:
public static void main(String[] args) { Thread mainThread = Thread.currentThread(); new Thread(()->{ try { TimeUnit.SECONDS.sleep(5); System.out.println("subThread try to unpark mainThread"); unsafe.unpark(mainThread); } catch (InterruptedException e) { e.printStackTrace(); } }).start(); System.out.println("park main mainThread"); unsafe.park(false,0L); System.out.println("unpark mainThread success"); }程序輸出為:
park main mainThread subThread try to unpark mainThread unpark mainThread success
程序運行的流程也比較容易看懂,子線程開始運行后先進行睡眠,確保主線程能夠調用park方法阻塞自己,子線程在睡眠5秒后,調用unpark方法喚醒主線程,使主線程能繼續向下執行。整個流程如下圖所示:
此外,Unsafe源碼中monitor相關的三個方法已經被標記為deprecated,不建議被使用:
//獲得對象鎖 @Deprecated public native void monitorEnter(Object var1); //釋放對象鎖 @Deprecated public native void monitorExit(Object var1); //嘗試獲得對象鎖 @Deprecated public native boolean tryMonitorEnter(Object var1);
monitorEnter方法用于獲得對象鎖,monitorExit用于釋放對象鎖,如果對一個沒有被monitorEnter加鎖的對象執行此方法,會拋出IllegalMonitorStateException異常。tryMonitorEnter方法嘗試獲取對象鎖,如果成功則返回true,反之返回false。
Unsafe對Class的相關操作主要包括類加載和靜態變量的操作方法。
a、靜態屬性讀取相關的方法:
//獲取靜態屬性的偏移量 public native long staticFieldOffset(Field f); //獲取靜態屬性的對象指針 public native Object staticFieldBase(Field f); //判斷類是否需要實例化(用于獲取類的靜態屬性前進行檢測) public native boolean shouldBeInitialized(Class<?> c);
創建一個包含靜態屬性的類,進行測試:
@Data public class User { public static String name="Hydra"; int age; } private void staticTest() throws Exception { User user=new User(); System.out.println(unsafe.shouldBeInitialized(User.class)); Field sexField = User.class.getDeclaredField("name"); long fieldOffset = unsafe.staticFieldOffset(sexField); Object fieldBase = unsafe.staticFieldBase(sexField); Object object = unsafe.getObject(fieldBase, fieldOffset); System.out.println(object); }運行結果:
false Hydra
在Unsafe的對象操作中,我們學習了通過objectFieldOffset方法獲取對象屬性偏移量并基于它對變量的值進行存取,但是它不適用于類中的靜態屬性,這時候就需要使用staticFieldOffset方法。在上面的代碼中,只有在獲取Field對象的過程中依賴到了Class,而獲取靜態變量的屬性時不再依賴于Class。
在上面的代碼中首先創建一個User對象,這是因為如果一個類沒有被實例化,那么它的靜態屬性也不會被初始化,最后獲取的字段屬性將是null。所以在獲取靜態屬性前,需要調用shouldBeInitialized方法,判斷在獲取前是否需要初始化這個類。如果刪除創建User對象的語句,運行結果會變為:
true null
b、使用defineClass方法允許程序在運行時動態地創建一個類,方法定義如下:
public native Class<?> defineClass(String name, byte[] b, int off, int len, ClassLoader loader,ProtectionDomain protectionDomain);
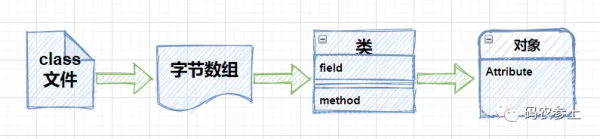
在實際使用過程中,可以只傳入字節數組、起始字節的下標以及讀取的字節長度,默認情況下,類加載器(ClassLoader)和保護域(ProtectionDomain)來源于調用此方法的實例。下面的例子中實現了反編譯生成后的class文件的功能:
private static void defineTest() { String fileName="F:\\workspace\\unsafe-test\\target\\classes\\com\\cn\\model\\User.class"; File file = new File(fileName); try(FileInputStream fis = new FileInputStream(file)) { byte[] content=new byte[(int)file.length()]; fis.read(content); Class clazz = unsafe.defineClass(null, content, 0, content.length, null, null); Object o = clazz.newInstance(); Object age = clazz.getMethod("getAge").invoke(o, null); System.out.println(age); } catch (Exception e) { e.printStackTrace(); } }在上面的代碼中,首先讀取了一個class文件并通過文件流將它轉化為字節數組,之后使用defineClass方法動態的創建了一個類,并在后續完成了它的實例化工作,流程如下圖所示,并且通過這種方式創建的類,會跳過JVM的所有安全檢查。
除了defineClass方法外,Unsafe還提供了一個defineAnonymousClass方法:
public native Class<?> defineAnonymousClass(Class<?> hostClass, byte[] data, Object[] cpPatches);
使用該方法可以用來動態的創建一個匿名類,在Lambda表達式中就是使用ASM動態生成字節碼,然后利用該方法定義實現相應的函數式接口的匿名類。在jdk15發布的新特性中,在隱藏類(Hidden classes)一條中,指出將在未來的版本中棄用Unsafe的defineAnonymousClass方法。
Unsafe中提供的addressSize和pageSize方法用于獲取系統信息,調用addressSize方法會返回系統指針的大小,如果在64位系統下默認會返回8,而32位系統則會返回4。調用pageSize方法會返回內存頁的大小,值為2的整數冪。使用下面的代碼可以直接進行打印:
private void systemTest() { System.out.println(unsafe.addressSize()); System.out.println(unsafe.pageSize()); }執行結果:
8 4096
這兩個方法的應用場景比較少,在java.nio.Bits類中,在使用pageCount計算所需的內存頁的數量時,調用了pageSize方法獲取內存頁的大小。另外,在使用copySwapMemory方法拷貝內存時,調用了addressSize方法,檢測32位系統的情況。
感謝各位的閱讀,以上就是“如何使用Unsafe類”的內容了,經過本文的學習后,相信大家對如何使用Unsafe類這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





