溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹如何使用pandas中DataFrame檢測重復值,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
本文詳解如何使用pandas查看dataframe的重復數據,判斷是否重復,以及如何去重
DataFrame.duplicated(subset=None, keep='first')
subset:如果你認為幾個字段重復,則數據重復,就把那幾個字段以列表形式放到subset后面。默認是所有字段重復為重復數據。
keep:
默認為'first' ,也就是如果有重復數據,則第一條出現的定義為False,后面的重復數據為True。
如果為'last',也就是如果有重復數據,則最后一條出現的定義為False,后面的重復數據為True。
如果為False,則所有重復的為True
下面舉例
df = pd.DataFrame({
'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'],
'style': ['cup', 'cup', 'cup', 'pack', 'pack'],
'rating': [4, 4, 3.5, 15, 5]
})
df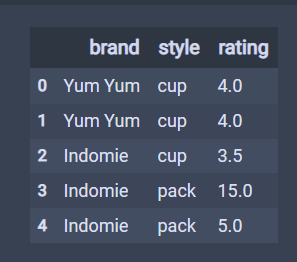
# 默認為keep="first",第一條重復的為False,后面重復的為True # 一般不會設置keep,保持keep為默認值。 df.duplicated() 結果 0 False 1 True 2 False 3 False 4 False dtype: bool # keep="last",,最后一條重復的為False,后面重復的為True df.duplicated(keep="last") 結果 0 True 1 False 2 False 3 False 4 False dtype: bool # keep=False,,所有重復的為True df.duplicated(keep=False) 結果 0 True 1 True 2 False 3 False 4 False dtype: bool # sub是子,subset是子集 # 標記只要brand重復為重復值。 df.duplicated(subset='brand') 結果 0 False 1 True 2 False 3 True 4 True dtype: bool # 只要brand重復brand和style重復的為重復值。 df.duplicated(subset=['brand','style']) 結果 0 False 1 True 2 False 3 False 4 True dtype: bool # 顯示重復記錄,通過布爾索引 df[df.duplicated()]
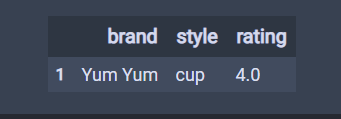
# 查詢重復值的個數。 df.duplicated().sum() 結果 1
以上是“如何使用pandas中DataFrame檢測重復值”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





