溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關使用Python怎么實現自動提取并收集信息,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
1.導入需要的庫,包括百度的api接口跟cv2圖像截圖圖庫
import cv2
from aip import AipOcr
# 讀取圖片,利用imshow顯示圖片
pic = cv2.imread(r'Y:\cut\img1.png')
pic = cv2.resize(pic,None,fx = 0.5, fy = 0.5)
cv2.imshow('img',pic)
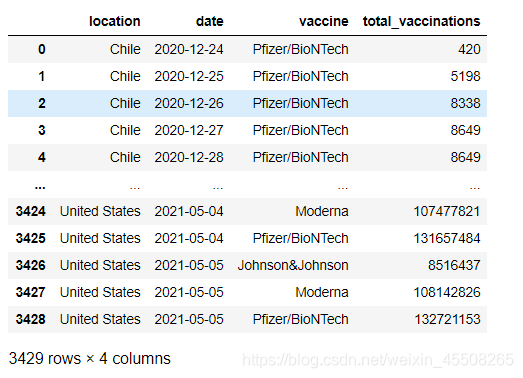
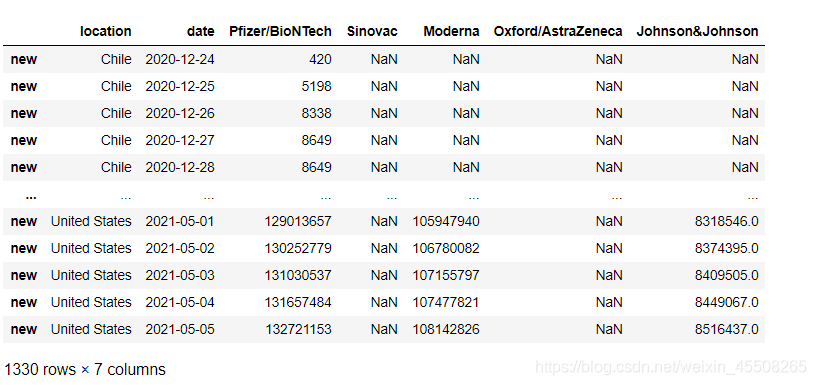
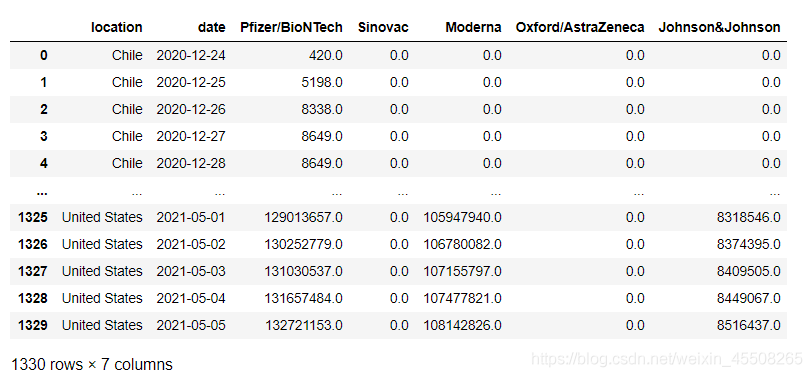
cv2.waitKey(0)2.截取圖片,獲取需要的信息,包括以下信息
時間Time
商家business
商品goods
價格money
單號num
# 刪除不必要的部分
img = pic[210:500, 100:580]
# 截取各部分的文字
time = pic[400:430, 100:580]
business = pic[370:400, 100:580]
goods = pic[350:380, 100:580]
money = pic[210:300, 100:580]
num = pic[460:500, 100:580]
# 查看截取的部分是否合適
gener_name = ['time','business','goods','money','num']
excel_data = {}
pd_columns = ["a","b","c","d","e"] # 標題
3.定義函數將截取好的圖片另存到文件夾
def shotcut_image(args):
for index in gener:
cv2.imwrite('image/{}.png'.format(args), img)4.調用百度api接口,實現文字識別
# 導入api
AppID = '24177719'
API_Key = 'p8skmRYfHGoVGR4UU03Q5jiM'
Secret_Key = 'dyM0tzSILBZu9CFqZ7IkjWwECGaws4xo'
cilent = AipOcr(AppID,API_Key,Secret_Key)
def get_words(img_name):
with open('image/{}.png'.format(img_name), 'rb') as f:
result = cilent.basicAccurate(f.read())
return result5.最后將信息轉為Dataframe,利用pandas的to_exccel功能,將數據放到excel里面
def convert_to_dataframe(words):
# 構建dataframe
result = words['words_result']
for word in result:
excel_data.setdefault('a', []).append(word['words'])
# 將所有words讀取后,取出語句存入excel
def convert_to_excel():
frame = DataFrame(excel_data, columns=pd_columns)
# todo 表頭需要額外處理,這里指定不設置表頭
frame.to_excel('out.xls',index=False, header=False)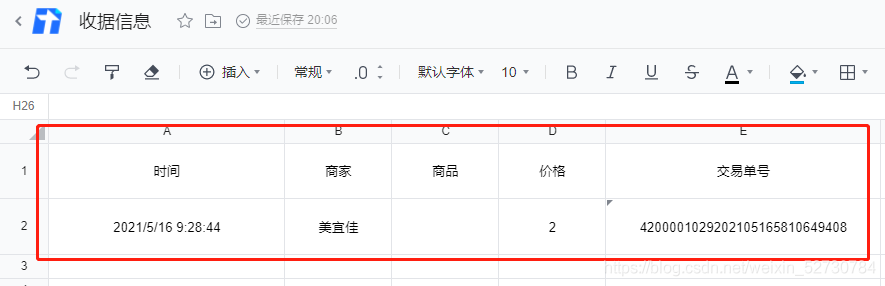
Python主要應用于:1、Web開發;2、數據科學研究;3、網絡爬蟲;4、嵌入式應用開發;5、游戲開發;6、桌面應用開發。
以上就是使用Python怎么實現自動提取并收集信息,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





