溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關如何在Python中使用SKlearn包,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
Sklearn(全稱 SciKit-Learn),是基于 Python 語言的機器學習工具包。
Sklearn 主要用Python編寫,建立在 Numpy、Scipy、Pandas 和 Matplotlib 的基礎上,也用 Cython編寫了一些核心算法來提高性能。
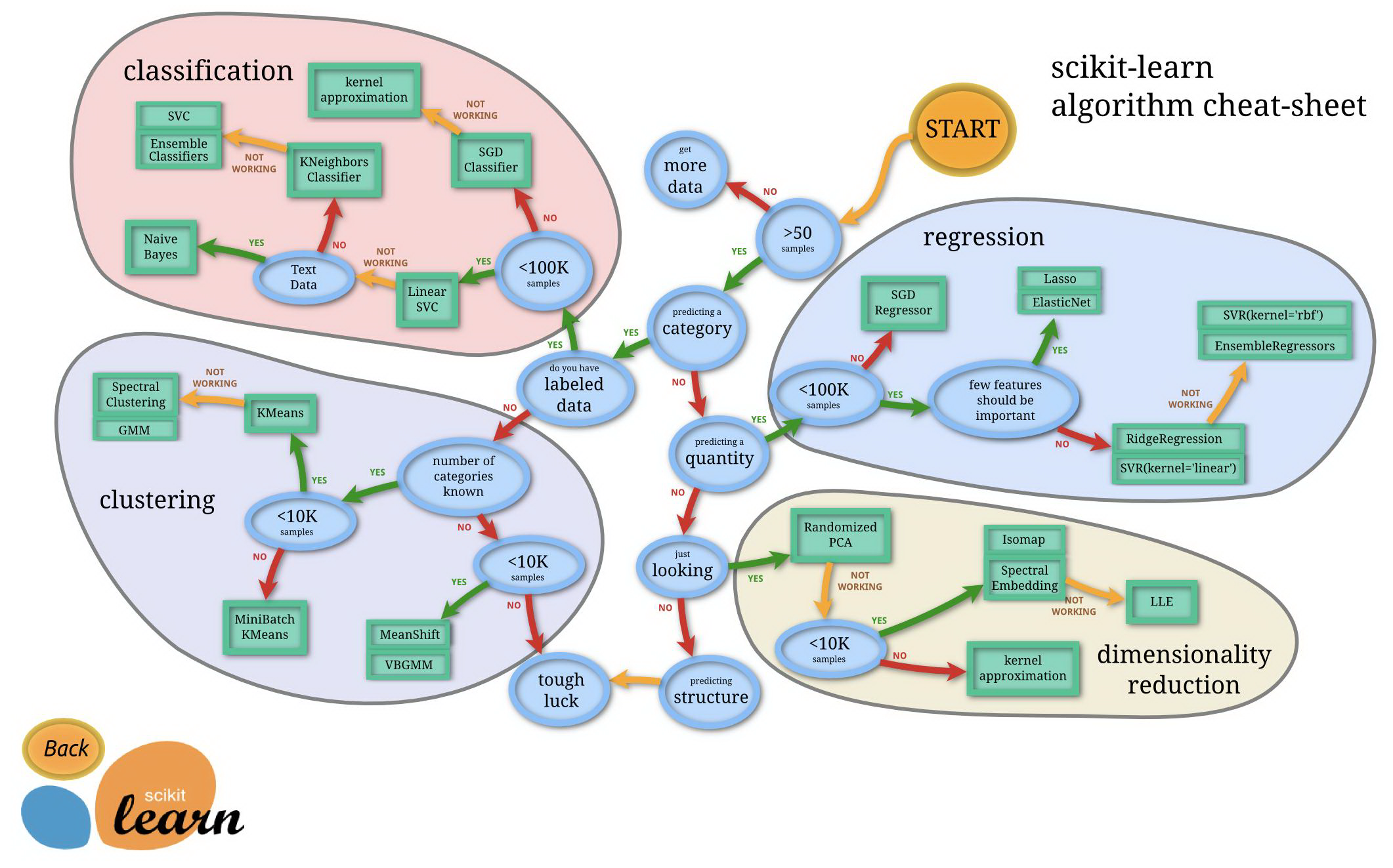
Sklearn 包括六大功能模塊:
分類(Classification):識別樣本屬于哪個類別,常用算法有 SVM(支持向量機)、nearest neighbors(最近鄰)、random forest(隨機森林)
回歸(Regression):預測與對象相關聯的連續值屬性,常用算法有 SVR(支持向量機)、 ridge regression(嶺回歸)、Lasso
聚類(Clustering):對樣本進行無監督的自動分類,常用算法有 k-Means(k均值)、spectral clustering(特征聚類)、mean-shift(均值漂移)
數據降維(Dimensionality reduction):減少相關變量維數,常用算法有 PCA(主成分分析)、feature selection(特征選擇)、non-negative matrix factorization(非負矩陣分解)
模型選擇(Model Selection):比較,驗證,選擇參數和模型,常用模塊有 grid search(網格搜索)、cross validation(交叉驗證)、 metrics(度量)
數據處理 (Preprocessing):特征提取和歸一化,常用模塊有 preprocessing(預處理),feature extraction(特征提取)
這六個功能模塊涉及 4類算法,分類、回歸 屬于監督學習,聚類屬于非監督學習。

2、SKlearn 的安裝
Sklearn 的安裝要求:Python 3.5 以上版本,需要安裝 NumPy、SciPy、Pandas 工具包的支持,部分內容需要使用 Matplotlib、joblib 工具包。
pip 安裝命令:
pip3 install -U scikit-learn
pip3 install -U scikit-learn -i https://pypi.douban.com/simple
注意 Sklearn 建議安裝 Numpy+mkl,可以在網址http://www.lfd.uci.edu/~gohlke/pythonlibs/ 找到你需要的numpy+mkl版本,下載后 pip3安裝:
pip install numpy-1.11.1+mkl-cp27-cp27m-win_amd64.whl
Sklearn 內置了一些標準數據集可以用于練習和測試,都是經常被引用的經典問題,數據網址:https://scikit-learn.org/stable/datasets.html
Sklearn 標準數據集主要包括:
波士頓房價:Boston house prices dataset
鳶尾花問題:Iris plants dataset
糖尿病數據:Diabetes dataset
手寫數字的識別:Optical recognition of handwritten digits dataset
體能訓練:Linnerrud dataset
葡萄酒鑒別:Wine recognition dataset
威斯康星州癌癥診斷:reast cancer wisconsin (diagnostic) dataset
人臉數據:The Olivetti faces dataset
20個新聞文本數據:The 20 newsgroups text dataset
標記的人臉數據:The Labeled Faces in the Wild face recognition dataset
森林覆蓋類型:Forest covertypes
路透社新聞數據:RCV1 dataset
網絡入侵檢測數據:Kddcup 99 dataset
加州住房數據:California Housing dataset
粗略看看 Sklearn 的文檔,是一個功能強大和豐富的機器學習庫,遠遠超出了數學建模學習的范圍。
基于數模教學的目的,本系列主要對應數模學習中的分類、聚類、降維問題,并不打算全面講解 Sklearn 的各種算法,而是以典型問題為例來介紹原理簡單、使用廣泛的基本方法,以便新手入門。
python的數據類型:1. 數字類型,包括int(整型)、long(長整型)和float(浮點型)。2.字符串,分別是str類型和unicode類型。3.布爾型,Python布爾類型也是用于邏輯運算,有兩個值:True(真)和False(假)。4.列表,列表是Python中使用最頻繁的數據類型,集合中可以放任何數據類型。5. 元組,元組用”()”標識,內部元素用逗號隔開。6. 字典,字典是一種鍵值對的集合。7. 集合,集合是一個無序的、不重復的數據組合。
以上就是如何在Python中使用SKlearn包,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





