溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何在Python項目中使用Sklearn?相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
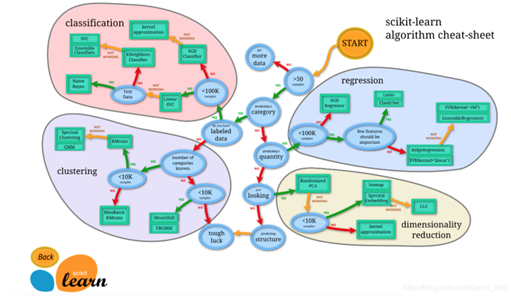
Scikit-learn(sklearn)是機器學習中常用的第三方模塊,對常用的機器學習方法進行了封裝,包括回歸(Regression)、降維(Dimensionality Reduction)、分類(Classfication)、聚類(Clustering)等方法。當我們面臨機器學習問題時,便可根據下圖來選擇相應的方法。Sklearn具有以下特點:
簡單高效的數據挖掘和數據分析工具
讓每個人能夠在復雜環境中重復使用
建立NumPy、Scipy、MatPlotLib之上
Sklearn安裝要求Python(>=2.7 or >=3.3)、NumPy (>= 1.8.2)、SciPy (>= 0.13.3)。如果已經安裝NumPy和SciPy,安裝scikit-learn可以使用pip install -U scikit-learn。
Sklearn中包含眾多機器學習方法,但各種學習方法大致相同,我們在這里介紹Sklearn通用學習模式。首先引入需要訓練的數據,Sklearn自帶部分數據集,也可以通過相應方法進行構造,4.Sklearn datasets中我們會介紹如何構造數據。然后選擇相應機器學習方法進行訓練,訓練過程中可以通過一些技巧調整參數,使得學習準確率更高。模型訓練完成之后便可預測新數據,然后我們還可以通過MatPlotLib等方法來直觀的展示數據。另外還可以將我們已訓練好的Model進行保存,方便移動到其他平臺,不必重新訓練。
from sklearn import datasets#引入數據集,sklearn包含眾多數據集 from sklearn.model_selection import train_test_split#將數據分為測試集和訓練集 from sklearn.neighbors import KNeighborsClassifier#利用鄰近點方式訓練數據 ###引入數據### iris=datasets.load_iris()#引入iris鳶尾花數據,iris數據包含4個特征變量 iris_X=iris.data#特征變量 iris_y=iris.target#目標值 X_train,X_test,y_train,y_test=train_test_split(iris_X,iris_y,test_size=0.3)#利用train_test_split進行將訓練集和測試集進行分開,test_size占30% print(y_train)#我們看到訓練數據的特征值分為3類 ''' [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2] ''' ###訓練數據### knn=KNeighborsClassifier()#引入訓練方法 knn.fit(X_train,y_train)#進行填充測試數據進行訓練 ###預測數據### print(knn.predict(X_test))#預測特征值 ''' [1 1 1 0 2 2 1 1 1 0 0 0 2 2 0 1 2 2 0 1 0 0 0 0 0 0 2 1 0 0 0 1 0 2 0 2 0 1 2 1 0 0 1 0 2] ''' print(y_test)#真實特征值 ''' [1 1 1 0 1 2 1 1 1 0 0 0 2 2 0 1 2 2 0 1 0 0 0 0 0 0 2 1 0 0 0 1 0 2 0 2 0 1 2 1 0 0 1 0 2] '''
Sklearn提供一些標準數據,我們不必再從其他網站尋找數據進行訓練。例如我們上面用來訓練的load_iris數據,可以很方便的返回數據特征變量和目標值。除了引入數據之外,我們還可以通過load_sample_images()來引入圖片。

除了sklearn提供的一些數據之外,還可以自己來構造一些數據幫助我們學習。
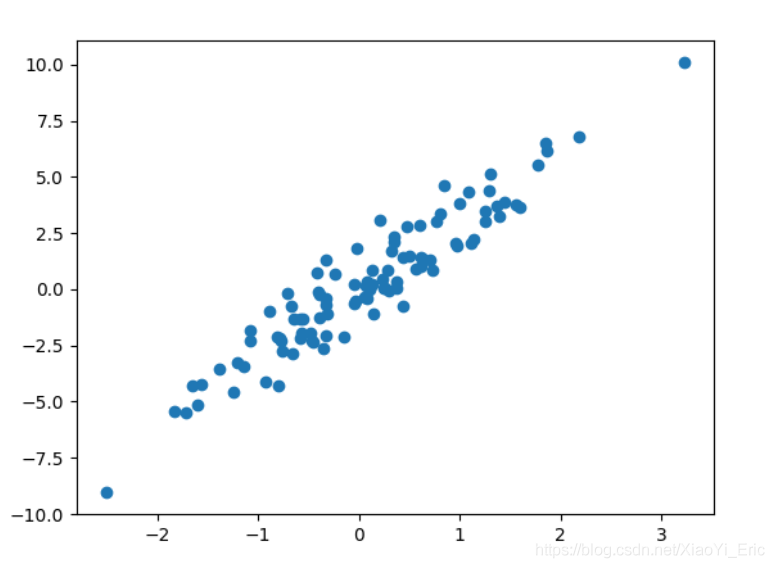
from sklearn import datasets#引入數據集 #構造的各種參數可以根據自己需要調整 X,y=datasets.make_regression(n_samples=100,n_features=1,n_targets=1,noise=1) ###繪制構造的數據### import matplotlib.pyplot as plt plt.figure() plt.scatter(X,y) plt.show()
數據訓練完成之后得到模型,我們可以根據不同模型得到相應的屬性和功能,并將其輸出得到直觀結果。假如通過線性回歸訓練之后得到線性函數y=0.3x+1,我們可通過_coef得到模型的系數為0.3,通過_intercept得到模型的截距為1。
from sklearn import datasets
from sklearn.linear_model import LinearRegression#引入線性回歸模型
###引入數據###
load_data=datasets.load_boston()
data_X=load_data.data
data_y=load_data.target
print(data_X.shape)
#(506, 13)data_X共13個特征變量
###訓練數據###
model=LinearRegression()
model.fit(data_X,data_y)
model.predict(data_X[:4,:])#預測前4個數據
###屬性和功能###
print(model.coef_)
'''
[ -1.07170557e-01 4.63952195e-02 2.08602395e-02 2.68856140e+00
-1.77957587e+01 3.80475246e+00 7.51061703e-04 -1.47575880e+00
3.05655038e-01 -1.23293463e-02 -9.53463555e-01 9.39251272e-03
-5.25466633e-01]
'''
print(model.intercept_)
#36.4911032804
print(model.get_params())#得到模型的參數
#{'copy_X': True, 'normalize': False, 'n_jobs': 1, 'fit_intercept': True}
print(model.score(data_X,data_y))#對訓練情況進行打分
#0.740607742865數據集的標準化對于大部分機器學習算法來說都是一種常規要求,如果單個特征沒有或多或少地接近于標準正態分布,那么它可能并不能在項目中表現出很好的性能。在實際情況中,我們經常忽略特征的分布形狀,直接去均值來對某個特征進行中心化,再通過除以非常量特征(non-constant features)的標準差進行縮放。
例如, 許多學習算法中目標函數的基礎都是假設所有的特征都是零均值并且具有同一階數上的方差(比如徑向基函數、支持向量機以及L1L2正則化項等)。如果某個特征的方差比其他特征大幾個數量級,那么它就會在學習算法中占據主導位置,導致學習器并不能像我們說期望的那樣,從其他特征中學習。例如我們可以通過Scale將數據縮放,達到標準化的目的。
from sklearn import preprocessing import numpy as np a=np.array([[10,2.7,3.6], [-100,5,-2], [120,20,40]],dtype=np.float64) print(a) print(preprocessing.scale(a))#將值的相差度減小 ''' [[ 10. 2.7 3.6] [-100. 5. -2. ] [ 120. 20. 40 [[ 0. -0.85170713 -0.55138018] [-1.22474487 -0.55187146 -0.852133 ] [ 1.22474487 1.40357859 1.40351318]] '''
我們來看下預處理前和預處理預處理后的差別,預處理之前模型評分為0.511111111111,預處理后模型評分為0.933333333333,可以看到預處理對模型評分有很大程度的提升。
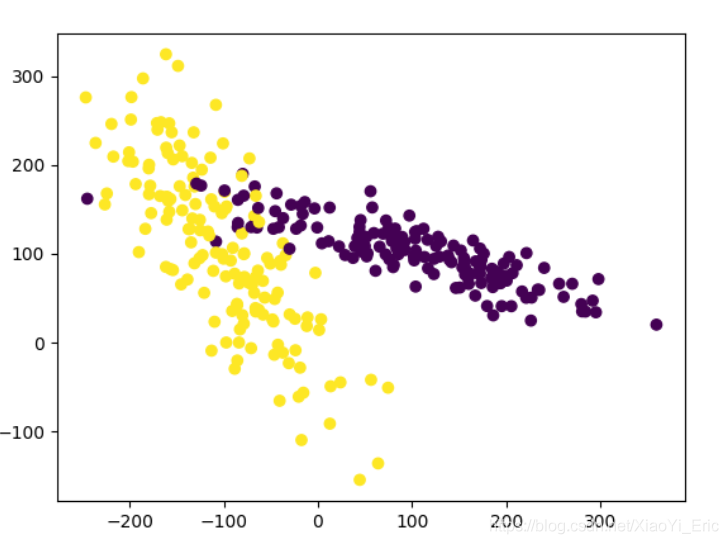
from sklearn.model_selection import train_test_split from sklearn.datasets.samples_generator import make_classification from sklearn.svm import SVC import matplotlib.pyplot as plt ###生成的數據如下圖所示### plt.figure X,y=make_classification(n_samples=300,n_features=2,n_redundant=0,n_informative=2, random_state=22,n_clusters_per_class=1,scale=100) plt.scatter(X[:,0],X[:,1],c=y) plt.show() ###利用minmax方式對數據進行規范化### X=preprocessing.minmax_scale(X)#feature_range=(-1,1)可設置重置范圍 X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3) clf=SVC() clf.fit(X_train,y_train) print(clf.score(X_test,y_test)) #0.933333333333 #沒有規范化之前我們的訓練分數為0.511111111111,規范化后為0.933333333333,準確度有很大提升
交叉驗證的基本思想是將原始數據進行分組,一部分做為訓練集來訓練模型,另一部分做為測試集來評價模型。交叉驗證用于評估模型的預測性能,尤其是訓練好的模型在新數據上的表現,可以在一定程度上減小過擬合。還可以從有限的數據中獲取盡可能多的有效信息。
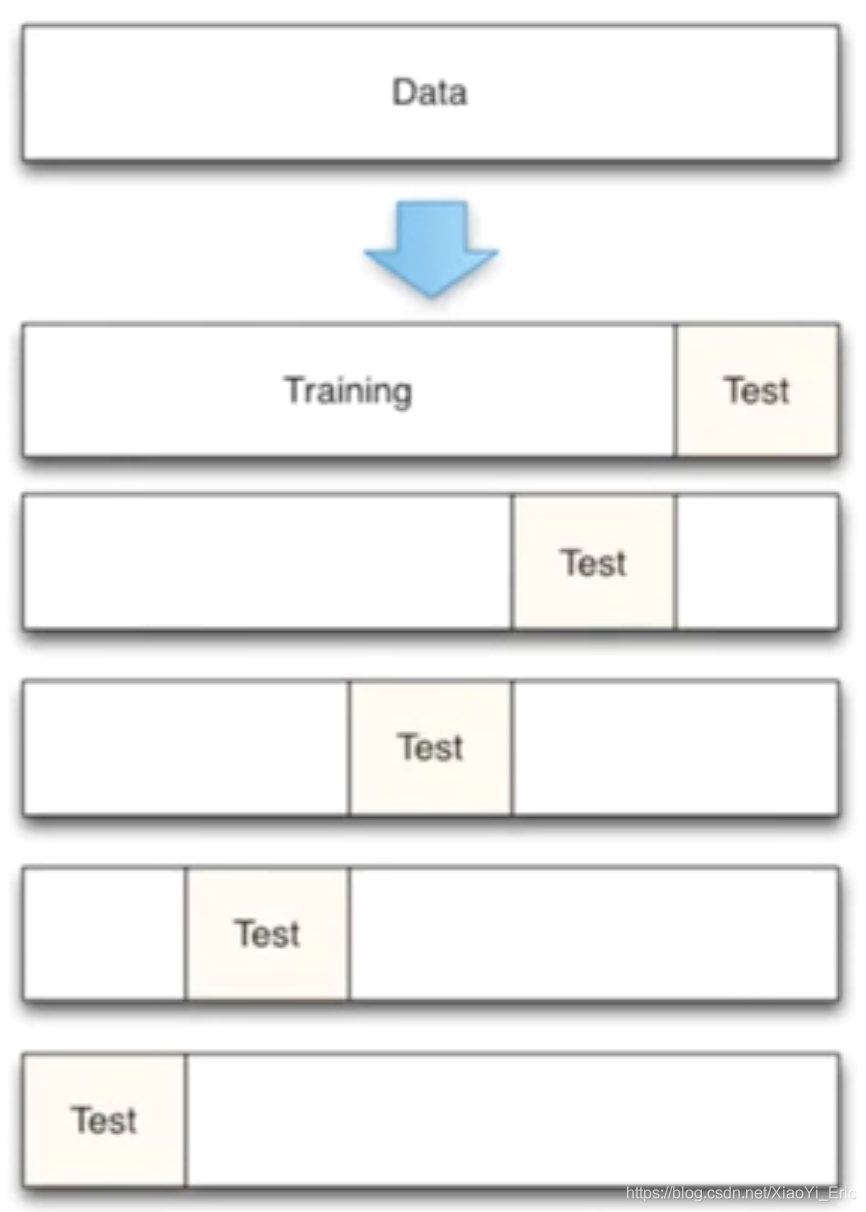
機器學習任務中,拿到數據后,我們首先會將原始數據集分為三部分:訓練集、驗證集和測試集。 訓練集用于訓練模型,驗證集用于模型的參數選擇配置,測試集對于模型來說是未知數據,用于評估模型的泛化能力。不同的劃分會得到不同的最終模型。
以前我們是直接將數據分割成70%的訓練數據和測試數據,現在我們利用K折交叉驗證分割數據,首先將數據分為5組,然后再從5組數據之中選擇不同數據進行訓練。
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier ###引入數據### iris=load_iris() X=iris.data y=iris.target ###訓練數據### X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3) #引入交叉驗證,數據分為5組進行訓練 from sklearn.model_selection import cross_val_score knn=KNeighborsClassifier(n_neighbors=5)#選擇鄰近的5個點 scores=cross_val_score(knn,X,y,cv=5,scoring='accuracy')#評分方式為accuracy print(scores)#每組的評分結果 #[ 0.96666667 1. 0.93333333 0.96666667 1. ]5組數據 print(scores.mean())#平均評分結果 #0.973333333333
那么是否n_neighbor=5便是最好呢,我們來調整參數來看模型最終訓練分數。
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score#引入交叉驗證
import matplotlib.pyplot as plt
###引入數據###
iris=datasets.load_iris()
X=iris.data
y=iris.target
###設置n_neighbors的值為1到30,通過繪圖來看訓練分數###
k_range=range(1,31)
k_score=[]
for k in k_range:
knn=KNeighborsClassifier(n_neighbors=k)
scores=cross_val_score(knn,X,y,cv=10,scoring='accuracy')#for classfication
k_score.append(scores.mean())
plt.figure()
plt.plot(k_range,k_score)
plt.xlabel('Value of k for KNN')
plt.ylabel('CrossValidation accuracy')
plt.show()
#K過大會帶來過擬合問題,我們可以選擇12-18之間的值我們可以看到n_neighbor在12-18之間評分比較高,實際項目之中我們可以通過這種方式來選擇不同參數。另外我們還可以選擇2-fold Cross Validation,Leave-One-Out Cross Validation等方法來分割數據,比較不同方法和參數得到最優結果。
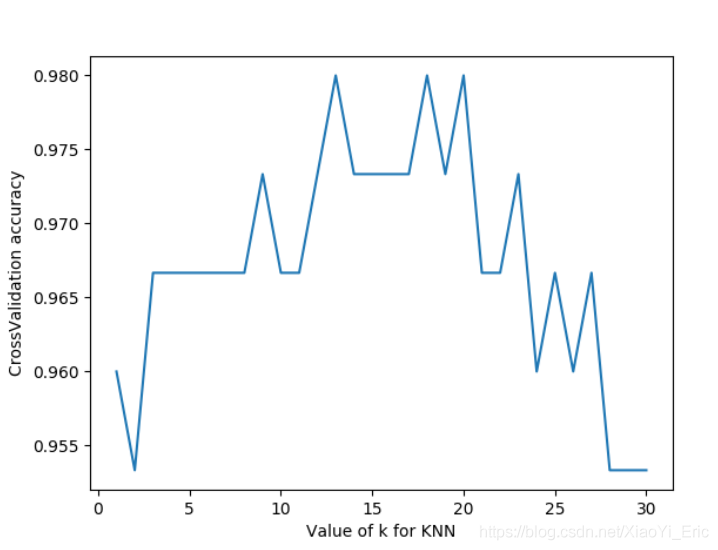
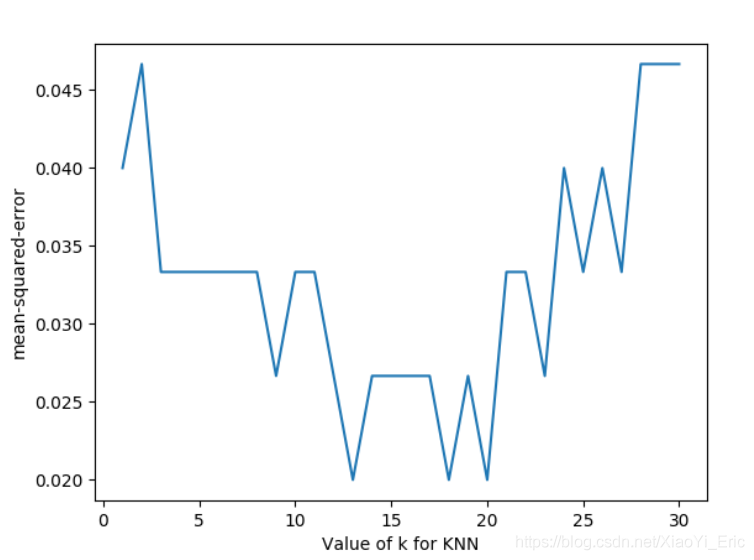
我們將上述代碼中的循環部分改變一下,評分函數改為neg_mean_squared_error,便得到對于不同參數時的損失函數。
for k in k_range: knn=KNeighborsClassifier(n_neighbors=k) loss=-cross_val_score(knn,X,y,cv=10,scoring='neg_mean_squared_error')# for regression k_score.append(loss.mean())
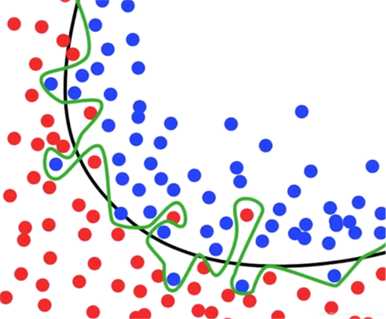
什么是過擬合問題呢?例如下面這張圖片,黑色線已經可以很好的分類出紅色點和藍色點,但是在機器學習過程中,模型過于糾結準確度,便形成了綠色線的結果。然后在預測測試數據集結果的過程中往往會浪費很多時間并且準確率不是太好。
我們先舉例如何辨別overfitting問題。Sklearn.learning_curve中的learning curve可以很直觀的看出Model學習的進度,對比發現有沒有過擬合。
from sklearn.model_selection import learning_curve
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
#引入數據
digits=load_digits()
X=digits.data
y=digits.target
#train_size表示記錄學習過程中的某一步,比如在10%,25%...的過程中記錄一下
train_size,train_loss,test_loss=learning_curve(
SVC(gamma=0.1),X,y,cv=10,scoring='neg_mean_squared_error',
train_sizes=[0.1,0.25,0.5,0.75,1]
)
train_loss_mean=-np.mean(train_loss,axis=1)
test_loss_mean=-np.mean(test_loss,axis=1)
plt.figure()
#將每一步進行打印出來
plt.plot(train_size,train_loss_mean,'o-',color='r',label='Training')
plt.plot(train_size,test_loss_mean,'o-',color='g',label='Cross-validation')
plt.legend('best')
plt.show()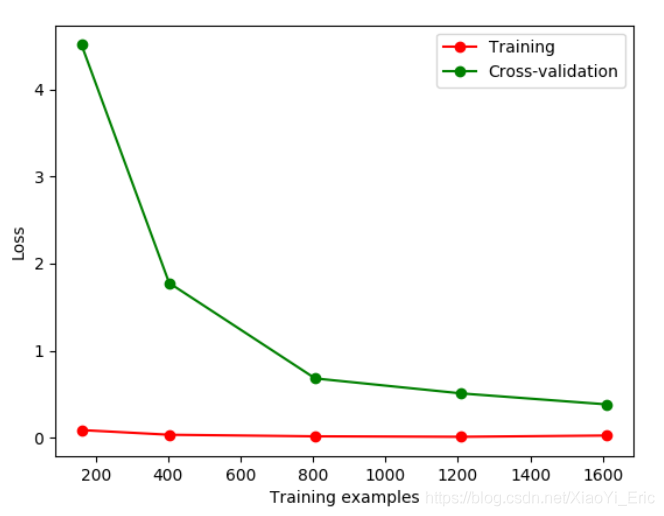
如果我們改變gamma的值,那么會改變相應的Loss函數。損失函數便在10左右停留,此時便能直觀的看出過擬合。
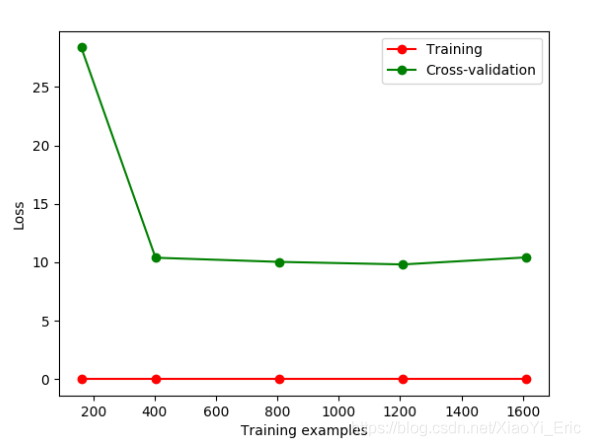
下面我們通過修改gamma參數來修正過擬合問題。
from sklearn.model_selection import validation_curve#將learning_curve改為validation_curve
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
#引入數據
digits=load_digits()
X=digits.data
y=digits.target
#改變param來觀察Loss函數情況
param_range=np.logspace(-6,-2.3,5)
train_loss,test_loss=validation_curve(
SVC(),X,y,param_name='gamma',param_range=param_range,cv=10,
scoring='neg_mean_squared_error'
)
train_loss_mean=-np.mean(train_loss,axis=1)
test_loss_mean=-np.mean(test_loss,axis=1)
plt.figure()
plt.plot(param_range,train_loss_mean,'o-',color='r',label='Training')
plt.plot(param_range,test_loss_mean,'o-',color='g',label='Cross-validation')
plt.xlabel('gamma')
plt.ylabel('loss')
plt.legend(loc='best')
plt.show()通過改變不同的gamma值我們可以看到Loss函數的變化情況。從圖中可以看到,如果gamma的值大于0.001便會出現過擬合的問題,那么我們構建模型時gamma參數設置應該小于0.001。
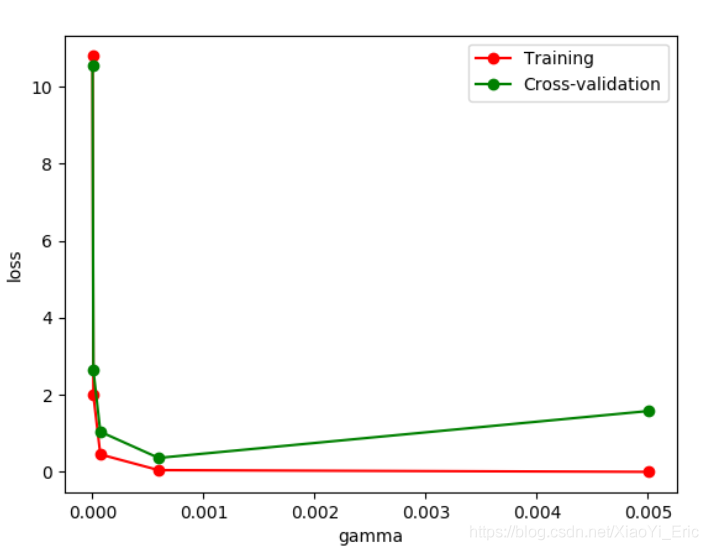
我們花費很長時間用來訓練數據,調整參數,得到最優模型。但如果改變平臺,我們還需要重新訓練數據和修正參數來得到模型,將會非常的浪費時間。此時我們可以先將model保存起來,然后便可以很方便的將模型遷移。
from sklearn import svm
from sklearn import datasets
#引入和訓練數據
iris=datasets.load_iris()
X,y=iris.data,iris.target
clf=svm.SVC()
clf.fit(X,y)
#引入sklearn中自帶的保存模塊
from sklearn.externals import joblib
#保存model
joblib.dump(clf,'sklearn_save/clf.pkl')
#重新加載model,只有保存一次后才能加載model
clf3=joblib.load('sklearn_save/clf.pkl')
print(clf3.predict(X[0:1]))
#存放model能夠更快的獲得以前的結果看完上述內容,你們掌握如何在Python項目中使用Sklearn的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





