溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下pytorch如何實現多個反向傳播操作,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
從一個錯誤說起:
RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed
在深度學習中,有些場景需要進行兩次反向,比如Gan網絡,需要對D進行一次,還要對G進行一次,很多人都會遇到上面這個錯誤,這個錯誤的意思就是嘗試對一個計算圖進行第二次反向,但是計算圖已經釋放了。
其實看簡單點和我們之前的backward一樣,當圖進行了一次梯度更新,就會把一些梯度的緩存給清空,為了避免下次疊加,但在Gan這種情形下,我們必須要二次更新,那怎么辦呢。
這是網上大多數給出的解決方案,在第一次反向時候加入一個l2.backward(),這樣就能避免釋放掉了。
上面的方案雖然解決了問題,但是并不優美,因為我們用Gan的時候,D和G兩者的更新并無聯系,二者的聯系僅僅是D里面用到了G的輸出,而這個輸出一般我們都是直接拿來用的,而問題就出現在這里。
下面給一個模擬:
data = torch.randn(4,10) model1 = torch.nn.Linear(10,2) model2 = torch.nn.Linear(2,2) optimizer1 = torch.optim.Adam(model1.parameters(), lr=0.001,betas=(0.5, 0.999)) optimizer2 = torch.optim.Adam(model2.parameters(), lr=0.001,betas=(0.5, 0.999)) loss = torch.nn.CrossEntropyLoss() data = torch.randn(4,10) label = torch.Tensor([0,1,1,0]).long() for i in range(20): a = model1(data) b = model2(a) l1 = loss(a,label) l2 = loss(b,label) optimizer2.zero_grad() l2.backward() optimizer2.step() optimizer1.zero_grad() l1.backward() optimizer1.step()
上面定義了兩個模型,而model2的輸入是model1的輸出,而更新的時候,二者都是各自更新自己的參數,并無聯系,但是上面的代碼會報一個RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed 這樣的錯,解決方案可以是l2.backward(retain_graph=True)。
除此之外我們還可以是b = model2(a.detach()),這個就優美一點,a.detach()和a的區別你可以打印出來看一下,其實a.detach()是沒有梯度的,所以相當于一個單純的數字,和model1就脫離了聯系,這樣model2和model1就是完全分離開來的兩個圖,但是如果用的是a則model2和model1則仍然公用一個圖,所以導致了錯誤。
可以看下面示意圖(這個是我猜測,幫助理解):
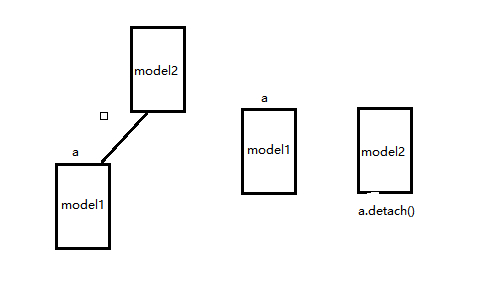
左邊相當于直接用a而右邊則用a.detach(),類似的在Gan網絡里面D的輸入可以改為G的輸出y_fake.detach()。
但有一點需要注意的是,兩個網絡一定沒有需要共同更新的 ,假如上面的optimizer2 = torch.optim.Adam(itertools.chain(model1.parameters(),model2.parameters()), lr=0.001,betas=(0.5, 0.999)),則還是用retain_graph=True保險,因為.detach則model2反向不會傳播到model1,導致不對model1里面參數更新。
補充:聊聊Focal Loss及其反向傳播
我們都知道,當前的目標檢測(Objece Detection)算法主要分為兩大類:two-stage detector和one-stage detector。two-stage detector主要包括rcnn、fast-rcnn、faster-rcnn和rfcn等,one-stage detector主要包括yolo和ssd等,前者精度高但檢測速度較慢,后者精度低些但速度很快。
對于two-stage detector而言,通常先由RPN生成proposals,再由RCNN對proposals進行Classifcation和Bounding Box Regression。這樣做的一個好處是有利于樣本和模型之間的feature alignment,從而使Classification和Bounding Box Regression更容易些;此外,RPN和RCNN中存在正負樣本不均衡的問題,RPN直接限制正負樣本的比例為1:1,對于固定的rpn_batch_size,正樣本不足的情況下才用負樣本來填充,RCNN則是直接限制了正負樣本的比例為1:3或者采用OHEM。
對于one-stage detector而言,樣本和模型之間的feature alignment只能通過reception field來實現,且直接通過回歸方式進行預測,存在這嚴重的正負樣本數據不均衡(1:1000)的問題,負樣本的比例過高,占據了loss的絕大部分,且大多數是容易分類的,這使得模型的訓練朝著不希望的方向前進。作者認為這種數據的嚴重不均衡是造成one-stage detector精度低的主要原因,因此提出Focal Loss來解決這一問題。
通過人工控制正負樣本比例或者OHEM能夠一定程度解決數據不均衡問題,但這兩種方法都比較粗暴,采用這種“一刀切”的方式有可能把一些hard examples忽略掉。因此,作者提出了一種新的損失函數Focal Loss,不忽略任何樣本,同時又能讓模型訓練時更加專注在hard examples上。簡單說明下Focal loss的原理。
Focal Loss是在標準的交叉熵損失的基礎上改進而來。以二分類為例,標準的交叉熵損失函數為

針對類別不均衡,針對對不同類別對loss的貢獻進行控制即可,也就是加一個控制權重αt,那么改進后的balanced cross entropy loss為
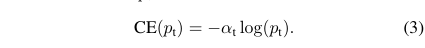
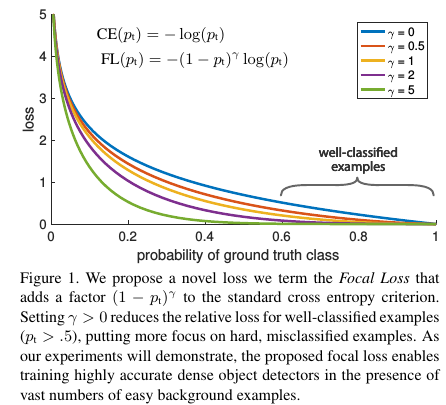
但是balanced cross entropy loss沒辦法讓訓練時專注在hard examples上。實際上,樣本的正確分類概率pt越大,那么往往說明這個樣本越易分。所以,最終的Focal Loss為
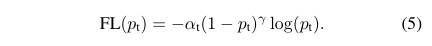
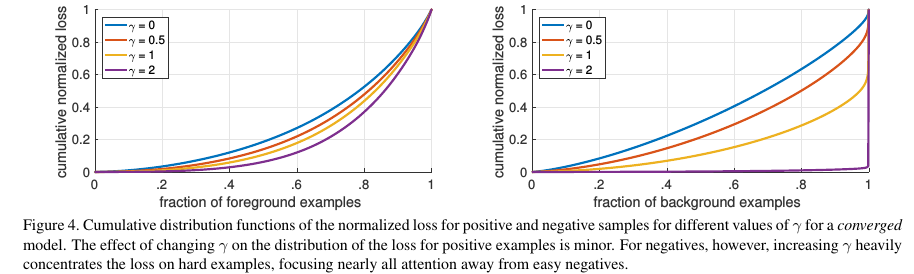
Focal Loss存在這兩個超參數(hyperparameter),不同的αt和γ,對于的loss如Figure 1所示。從Figure 4, 我們可以看到γ的變化對正(forground)樣本的累積誤差的影響并不大,但是對于負(background)樣本的累積誤差的影響還是很大的(γ=2時,將近99%的background樣本的損失都非常小)。
接下來看下實驗結果,為了驗證Focal Loss,作者提出了一種新的one-stage detector架構RetinaNet,采用的是resnet_fpn,同時scales增加到15個,如Figure 3所示
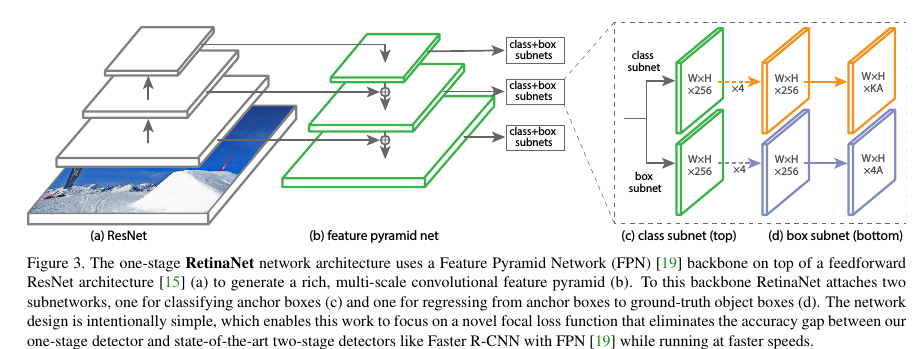
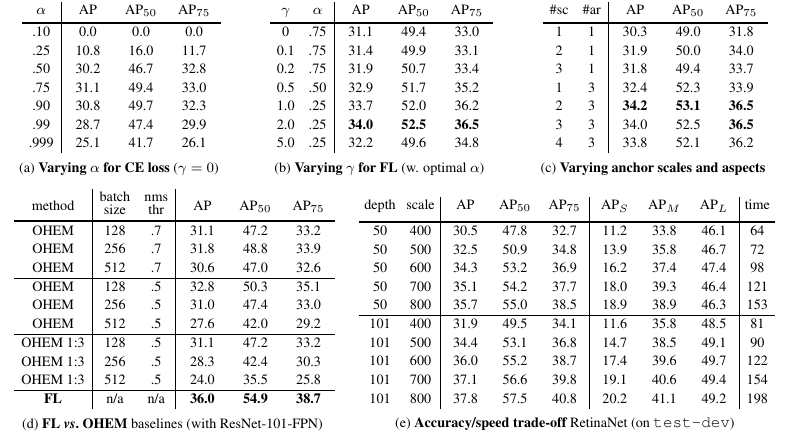
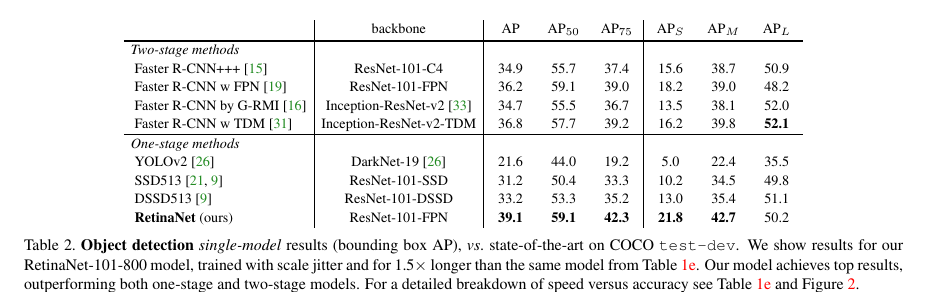
Table 1給出了RetinaNet和Focal Loss的一些實驗結果,從中我們看出增加α-類別均衡,AP提高了0.9,再增加了γ控制,AP達到了37.8.Focal Local相比于OHEM,AP提高了3.2。從Table 2可以看出,增加訓練時間并采用scale jitter,AP最終那達到39.1。
Focal Loss的原理分析和實驗結果至此結束了,那么,我們接下來看下Focal Loss的反向傳播。首先給出Softmax Activation的反向梯度傳播公式,為
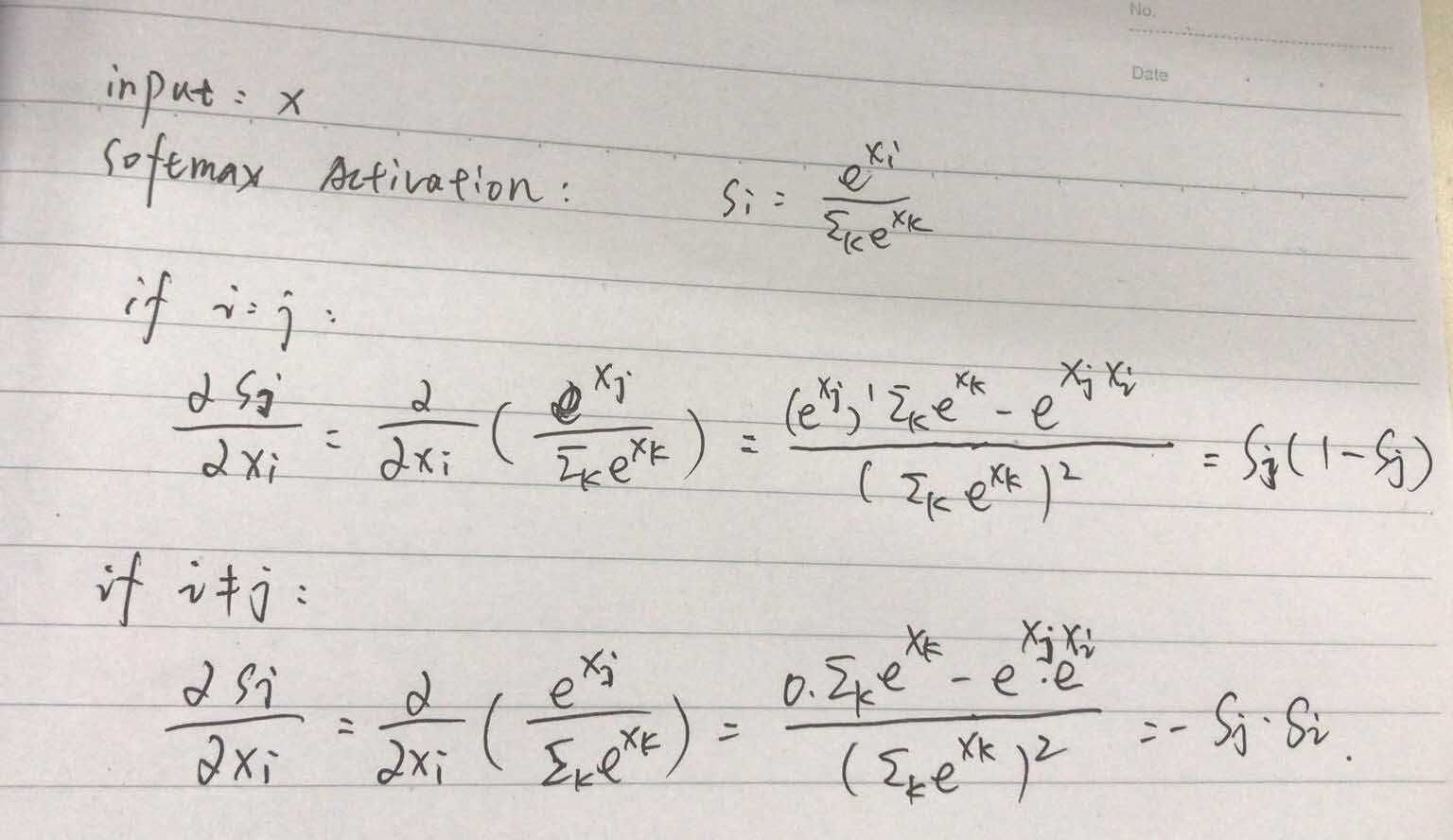
有了Softmax Activation的反向梯度傳播公式,根據鏈式法則,Focal Loss的反向梯度傳播公式為
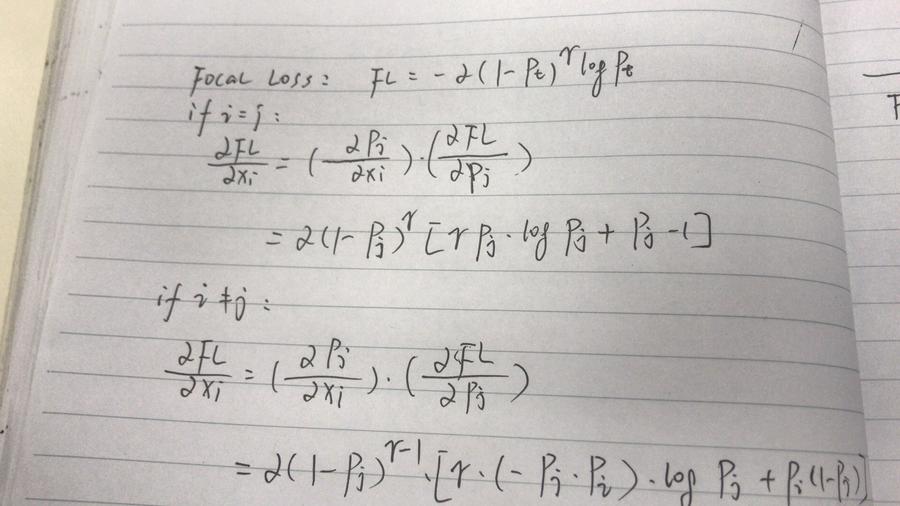
1.PyTorch是相當簡潔且高效快速的框架;2.設計追求最少的封裝;3.設計符合人類思維,它讓用戶盡可能地專注于實現自己的想法;4.與google的Tensorflow類似,FAIR的支持足以確保PyTorch獲得持續的開發更新;5.PyTorch作者親自維護的論壇 供用戶交流和求教問題6.入門簡單
以上是“pytorch如何實現多個反向傳播操作”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





