溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Redis數據結構中鏈表與字典的使用案例,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
關于鏈表的基礎概念其實你在學習Redis之前一定積累了不少,所以本文將默認你已經掌握了鏈表相關的基礎知識,而Redis的鏈表其實也就是普通的鏈表~
因為Redis是使用C語言編寫的,因此Redis的數據結構的定義都是使用C語法定義的,你不需要完全理解下方C語言聲明結構體的語法,但我認為依靠大家的Java知識也能理解這就像是在Java中定義了一個鏈表對象
Redis鏈表節點的結構
typedef struct listNode {
struct listNode *prev; //指向前一個鏈表節點
struct listNode *next; //指向后一個鏈表節點
void *value; //當前節點的值(可以按需設定不同數據類型的value)
} listNode;很明顯,當每一個節點內記錄了前后兩個節點位置之后,鏈表節點之間就能夠彼此前后相連,組成雙向通行車道(可以雙向遍歷)
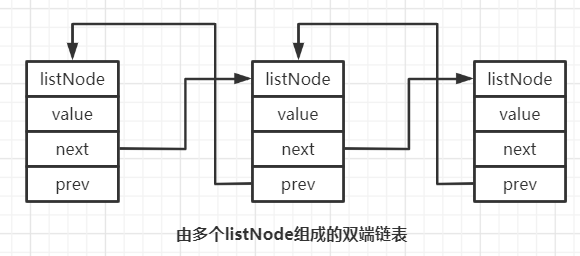
上面講解了Redis的鏈表的節點表示,并由此引申了一下可以借此構建Redis雙端鏈表,而事實上,對于每一個存在的雙端鏈表,Redis使用一個list結構來表示
typedef struct list {
listNode *head; //表頭節點
listNode *tail; //表尾節點
unsigned long len; //鏈表所包含的節點的數量
void *(*dup)(void *ptr); //節點復制函數
void (*free)(void *ptr); //節點釋放函數
void (*match)(void *ptr, void *key);//節點值對比函數
} list;很明顯,你看到三個好像是返回值為void的函數,但是看不懂C語法,沒關系,傳統后端功夫,自然是點到為止
我不想現在就告訴你,鏈表被廣泛用于實現Redis的各種功能,比如列表鍵、發布于訂閱、慢查詢、監視器等,等我們后面講到這幾部分的時候,白澤再結合鏈表和你細說~
和鏈表一樣,Redis所使用的C語言并沒有內置字典這種數據結構,因此Redis構建了自己的字典實現。如果你學過數據結構,你會發現Redis的字典事實上就是數據結構中的鄰接表,即使沒學過,往下看就好啦~
數組 + 鏈表 ==> 鄰接表,實錘
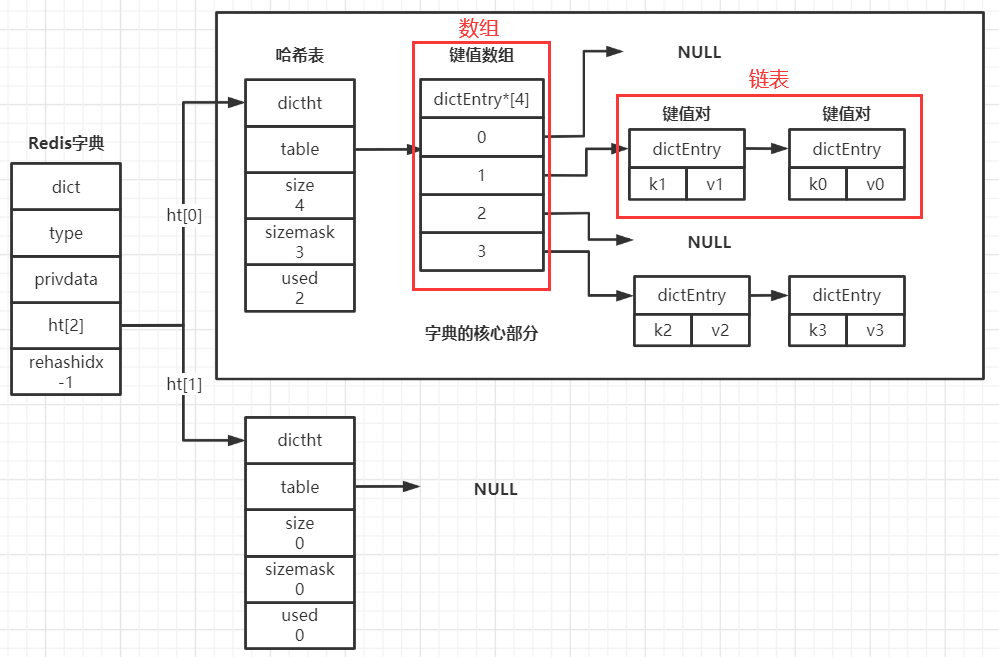
還記得嗎,上面我們說Redis鏈表可以用list描述,但是鏈表存儲的數據本質上,是由一系列listNode節點通過前后指針相連存儲的;類似的,Redis字典可以用如下dict描述,但是字典存儲的數據本質上,是由數組 + 若干鏈表組合得到的數據結構存儲的,字典dict結構如下:
typedef struct dict {
dictType *type; //類型特定函數
void *privdata; //私有數據
dictht ht[2]; //哈希表數組
int trehashidx; //rehash索引,當rehash不在進行時,值為-1
} dict;現在你只需要關注其中的哈希表數組ht[2],它的數據類型為dictht,因此也是一種復合的數據結構,如下:
typedef struct dictht {
dictEntry **table; //哈希表數組
unsigned long size; //哈希表大小
unsigned long sizemax; //哈希表大小掩碼,用于計算索引值,等于size - 1
unsigned long used; //該哈希表已有節點的數量
} dictht;哈希表dictht是Redis字典的核心,dictht的四個屬性中,size、sizemax、used都是用于描述table屬性整體狀態。看到這你就明白了,dictht的核心是dictEntry類型的table屬性(再次提醒,如果沒有C語言的基礎,本文中一切你看不懂的語法,包括數據類型,你只需要一眼帶過即可,我們的目的是學習Redis的設計思想)
table屬性是一個數組,數組中的每個元素都是一個指向dictEntry結構的指針,每個dictEntry結構保存一個鍵值對,并含有一個指向下一個dictEntry的指針,結構如下:
typedef struct dictEntry {
void *key; //鍵
union { //值(可以是一個指針,可以是一個uint64_t類型的整數,也可以是一個int64_t類型的整數)
void *val;
uint64_t u64;
int64_t s64;
} v;
struct dictEntry *next;//指向下個哈希表節點,形成鏈表
} dictEntry;我們知道,字典是用來存儲數據的,并且是以鍵值對的形式存儲的,那么我每次存入一個鍵值對放在字典的哪里?這就是哈希算法為你解決的事情:程序需要先根據鍵值對的鍵計算出哈希值和索引值,然后再根據索引值,將包含新鍵值對的哈希表節點放到哈希表數組的指定索引上面
比如我已經有下面這個字典,然后要插入一個鍵值對數據:k1 : v1,則程序有如下計算過程:(用戶只是往Redis服務器中插入了一條數據,下面都是程序內部的工作~)
hash = dict->type->hashFunction(k1); //計算k1鍵的hash值(得到某個數值) index = hash & dict->ht[0].sizemask = 1; //計算k1鍵插入位置的索引值

解決鍵沖突
鍵沖突:當不同的key值計算得到的dictEntry索引值相同時,就稱發生鍵沖突(我要插入的位置已經被占用了,插入使得鏈表長度由1變多,當然第一次插入不算沖突)
解決方法:
就像上面我要插入一個k1 :v1的鍵值對,并計算得到插入位置的索引為1(但是distEntry數組中索引為1的位置已經有k0 :v0鍵值對存放了),因此程序會在哈希表ht[0]的dictEntry數組的索引為1的位置上插入一個dictEntry節點,放在原本鏈表首部的前一位置(搶占首位),其中存放著k1 : v1鍵值對,插入后的圖如下:
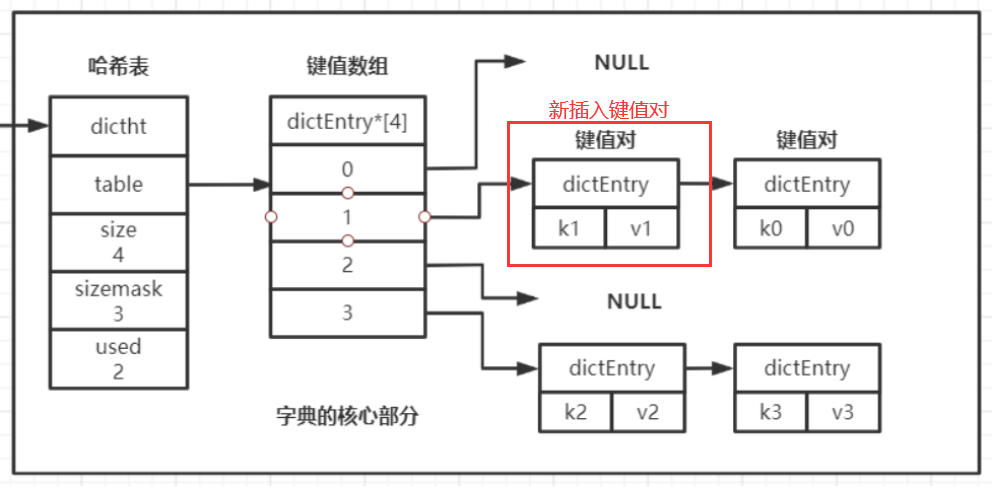
你可能疑惑新插入的鍵值對的位置在每個dictEntry鏈表的最前面,而不是尾部,原因是每個dictEntry中除了保存鍵值對之外,只記錄了下一個dictEntry的地址(上面我已經給出了dictEntry的結構了~),程序無法直接得到dictEntry鏈表的最后一個節點,但可以直接得到第一個節點(通過dictEntry數組索引直接定位),因此每次插入的dictEntry節點(鍵值對)都將直接插入到對應索引的鏈表的頭部(因此dictEntry數組的內容是不斷在變的)
一句話來說:distEntry數組幫助使用索引定位,distEntry鏈表,用于處理沖突,不斷維護所存儲的鍵值對數據
隨著操作的不斷執行(增、刪、改、查),哈希表保存的鍵值對會逐漸增多或者減少,為了讓哈希表的負載因子維持在一個合理范圍內,當哈希表保存的鍵值對數量太多或太少時,程序會對哈希表的大小進行相應的擴展或者收縮(不知道你是否記得還有一個哈希表ht[1]的存在,這個表就是為了和ht[0]配合進行rehash而存在的)
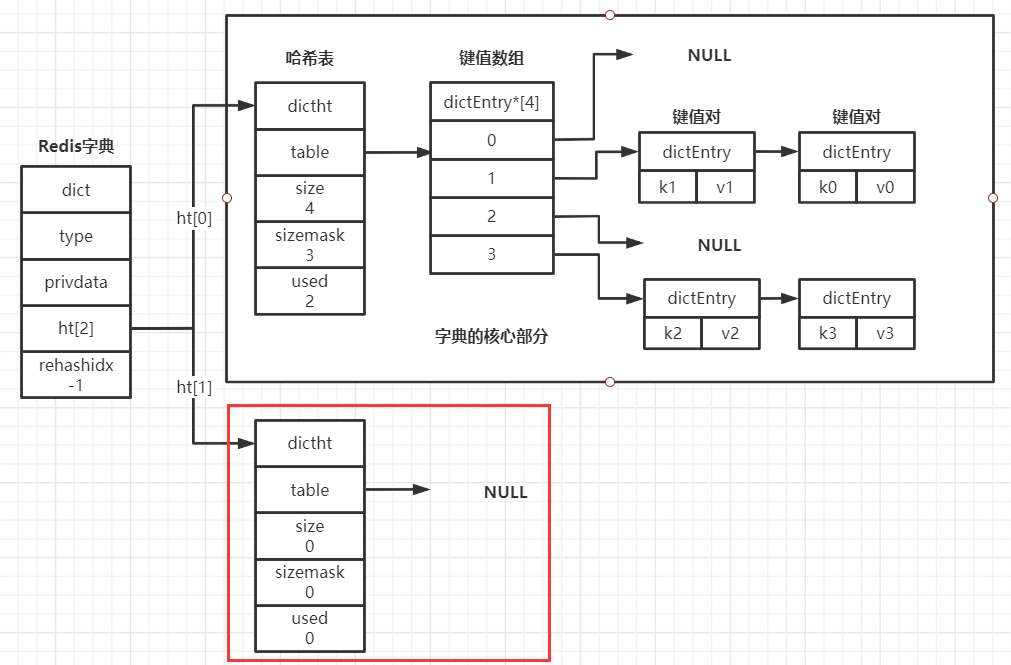
rehash步驟:
為字典的ht[1]哈希表分配空間
如果程序執行擴展操作:
ht[1].size = 第一個大于等于ht[0].used * 2(ht[0]已經使用的空間大小乘2)的2的n次方冪
如果程序執行收縮操作:
ht[1].size = 第一個大于等于ht[0].used(ht[0]已經使用的空間大小)的2的n次方冪
將保存在ht[0]上的鍵值對rehash到ht[1]上,因為size不同,所以是重新hash,而不是整體復制
當ht[0]內鍵值對全部遷移到ht[1]中后,釋放ht[0],然后將ht[1]和ht[0]的互換(rehash結束),此時ht[0]就是一個rehash后的哈希表,而ht[1]依舊為空表,為下次rehash做準備
上面提到的在哈希表ht[0]的負載因子過大或者過小會觸發rehash,但是,事實上rehash遷移的過程不是一蹴而就的(很明顯,如果數據ht[0]的數據很多,每次rehash如果都遷移全部數據,需要花費較大時間等待,用戶在rehash期間訪問Redis服務器將會陷入無響應的狀態)
漸進式過程:
將rehash的過程分攤在后續的每次增、刪、改、查操作上,在rehash期間,每次對字典執行操作,程序除了執行指定操作外,還會順帶將ht[0]哈希表在rehashidx索引(從0開始,-1表示rehash未開始)上的所有鍵值對rehash到ht[1],當每次局部rehash工作完成后,程序將rehashidx屬性的值增一
注意:每次對字典進行增、刪、改、查會在ht[0]和ht[1]上同時進行,比如查找一個鍵,則會現在ht[0]上查找,沒找到再去ht[1]上查找,諸如此類,除了增加操作每次都將直接hash到ht[1]上,不會對ht[0]執行任何添加操作
感謝你能夠認真閱讀完這篇文章,希望小編分享的“Redis數據結構中鏈表與字典的使用案例”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





