溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Java中hashcode的示例分析,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
Java的基本數據類型分為:1、整數類型,用來表示整數的數據類型。2、浮點類型,用來表示小數的數據類型。3、字符類型,字符類型的關鍵字是“char”。4、布爾類型,是表示邏輯值的基本數據類型。
Hash,一般翻譯做散列、雜湊,或音譯為哈希,是把任意長度的輸入(又叫做預映射pre-image)通過散列算法變換成固定長度的輸出,該輸出就是散列值。這種轉換是一種壓縮映射,也就是,散列值的空間通常遠小于輸入的空間,不同的輸入可能會散列成相同的輸出,所以不可能從散列值來確定唯一的輸入值。簡單的說就是一種將任意長度的消息壓縮到某一固定長度的消息摘要的函數。
這個說的有點官方,你就可以把它簡單的理解為一個key,就像是map的key值一樣,是不可重復的。
1.在散列表
2.map集合
此處只是做了一個簡單的介紹,其實遠遠沒有那么簡單,如算法里面的散列表,散列函數,以及map的一個不可重復到底是怎么樣去判斷的,以及hash沖突的問題,都與hash值離不開關系。
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}可以看到,String類的hashcode方法是通過,char類型的方式進行一個相加,因為String類的底層就是通過char數組來實現的。
如:String str="ab"; 其實就是一個char數組 char[] str={'a','b'};
如:字符串 String star=“ab”;那么他對應的hash值就是:3105
怎么算出來的呢?
val[0]='a' ; val[1]='b'
a對應的Ascall碼值為:97
b對的Ascall碼值為:98
那么經過如下代碼的循環相加
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}得出:97*31+98=3105;
我們再看: int h = hash;這一個代碼,為什么有時候調用hashcode方法返回的hash值是負數呢?
因為如果這個字符串很長?那么h的值就會超過int類型的最大值,有沒有想過,如果一個int類型的最大值,超過他的范圍之后會怎么樣呢?
我們先來看這樣一個簡單的代碼:
int count=0;
while (true){
if (count++<10){
System.out.println("hello world");
}
}大家認為hello world會輸出多少次呢?
正常情況來說count小于10就不會輸出了對么?
但是其實并不是這樣的,很明確的告訴大家,這是一個死循環。
因為count一直加,最開始if成立,到后面的if不成立,再到后面if會再次成立,為什么會成立呢?因為count變為了負數。
???? 為什么?因為count一直無限制的加,由于是線性增長,計算速度是非常快的,所以,要不了多久,就會超出int類型的最大值。控制輸出的count變為了負數,所以呢此時的if條件又成立了。

首先我們來看下int的范圍 :int 為4個字節,一個字節為8位,一個int值是需要的存儲空間是32位,但是呢?這是一個有符號位的int,需要一個符號位來表示正數和負數,
int值的范圍就是:-2^31 ~ 2^31 也就是:-2147483648 到2147483647
我們來看下int最大值對應的二進制位是對少?
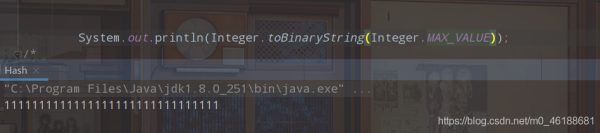
全是1? 2147483647最大值不是一個正數么?難道第一位難道不是應該用0表示么?
此時這個0他是省略掉了沒寫的,由于二進制系統是通過補碼來保存數據的。第一位是符號位,0為正,1為負,當正的除了符號位全為1,再加1就進位了,符號位就會變成1,是負數,其他為0。
所以說當int的最大值加一個1,就變為了,最小值
來!口說無憑,沒有說服力,我們直接來看代碼:
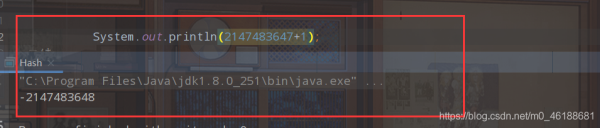
那么我們在反過來想,最小值減1呢?那是不是就是對對應的是我們int類型的最大值了呀?
認真仔細的看完這個,你就知道為什么hashcode方法調用的時候有時候是正數,有時候是負數了吧?所以說底層還是很有意思的,比如往后做大數據開發,那么肯定是需要深入理解這些數據類型的范圍,以及他的一個變化規則,否則有時候不知不覺的就犯錯了,你還不知道錯誤在那兒?嚴重的話就是會損失精度,導致結果和你預期的結果相差甚遠。就因為加了個1,就導致結果和預期結果相差十萬八千里。
這是String類的hashcode方法的一個具體實現過程。
首先呢?這個肯定是不對的。
因為這兩個方法都可以重寫,如果是自己的類,那么可以靈活重寫,如果是jdk自己的類,那就要看他到底有沒有重寫這兩個方法。
我們以String類的equlas方法為例:我們都知道,如果equlas方法如果沒有重寫,那就繼承Object類的equlas方法,默認比較的是兩個對象的內存地址,如果重寫了,那就根據我們自己重寫的規則來比較兩個對象是否相等。
如下是jdkString類中自己重寫的equals方法,
public boolean equals(Object anObject) {
// 如果兩個String類型的對象內存地址相等直接返回true
if (this == anObject) {
return true;
}
// 如下做的操作就是比較兩個字符串中的每一個char類型的數據,如果都完全匹配,那么就是返回true,如果有一個不相同,直接返回false,并且兩個字符串的長度要相等,如果不相同,那么肯定也就不可能值一樣了嘛
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}再看下String的hashcode方法:就是我們上面剛剛講過的那個方法
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}1:如果兩個String類型的對象內存地址相等直接返回true
2:比較兩個字符串中的每一個char類型的數據,如果都完全匹配,那么就是返回true,如果有一個不相同,直接返回false,并且兩個字符串的長度要相等,如果不相同,那么肯定也就不可能值一樣了嘛
由此可以看出,equals方法是否返回true跟hashcode方法沒有半毛錢關系嘛。
接下來我們看下,我們自定義的對象,我創建一個User類,里面有屬性id和name
public class User {
int id;
String name;
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
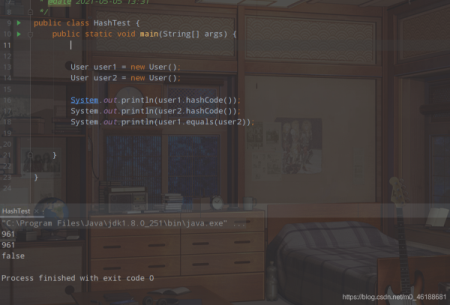
}在沒有重寫hashcode方法和equals方法的情況下進行比較:
User user1 = new User(); User user2 = new User(); System.out.println(user1.hashCode()); System.out.println(user2.hashCode()); System.out.println(user1.equals(user2));

解答:因為我們沒有重寫,這兩個方法都是繼承自Object類的,所以呢?比較的是內存地址,因為我們是通過new的方式去創建的兩個user對象,那么他們的內存地址肯定是不相同的,所以直接返回false,而hashcode方法是java的底層語言c++來寫的,具體他內部是怎么實現的,封裝了,我也就不得而知了,后面再了解,有的人說是跟內存地址相關,但是具體我沒有看到具體實現,也不敢茍同,有的東西,需要自己不斷的去摸索,自己親自實踐,才是真的,不要相信別人說的。
好的,接下來我們重寫User類的hashcode方法:
public class User {
int id;
String name;
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
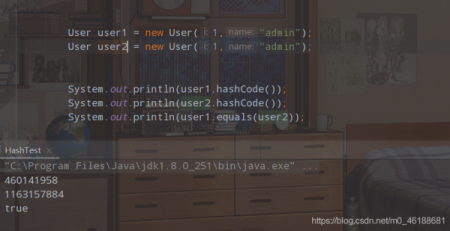
@Override
public int hashCode() {
return Objects.hash(id, name);
}
}
可以看到的是,我們兩個User對象的hashcode方法返回的hash值是完全一致的,但是通過equals方法進行比較,還是false,所以說,兩個對象的hashcode方法返回的hash值相同,equlas也一定返回true是完全不成立的,直接推翻。
接下來我們再次重寫equlas方法,此時我們規定,只要兩個對象的id和name都相同,那么這兩個對象就是同一個對象。并且刪除掉剛剛我們重寫的hashcode方法。
public class User {
int id;
String name;
public User(int i, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return id == user.id &&
name.equals(user.name);
}
}
通過運行結果,我們可以看到,hashcode方法返回的hash值不一致,但是我們的equlas方法依舊返回的是true,因為這個equlas方法是我們重寫過了,在調用的時候,就不在去掉Object的equlas方法,進行比較內存地址,而是按照我們的重寫規則:如果兩個user對象的id和name相同,那么就是同一個對象,所以到這里,你是不是就具體的理解了hashcode方法個equlas之間的關系呢?
如果還是不明白,那再看一次,我們現在把User類的equlas方法和hashcode方法都寫上,但是呢?我會創建兩i不同的User對象(也就是id和name都不一樣)。
public class User {
int id;
String name;
public User(int i, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return id == user.id &&
name.equals(user.name);
}
@Override
public int hashCode() {
return Objects.hash(id, name);
}
}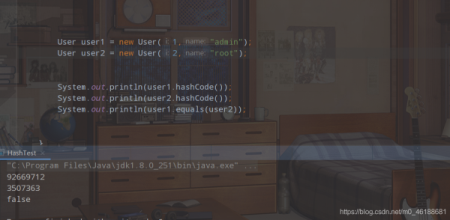
由此可以看到,雖然hashcode方法返回的hash值相同,但是通過equlas方法進行比較,返回的直接就是false。
以上是“Java中hashcode的示例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





