溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
目前,各組織正在利用數據科學和機器學習來解決各種業務問題。為了創造一個真正的業務影響,如何彌合數據科學管道和業務決策管道之間的差距顯得尤為重要。
數據科學管道的結果往往是數據中的預測、模式和洞察(通常沒有任何約束的概念),但僅此一項并不足以讓股東做出決定。數據科學的輸出應該要接入某種商業決策導管;這個導管包含有一些可以模擬商業關鍵方面的限制和決策變量的改善。
例如,如果您正在運行一個超市鏈—您的數據科學管道將會預測預期的銷售額。然后,您將接受這些輸入的數據并創建一個優化的庫存方式或銷售策略。
在這篇文章中,我們將展示一個這樣的例子,用線性優化來選擇觀看哪一個TED視頻。
索引
線性優化導論
待解決問題–為TED視頻創建觀看列表
步驟1-導入相關軟件包
步驟2-為TED會談創建數據框架
步驟3-設置線性優化問題
步驟4-將優化結果轉換為可理解的形式
在優化技術中,采用單純形法進行線性優化是最有效的方法之一,也被評為二十世紀十大種算法之一。作為數據科學從業者,在實現線性優化方面有實際的知識是很重要的,這篇博文是用Python的PuLP包裝來說明它的實現。
為了使事情變得有趣并容易理解,我們會通過將它應用于實際的日常問題來學習這種優化技術。與此同時,我們學到的東西也適用于各種商業問題。
TED是一個致力于傳播思想的非營利組織。TED于1984年成立,以會議的形式融合了技術、娛樂和設計等方面的知識;到了今天,TED幾乎涵蓋了100多種語言中以及近乎所有主題—從科學到商業再到全球問題。TED演講是由擁有豐富的信息并熱愛其所在領域的專家們所提供的。
現在,別忘了這個博客文章的目的,想象一下這種情況:你想創建一個根據不同條件下的(可以觀看的時間以及演講的數量等)TED會談最受歡迎的觀看列表。我們來看看如何通過Python程序來幫助我們以最佳的方式創建觀看列表。
本文的代碼可以在這里找到。我的Jupyter的截圖如下所示:

PuLP是在Python下的一款免費開源軟件。它可以將優化問題描述為數學模型。PuLP也可以調用許多外部的LP求解程序(例如CBC,GLPK,CPLEX,Gurobi等)來解決這個模型,然后使用python命令來操作和顯示解決方案。默認情況下,CoinMP求解程序是與PuLP捆綁在一起的。

從Kaggle下載所有TED演講(2550)的數據集,都并寫入數據框架。選擇相關列的子集,并且結果數據集應包含以下詳細信息—講演的索引、講演的名稱、TED事件的名稱、講演的持續時間(以分鐘計)、視圖數(代表演講的人氣)

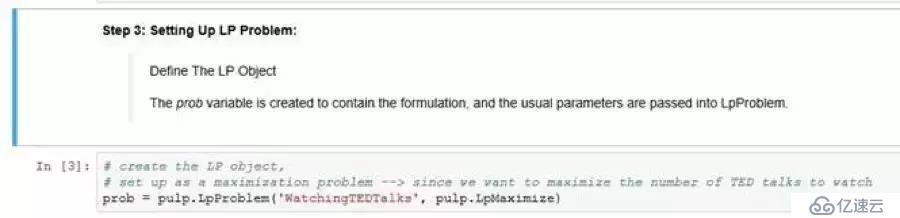
從定義LP對象開始;問題變量的創建是為了控制問題制定。
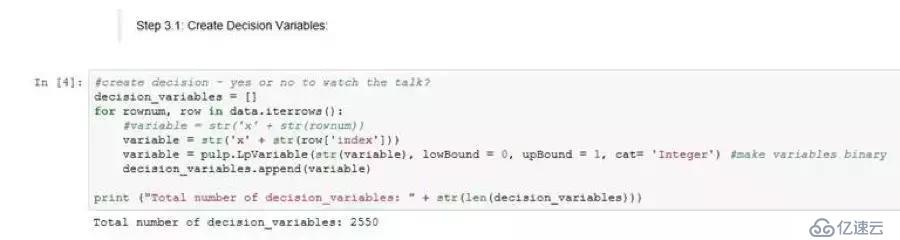
步驟3.1:創建決策變量
遍歷數據框架的每一行以創建決策變量,以便每個講演都成為一個決策變量。因為每個講演都可以被選擇或者不被選擇為最后的觀看名單的一部分,決策變量本質上是二進制的(1=選定,0=未選定)
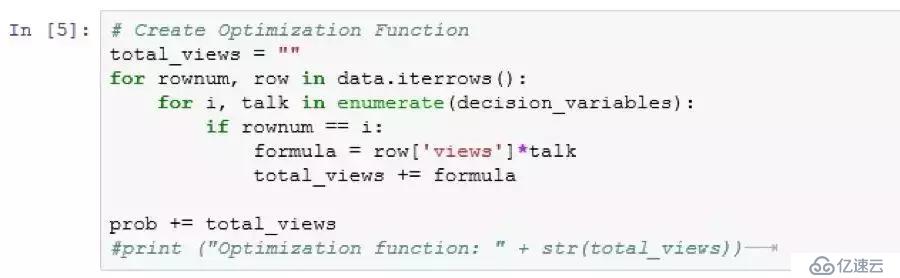
步驟3.2:定義目標函數
目標函數是每個講演觀看量的所有行的總和。這些觀看量作為講演的受歡迎度的代表,因此在本質上我們試圖通過選擇適當的談話(決策變量)來最大化觀看量(受歡迎度)
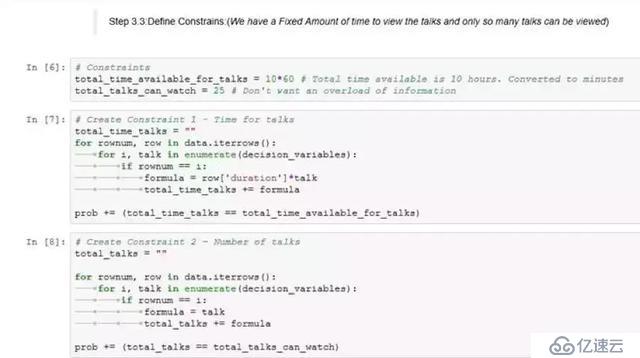
步驟3.3:定義約束
在這個問題上,我們有兩個約束:
a)我們只有固定的總時間,這些時間可以被分配來觀看會談
b)我們不希望觀看超過一定數量的會談,以避免信息超載
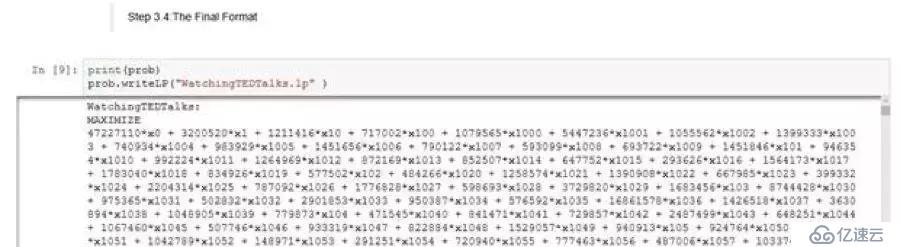
步驟3.4:最終格式(對于問題的制定)
所制定問題的最終格式會被寫出到一個.lp文件中。這將列出目標函數、決策變量以及對問題施加的約束。
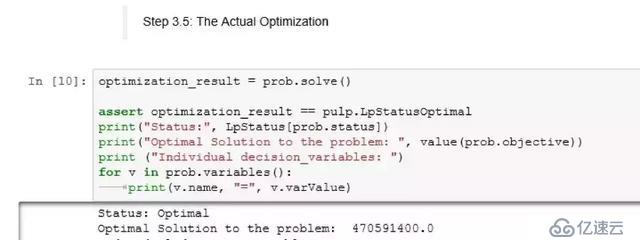
步驟3.5:實際優化
實際優化就是一行叫做"prob.solve"的代碼。插入一句說明語句以確定是否為該問題獲得了最佳結果。
表明特定的、被選上以最大化輸出的決策變量(講演)的優化結果,必須轉換成觀看列表的格式,如下所示:


本文展示了如何利用Python中可用的線性優化技術,來解決創建視頻觀看列表的日常問題。所學的概念同樣適用于更復雜的業務情況,比如涉及到數以千計的決策變量或是有許多不同的約束。
每一位數據科學從業者都需要將"優化技術"添加到他們的知識體系中,這樣他們就可以使用高級的分析方式來解決現實世界中的業務問題。這篇文章旨在幫助您朝著這個方向邁出第一步。
免責聲明:所有翻譯文章旨在技術傳播和學習交流,非商業用途。原作者:Karthikeyan Sankaran
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





