溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
正則表達式(或 RE)是一種小型的、高度專業化的編程語言,(在Python中)它內嵌在Python中,并通過 re 模塊實現。正則表達式模式被編譯成一系列的字節碼,然后由用 C 編寫的匹配引擎執行。
字符匹配:普通字符、元字符
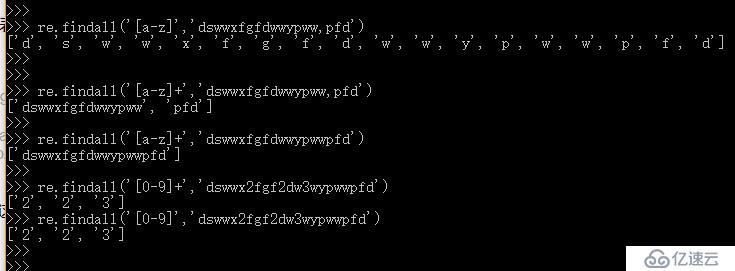
1、普通字符類似精確匹配:
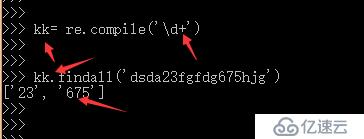
re.findall()第一個參數是規則,第二個參數是匹配的字符串。
2、元字符
元字符:*. ^ $ + ? { } [ ] | ( ) **
1、. 一個點號代表一個任意字符,多個代表多個。不包括換行符號(\n , \t , \r)
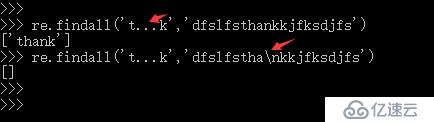
2、^ 開頭符號 (^a :表示匹配以a開頭字符串)
3、$ 結尾符號 (a$: 表示匹配以a結尾的字符串)
4、* 星號代表匹配 0到無窮次
5、+ 代表匹配 1 到 無窮次
6、? 代表匹配 0 到 1次
7、{} {0,1} 這樣寫代表匹配0到1次,{2,8}代表匹配2到8次
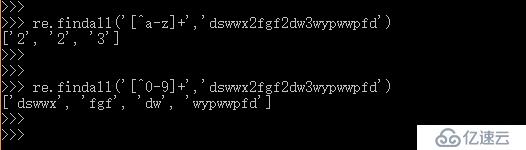
8、[] 這個中括號是 字符集 的意思。例 :k[yc] 表示匹配 ky 或 kc ‘或’的意思

字符集里面可以應用3個符號: - . ^ . \ ,除了這三個符號,其余符號都代表是字符
加個 - 符號:
加個 ^ 符號,‘非’ 的意思:
字符集加 \ 跟元字符效果一樣,(轉義符)
**元字符之轉義符\
反斜杠后邊跟元字符去除特殊功能,比如.
反斜杠后邊跟普通字符實現特殊功能,比如\d
\d 匹配任何十進制數;它相當于類 [0-9]。
\D 匹配任何非數字字符;它相當于類 [^0-9]。
\s 匹配任何空白字符;它相當于類 [ \t\n\r\f\v]。
\S 匹配任何非空白字符;它相當于類 [^ \t\n\r\f\v]。
\w 匹配任何字母數字字符;它相當于類 [a-zA-Z0-9]。
\W 匹配任何非字母數字字符;它相當于類 [^a-zA-Z0-9]
\b 匹配一個特殊字符邊界,比如空格 ,&,#等
例如使用 \b 就要使用轉義符:
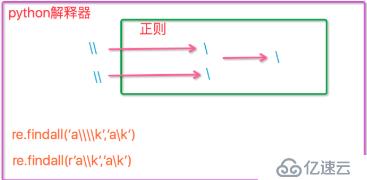
匹配字符串
'jfdji\ldfdsf'里的i\l,就要多加3個 \ 因為python解釋器轉義之后傳給 re模塊 ,re模塊再轉義:
打印結果是兩個 \ 應該是進去兩個出來兩個。
9、| 代表或的意思。例如:an|jk :匹配 an 字符串 或 jk 字符串
10、() 括號內字符串為整體 例如: (abc) 代表匹配 abc 字符串

re.findall('a','alfgd') #返回所有滿足匹配條件的結果,放在列表里
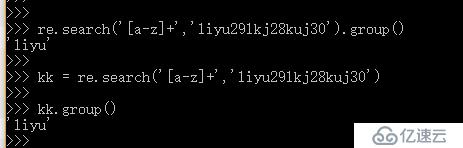
re.search() # 函數會在字符串內查找模式匹配,只到找到第一個匹配然 后返回一個包含匹配信息的對象,該對象可以通過調用 group()方法得到匹配的字符串,如果字符串沒有匹配,則 返回 None。
re.search('(?P<組名>[a-z+])') ,可以給匹配到的數據設置組名(?P<組名>是gu固定格式)
`re.match('a','abc').group()`` 和 search一樣,不過match只從字符串開頭匹配 ,如果這個例子不是 a 開頭 ,會報錯
re.split() 分割字符串 例: 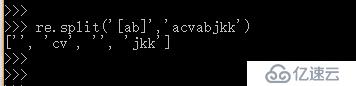
上圖中分割步驟為:
按字符串第一個a分割,因為a左邊為空所以得到 ' ' 和cvabjkk ,然后遇到a再分割得到 cv 和bjkk , 然后再從 b分割 b左邊為空 ,變成 ' ' jkk ,然后整個加起來: ['', 'cv', '', 'jkk']
re.sub() 替換方法,有4個參數。例如 re.sub('\d','abc','adfs5dfs6',1)
上述例子第一個參數為要被替換的字符串,第二個為替換后的字符串,第三個為要修改的原始字符串,第四個為要替換多少次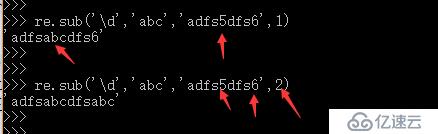
re.subn('\d','abc','adfs5dfs6') 加個n可以統計被替換多少次:
re.compile() 制定匹配規則:
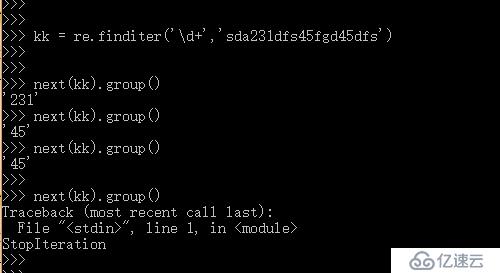
re.finditer() 會把匹配結果變成一個迭代器;
如下圖,應該匹配出 www.baidu.com 以及www.sina.com ,顯示結果沒有匹配:
中間家里 括號(分組),會優先顯示出分組里的內容,要取消有限權限 加上 ?:

免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。