溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
一 前言
最近在開發的數據核對方案中用到了Python標準庫Difflib,本來它工作的挺符合預期,可當它遇到那個文件,仿佛遇到了克星,那文件才100行*77列的數據,經它對比,居然耗時61s。這是無法接受的,因為后續線上流量抽取比對,絕非這點量級。該怎么破?
?
二 重現現象
以下是使用Difflib比對那個文件,數據量是100行*77列,耗時61s,如下:
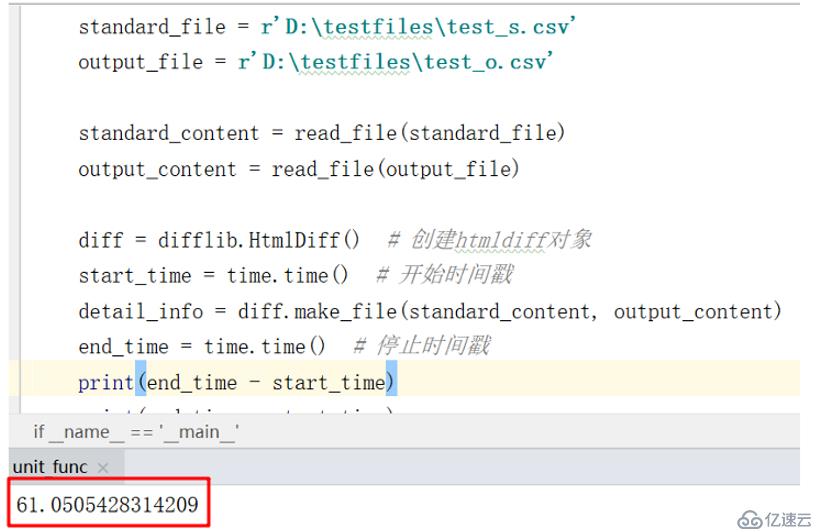
好吧,那就降低數據量到5行*77列,看看效果,耗時只有0.05s,如下:
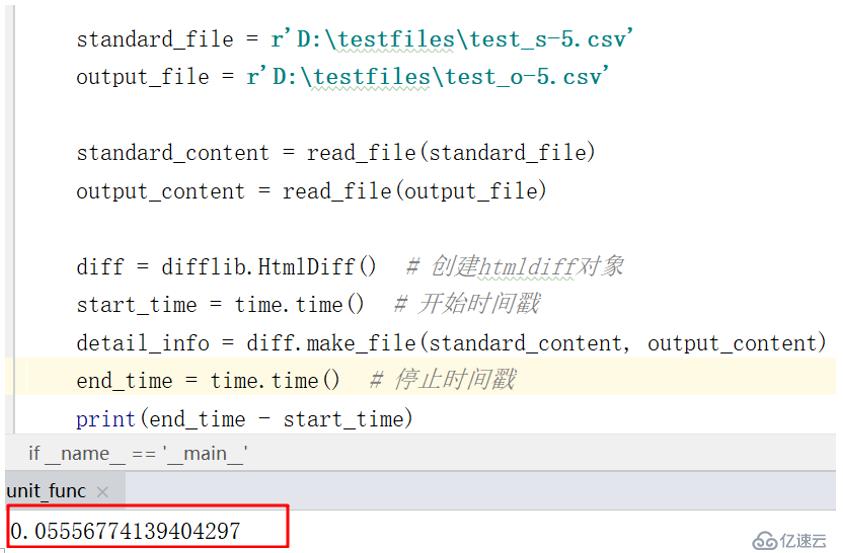
從耗時結果上,不難發現,Difflib在這個文件的比對性能較差,而且耗時不隨數據量線性增加,這是最恐怖的地方,如果繼續增大數據量,耗時將會變得無法忍受。
?
三 優化思路
Difflib作為標準庫,它的功能只是比對數據,然后生成各樣結果格式。當遇到耗時嚴重這類問題,首先應該從自己的數據上入手,我的優化思路有兩個:
第一,?? 過濾掉相同的行數據,降低比對數據量;
第二,?? 數據分片;
針對第一個思路,將文件以行分割存放到列表,然后將列表相同位置的相同數據刪除掉,只剩下不同的行數據,這樣做的好處很明顯,一方面可以降低比對的數據量,提升效率,另外,輸出的結果也更干凈,不會再輸出無必要的相同行數據;
針對第二個思路,將待比對的數據劃分成一個個相對較小的數據塊,實現快速比對,這個方法的可行性,可以從上述數據量耗時比對得出。
?
四 具體實現
過濾相同行優化策略,實現代碼如下:
#?過濾相同行 source_length?=?len(source)??#?source為原始數據按行分割的列表 target_length?=?len(target)??#?target為目標數據按行分割的列表 min_length?=?source_length?if?source_length?<?target_length?else?target_length? pos_list?=?[]??#?標記相同行的行號,保留列頭 for?index?in?range(1,?min_length): ????#?注意保序 ????if?operator.eq(source[index],?target[index]): ????????pos_list.append(index) #?刪除相同行數據,?注意索引漂移 source?=?[source[index]?for?index?in?range(source_length)?if?index?not?in?pos_list] target?=?[target[index]?for?index?in?range(target_length)?if?index?not?in?pos_list]
數據分片優化策略,實現代碼如下:
#?分片 max_length?=?source_length?if?source_length?>?target_length?else?target_length?#?用于分片 #?分片,注意保證不能漏行 start_pos?=?0 step?=?10??#?分片大小,即單次比對行數,默認10行 end_pos?=?start_pos?+?step diff?=?difflib.HtmlDiff()??#?創建htmldiff實例對象 while?end_pos?<?max_length?+?step: ????detail_info?=?diff.make_file(source[start_pos:?end_pos],?target[start_pos:?end_pos]) ????#?處理邏輯
?
五 優化結果
在僅使用數據分片的優化策略的情況下,比對那個100行*77列的文件,結果顯示比對耗時僅1.8s。而正如上文所述,優化前比對該文件的耗時為61s,更重要的是,因為數據分片,每片比對耗時基本穩定,即使數據量繼續增大,耗時也只是線性增加,而不再是類似指數型增加。另外,如果疊加過濾數據的第一種策略,相信隨著數據量的下降,耗時數據會有更好的表現。但為了更直觀的比對相同數據量下優化前后的效果,所以,在此只是使用數據分片的策略。
優化后耗時結果如下:

?
六 其他
本文針對Python標準庫Difflib比對文件時遇到的耗時嚴重問題,提出了兩種優化策略,并經測試驗證有效,即僅在數據分片策略下,同樣文件的比對耗時從原先的61s降到1.8s,且耗時只是線性增加。如果有更好的方法,歡迎留言、交流。
關于python學習、分享、交流,筆者開通了微信公眾號【小蟒社區】,感興趣的朋友可以關注下,歡迎加入,建立屬于我們自己的小圈子,一起學python。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





