溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關如何使用Python自動下載網站所有文件的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
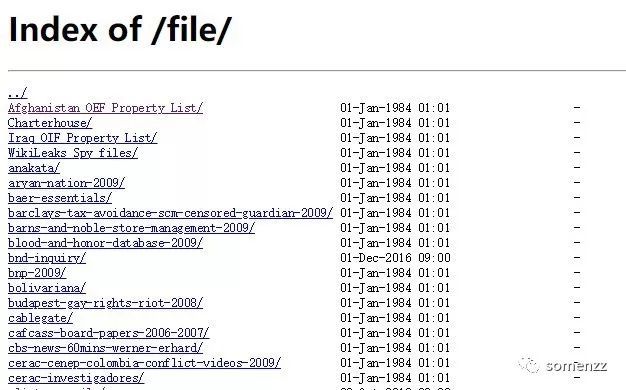
假如一個網站,里面有很多鏈接,有指向文件的,有指向新鏈接的,新的鏈接點擊進去后,仍然是有指向文件的,有指向新鏈接的,類似一個文件夾,里面即有文件,又有目錄,目錄中又有文件和目錄。如何從這樣的網站上下載所有的文件,并按網站的目錄結構來保存這些文件呢?
關鍵詞:Python、下載、正則表達式、遞歸。
按照自頂向下來設計程序,我們整理自己的思路,然后使用 Python 語言來翻譯下即可。
思路:由于目錄的深度不固定,也不可能窮舉,且每一個目錄的處理方式和子目錄父目錄的處理流程都是一樣的,因此我們可以使用遞歸來下載所有文件。
遞歸代碼必須要有退出條件,退出條件要放在前面,本例中的遞歸退出條件就是:如果是文件就下載,下載完遞歸函數即完成任務。
1、給定一個 url,判斷是否是文件,如果是文件,下載即可,然后函數結束。
2、如果給定 url 不是文件,那么訪問該 url,并獲取它下面的所有鏈接。
3、遍歷步驟 2 產生的所有鏈接,遞歸的執行步驟 1 和 2,直到程序運行結束。
以上思路,用代碼描述如下:
import urllib.request import requests import re, os def get_file(url): ''' 遞歸下載網站的文件 :param url: :return: ''' if isFile(url): print(url) try: download(url) except: pass else: urls = get_url(url) for u in urls: get_file(u)
前面導入的包在接下來函數中會用到,下面就是逐漸層向下,實現子功能。
這里總結 url 規律,很容易寫出。
def isFile(url):
'''
判斷一個鏈接是否是文件
:param url:
:return:
'''
if url.endswith('/'):
return False
else:
return True下載文件時要從 url 中獲取文件應該存儲的位置,并使用 os.makedirs 來創建多級目錄。然后使用 urllib.request.urlretrieve 來下載文件。
def download(url):
'''
:param url:文件鏈接
:return: 下載文件,自動創建目錄
'''
full_name = url.split('//')[-1]
filename = full_name.split('/')[-1]
dirname = "/".join(full_name.split('/')[:-1])
if os.path.exists(dirname):
pass
else:
os.makedirs(dirname, exist_ok=True)
urllib.request.urlretrieve(url, full_name)這里要具體網站具體分析,看看如何使用正則表達式獲取網頁中的鏈接,這樣的正則表達式可以說是再簡單不過了。
def get_url(base_url):
'''
:param base_url:給定一個網址
:return: 獲取給定網址中的所有鏈接
'''
text = ''
try:
text = requests.get(base_url).text
except Exception as e:
print("error - > ",base_url,e)
pass
reg = '<a href="(.*)" rel="external nofollow" >.*</a>'
urls = [base_url + url for url in re.findall(reg, text) if url != '../']
return urls這里有個小坑,就是網站有個鏈接是返回上級頁面的,url 的后輟是 '../' 這樣的鏈接要去掉,否則遞歸函數就限入了死循環。
接下來就是寫主函數,執行任務了,慢慢等它下載完吧。
if __name__ == '__main__':
get_file('https://file.wikileaks.org/file/')其實,還會存兩個問題:
1、假如網站某頁有個鏈接它指向了首頁,那么遞歸程序仍然會限入一個死循環,解決方法就是將訪問過的 url 保存在一個列表里(或者其他數據結構),如果接下來要訪問的 url 不在此列表中,那么就訪問,否則就忽略。
2、如果下載的過程中程序突然報錯退出了,由于下載文件較慢,為了節約時間,那么如何讓程序從報錯處繼續運行呢?這里可采用分層遞歸,一開始時先獲取網站的所有一級 url 鏈接,順序遍歷這些一級 url 鏈接,執行上述的 get_file(url) ,每訪問一次一級 url 就將其索引位置加1(索引位置默認為0,存儲在文件中或數據庫中),程序中斷后再運行時先讀取索引,然后從索引處開始執行即可。另外,每下載成功一個文件,就把對應的 url 也保存在文件中或數據庫中,如果一級 url 下的鏈接已經下載過文件,那么就不需要重新下載了。
感謝各位的閱讀!關于“如何使用Python自動下載網站所有文件”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





