溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了R語言歸一化處理的案例分析,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
歸一化就是要把你需要處理的數據經過處理后(通過某種算法)限制在你需要的一定范圍內。首先歸一化是為了后面數據處理的方便,其次是保正程序運行時收斂加快。
R語言中的歸一化函數:scale
數據歸一化包括數據的中心化和數據的標準化。
1. 數據的中心化
所謂數據的中心化是指數據集中的各項數據減去數據集的均值。
例如有數據集1, 2, 3, 6, 3,其均值為3,那么中心化之后的數據集為1-3,2-3,3-3,6-3,3-3,即:-2,-1,0,3,0
2. 數據的標準化
所謂數據的標準化是指中心化之后的數據在除以數據集的標準差,即數據集中的各項數據減去數據集的均值再除以數據集的標準差。
例如有數據集1, 2, 3, 6, 3,其均值為3,其標準差為1.87,那么標準化之后的數據集為(1-3)/1.87,(2-3)/1.87,(3-3)/1.87,(6-3)/1.87,(3-3)/1.87,即:-1.069,-0.535,0,1.604,0
數據中心化和標準化的意義是一樣的,為了消除量綱對數據結構的影響。在R語言中可以使用scale方法來對數據進行中心化和標準化。
scale函數是將一組數進行處理,默認情況下是將一組數的每個數都減去這組數的平均值后再除以這組數的標準差。
其中有兩個參數:
center=TRUE,默認的,是將一組數中每個數減去平均值,若為false,則不減平均值;
scale=TRUE,默認的,是將一組數中每個數除以標準差。
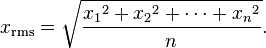
scale默認情況下:將一組數的每個數都減去這組數的平均值后再除以這組數的標準差。
> scale(ss) [,1] [1,] -1.3805850 [2,] -0.6371931 [3,] 0.1061988 [4,] 0.8495908 [5,] 1.5929827 [6,] 0.1061988 [7,] -0.6371931 attr(,"scaled:center") [1] 2.857143 attr(,"scaled:scale") [1] 1.345185
感謝你能夠認真閱讀完這篇文章,希望小編分享的“R語言歸一化處理的案例分析”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





