溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“如何解決使用openpyxl時遇到的問題”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“如何解決使用openpyxl時遇到的問題”吧!
1, xlwt最多只能寫入65536行數據, 所以在處理大批量數據的時候沒法使用
2, openpyxl 這個庫, 在使用的時候一直報錯, 看下面代碼
from openpyxl import Workbook
import datetime
wb = Workbook()
ws = wb.active
ws['A1'] = 42
ws.append([1,2,3])
ws['A2'] = datetime.datetime.now()
wb.save('test.xlsx')報錯信息如下
File "src\lxml\serializer.pxi", line 1652, in lxml.etree._IncrementalFileWriter.write TypeError: got invalid input value of type <class 'xml.etree.ElementTree.Element'>, expected string or Element
有沒有人知道是什么原因呀? 惆悵!!!
got invalid input value of type <class ‘xml.etree.ElementTree.Element'>, expected string or Element
出現這個問題好久了, 不知道怎么解決, 也去google 和baidu搜索, 一篇文章提到了可能是包沖突的問題, 抱著試一試的心態, 沒想到解決了
lxml 這個包和openpyxl 起沖突, 解決辦法, 先卸掉lxml
pip uninstall lxml
最后運行上面處理excel的代碼, 運行成功, 無錯誤!!! 困擾了我很長時間的問題得以解決!!!
由于lxml 包經常要用到, 所以每次卸載掉再安裝實在是麻煩, 所以我有下面的想法
例如下面的代碼, 從數據庫中取數據存入表格
import pymysql import pandas as pd from sqlalchemy import create_engine engine = create_engine("mysql+pymysql://user:password@ip:port/database",encoding='utf-8') sql = """SELECT catalog_1 as '目錄一',catalog_2 as '目錄二',catagory as '目錄三', region as '區域',year as '年份',data as '數據',unit as '單位' from table where catalog_1 = "農業" limit 100 """ df = pd.read_sql_query(sql, con=engine) # writer = pd.ExcelWriter(r'C:\Users\Administrator\Desktop\test.xlsx') # df.to_excel(writer) # writer.save()
這時候, 我們不選擇to_excel() 這個函數, 而是選擇使用to_csv() ; 即可避免openpyxl 和lxml 的沖突
df.to_csv(r'C:\Users\Administrator\Desktop\test.csv',index=False) # 經過驗證, 此種方法是行得通的
最后得到的csv 文件用Excel 可以直接打開, 也可以另存為*.xlsx文件
今天發現我使用的openpyxl版本是3.0.2, 卸載此版本, 安裝3.0.0版本
最新更新于2020-3-16, 經過測試, 此報錯解除!
補充:Python—使用Openpyxl的dataframe_to_rows的一個小坑
一般我們把dataframe直接寫到Excel文件,直接 df.to_excel即可。不過如果想把多個表格寫入同一個工作表呢,那就需要用openpyxl的dataframe_to_rows功能。
看下面一段代碼。
import pandas as pd
from openpyxl import Workbook
from openpyxl.utils.dataframe import dataframe_to_rows
df1=pd.DataFrame([[1,4],[2,5],[3,6]] ,index=['a','b','c'],columns=['a','b'])
df2=pd.DataFrame([[1,4],[2,5],[3,6],[7,8]] ,index=['d','e','f','g'],columns=['a','b'])
wb=Workbook()
ws=wb.active #打開工作表
#把df1寫入工作表
for row in dataframe_to_rows(df1):
ws.append(row)
#換行
ws.append([])
#把df2寫入工作表
for row in dataframe_to_rows(df2):
ws.append(row)
wb.save('text.xlsx')這段代碼就是把df1,df2都寫入到一個工作表,但一看結果,傻了,怎么標題行和內容之間多了空行啊
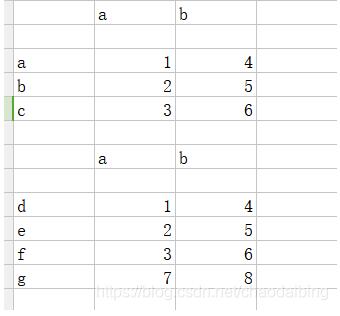
看看空行是如何產生的呢
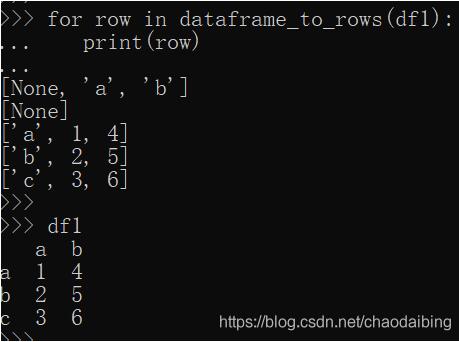
原來多了一個None啊,難怪是空行,目測None是index帶來的,那就把index去掉唄
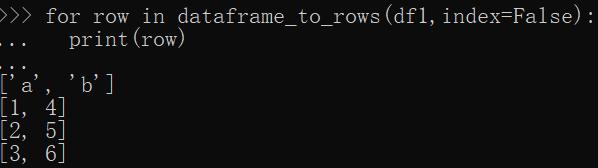
這回None是沒有了,但是index的內容也想要顯示,怎么辦呢,這么辦:
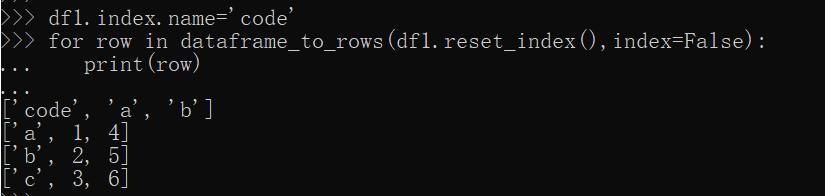
哈哈,這樣就完美了。這里reset_index的意思就是把index列,變成普通列,比如:
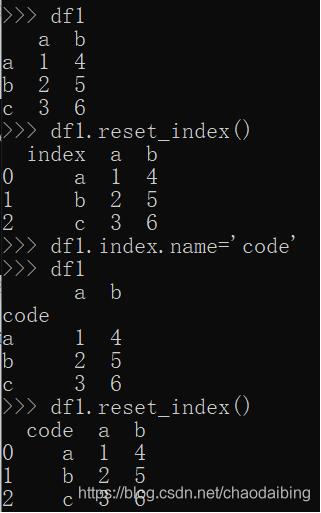
如上圖,如果直接reset_index,index列變成普通列,但是列頭自動變成了index,這可不好,所以先給index列賦值,也就是df1.index.name=‘code'
最后代碼如下
import pandas as pd
from openpyxl import Workbook
from openpyxl.utils.dataframe import dataframe_to_rows
df1=pd.DataFrame([[1,4],[2,5],[3,6]] ,index=['a','b','c'],columns=['a','b'])
df2=pd.DataFrame([[1,4],[2,5],[3,6],[7,8]] ,index=['d','e','f','g'],columns=['a','b'])
wb=Workbook()
ws=wb.active #打開工作表
df1.index.name='code1'
df2.index.name='code2'
#把df1寫入工作表
for row in dataframe_to_rows(df1.reset_index(),index=False):
ws.append(row)
#換行
ws.append([])
#把df2寫入工作表
for row in dataframe_to_rows(df2.reset_index(),index=False):
ws.append(row)
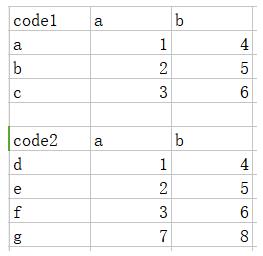
wb.save('text.xlsx')結果,哈哈,完美
到此,相信大家對“如何解決使用openpyxl時遇到的問題”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





