溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“如何理解Linux內核的文件”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
Linux文件預讀算法磁盤I/O性能的發展遠遠滯后于CPU和內存,因而成為現代計算機系統的一個主要瓶頸。預讀可以有效的減少磁盤的尋道次數和應用程序的I/O等待時間,是改進磁盤讀I/O性能的重要優化手段之一。本文作者是中國科學技術大學自動化系的博士生,他在1998年開始學習Linux,為了優化服務器的性能,他開始嘗試改進Linux kernel,并最終重寫了內核的文件預讀部分,這些改進被收錄到Linux Kernel 2.6.23及其后續版本中。
從寄存器、L1/L2高速緩存、內存、閃存,到磁盤/光盤/磁帶/存儲網絡,計算機的各級存儲器硬件組成了一個金字塔結構。越是底層存儲容量越大。然而訪問速度也越慢,具體表現為更小的帶寬和更大的延遲。因而這很自然的便成為一個金字塔形的逐層緩存結構。由此產生了三類基本的緩存管理和優化問題:
◆預取(prefetching)算法,從慢速存儲中加載數據到緩存;
◆替換(replacement)算法,從緩存中丟棄無用數據;
◆寫回(writeback)算法,把臟數據從緩存中保存到慢速存儲。
其中的預取算法,在磁盤這一層次尤為重要。磁盤的機械臂+旋轉盤片的數據定位與讀取方式,決定了它最突出的性能特點:擅長順序讀寫,不善于隨機I/O,I/O延遲非常大。由此而產生了兩個方面的預讀需求。
來自磁盤的需求
簡單的說,磁盤的一個典型I/O操作由兩個階段組成:
1.數據定位
平均定位時間主要由兩部分組成:平均尋道時間和平均轉動延遲。尋道時間的典型值是4.6ms。轉動延遲則取決于磁盤的轉速:普通7200RPM桌面硬盤的轉動延遲是4.2ms,而高端10000RPM的是3ms。這些數字多年來一直徘徊不前,大概今后也無法有大的改善了。在下文中,我們不妨使用 8ms作為典型定位時間。
2.數據傳輸
持續傳輸率主要取決于盤片的轉速(線速度)和存儲密度,最新的典型值為80MB/s。雖然磁盤轉速難以提高,但是存儲密度卻在逐年改善。巨磁阻、垂直磁記錄等一系列新技術的采用,不但大大提高了磁盤容量,也同時帶來了更高的持續傳輸率。
顯然,I/O的粒度越大,傳輸時間在總時間中的比重就會越大,因而磁盤利用率和吞吐量就會越大。簡單的估算結果如表1所示。如果進行大量4KB的隨機I/O,那么磁盤在99%以上的時間內都在忙著定位,單個磁盤的吞吐量不到500KB/s。但是當I/O大小達到1MB的時候,吞吐量可接近50MB /s。由此可見,采用更大的I/O粒度,可以把磁盤的利用效率和吞吐量提高整整100倍。因而必須盡一切可能避免小尺寸I/O,這正是預讀算法所要做的。
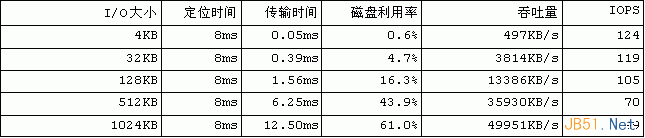
表1隨機讀大小與磁盤性能的關系
來自程序的需求
應用程序處理數據的一個典型流程是這樣的:while(!done) { read(); compute(); }。假設這個循環要重復5次,總共處理5批數據,則程序運行的時序圖可能如圖1所示。

圖1典型的I/O時序圖
不難看出,磁盤和CPU是在交替忙碌:當進行磁盤I/O的時候,CPU在等待;當CPU在計算和處理數據時,磁盤是空閑的。那么是不是可以讓兩者流水線作業,以便加快程序的執行速度?預讀可以幫助達成這一目標。基本的方法是,當CPU開始處理第1批數據的時候,由內核的預讀機制預加載下一批數據。這時候的預讀是在后臺異步進行的,如圖2所示。

圖2預讀的流水線作業
注意,在這里我們并沒有改變應用程序的行為:程序的下一個讀請求仍然是在處理完當前的數據之后才發出的。只是這時候的被請求的數據可能已經在內核緩存中了,無須等待,直接就能復制過來用。在這里,異步預讀的功能是對上層應用程序“隱藏”磁盤I/O的大延遲。雖然延遲事實上仍然存在,但是應用程序看不到了,因而運行的更流暢。
預讀的概念
預取算法的涵義和應用非常廣泛。它存在于CPU、硬盤、內核、應用程序以及網絡的各個層次。預取有兩種方案:啟發性的(heuristic prefetching)和知情的(informed prefetching)。前者自動自發的進行預讀決策,對上層應用是透明的,但是對算法的要求較高,存在命中率的問題;后者則簡單的提供API接口,而由上層程序給予明確的預讀指示。在磁盤這個層次,Linux為我們提供了三個API接口:posix_fadvise(2), readahead(2), madvise(2)。
不過真正使用上述預讀API的應用程序并不多見:因為一般情況下,內核中的啟發式算法工作的很好。預讀(readahead)算法預測即將訪問的頁面,并提前把它們批量的讀入緩存。
它的主要功能和任務可以用三個關鍵詞來概括:
◆批量,也就是把小I/O聚集為大I/O,以改善磁盤的利用率,提升系統的吞吐量。
◆提前,也就是對應用程序隱藏磁盤的I/O延遲,以加快程序運行。
◆ 預測,這是預讀算法的核心任務。前兩個功能的達成都有賴于準確的預測能力。當前包括Linux、FreeBSD和Solaris等主流操作系統都遵循了一個簡單有效的原則:把讀模式分為隨機讀和順序讀兩大類,并只對順序讀進行預讀。這一原則相對保守,但是可以保證很高的預讀命中率,同時有效率/覆蓋率也很好。因為順序讀是最簡單而普遍的,而隨機讀在內核來說也確實是難以預測的。
Linux的預讀架構
Linux內核的一大特色就是支持最多的文件系統,并擁有一個虛擬文件系統(VFS)層。早在2002年,也就是2.5內核的開發過程中,Andrew Morton在VFS層引入了文件預讀的基本框架,以統一支持各個文件系統。如圖所示,Linux內核會將它最近訪問過的文件頁面緩存在內存中一段時間,這個文件緩存被稱為pagecache。如圖3所示。一般的read()操作發生在應用程序提供的緩沖區與pagecache之間。而預讀算法則負責填充這個pagecache。應用程序的讀緩存一般都比較小,比如文件拷貝命令cp的讀寫粒度就是4KB;內核的預讀算法則會以它認為更合適的大小進行預讀 I/O,比比如16-128KB。
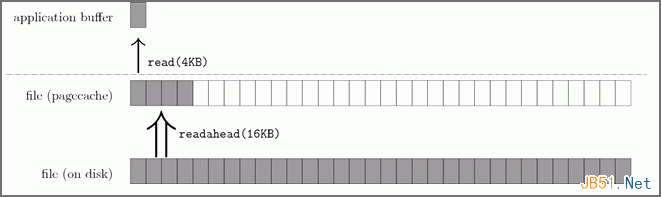
圖3以pagecache為中心的讀和預讀
大約一年之后,Linus Torvalds把mmap缺頁I/O的預取算法單獨列出,從而形成了read-around/read-ahead兩個獨立算法(圖4)。read- around算法適用于那些以mmap方式訪問的程序代碼和數據,它們具有很強的局域性(locality of reference)特征。當有缺頁事件發生時,它以當前頁面為中心,往前往后預取共計128KB頁面。而readahead算法主要針對read()系統調用,它們一般都具有很好的順序特性。但是隨機和非典型的讀取模式也大量存在,因而readahead算法必須具有很好的智能和適應性。
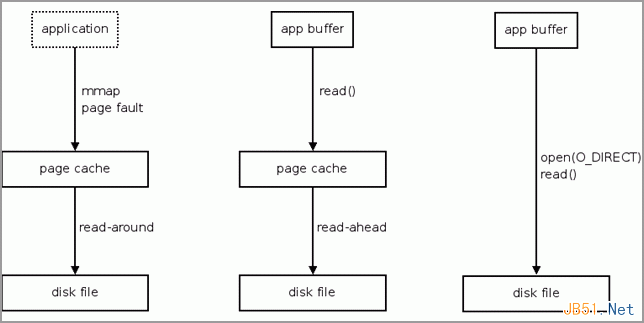
圖4 Linux中的read-around, read-ahead和direct read
又過了一年,通過Steven Pratt、Ram Pai等人的大量工作,readahead算法進一步完善。其中最重要的一點是實現了對隨機讀的完好支持。隨機讀在數據庫應用中處于非常突出的地位。在此之前,預讀算法以離散的讀頁面位置作為輸入,一個多頁面的隨機讀會觸發“順序預讀”。這導致了預讀I/O數的增加和命中率的下降。改進后的算法通過監控所有完整的read()調用,同時得到讀請求的頁面偏移量和數量,因而能夠更好的區分順序讀和隨機讀。
預讀算法概要
這一節以linux 2.6.22為例,來剖析預讀算法的幾個要點。
1.順序性檢測
為了保證預讀命中率,Linux只對順序讀(sequential read)進行預讀。內核通過驗證如下兩個條件來判定一個read()是否順序讀:
◆這是文件被打開后的第一次讀,并且讀的是文件首部;
◆當前的讀請求與前一(記錄的)讀請求在文件內的位置是連續的。
如果不滿足上述順序性條件,就判定為隨機讀。任何一個隨機讀都將終止當前的順序序列,從而終止預讀行為(而不是縮減預讀大小)。注意這里的空間順序性說的是文件內的偏移量,而不是指物理磁盤扇區的連續性。在這里Linux作了一種簡化,它行之有效的基本前提是文件在磁盤上是基本連續存儲的,沒有嚴重的碎片化。
2.流水線預讀
當程序在處理一批數據時,我們希望內核能在后臺把下一批數據事先準備好,以便CPU和硬盤能流水線作業。Linux用兩個預讀窗口來跟蹤當前順序流的預讀狀態:current窗口和ahead窗口。其中的ahead窗口便是為流水線準備的:當應用程序工作在current窗口時,內核可能正在 ahead窗口進行異步預讀;一旦程序進入當前的ahead窗口,內核就會立即往前推進兩個窗口,并在新的ahead窗口中啟動預讀I/O。
3.預讀的大小
當確定了要進行順序預讀(sequential readahead)時,就需要決定合適的預讀大小。預讀粒度太小的話,達不到應有的性能提升效果;預讀太多,又有可能載入太多程序不需要的頁面,造成資源浪費。為此,Linux采用了一個快速的窗口擴張過程:
◆首次預讀:readahead_size = read_size * 2; // or *4
預讀窗口的初始值是讀大小的二到四倍。這意味著在您的程序中使用較大的讀粒度(比如32KB)可以稍稍提升I/O效率。
◆后續預讀:readahead_size *= 2;
后續的預讀窗口將逐次倍增,直到達到系統設定的最大預讀大小,其缺省值是128KB。這個缺省值已經沿用至少五年了,在當前更快的硬盤和大容量內存面前,顯得太過保守。比如西部數據公司近年推出的WD Raptor 猛禽 10000RPM SATA 硬盤,在進行128KB隨機讀的時候,只能達到16%的磁盤利用率(圖5)。所以如果您運行著Linux服務器或者桌面系統,不妨試著用如下命令把最大預讀值提升到1MB看看,或許會有驚喜:
# blockdev–setra 2048 /dev/sda
當然預讀大小不是越大越好,在很多情況下,也需要同時考慮I/O延遲問題。
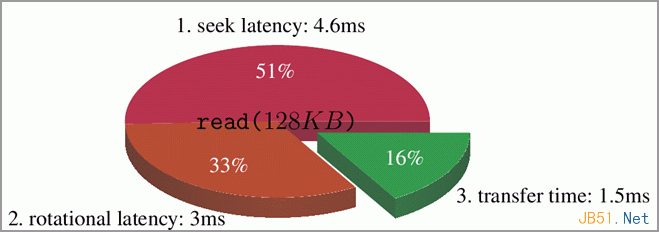
圖5 128KB I/O的數據定位時間和傳輸時間比重
重新發現順序讀
上一節我們解決了是否/何時進行預讀,以及讀多少的基本問題。由于現實的復雜性,上述算法并不總能奏效,即使是對于順序讀的情況。例如最近發現的重試讀(retried read)的問題。
重試讀在異步I/O和非阻塞I/O中比較常見。它們允許內核中斷一個讀請求。這樣一來,程序提交的后續讀請求看起來會與前面被中斷的讀請求相重疊。如圖6所示。

圖6重試讀(retried reads)
Linux 2.6.22無法理解這種情況,于是把它誤判為隨機讀。這里的問題在于“讀請求”并不代表讀取操作實實在在的發生了。預讀的決策依據應為后者而非前者。最新發布的2.6.23對此作了改進。新的算法以當前讀取的頁面狀態為主要決策依據,并為此新增了一個頁面標志位:PG_readahead,它是“請作異步預讀”的一個提示。在每次進行新預讀時,算法都會選擇其中的一個新頁面并標記之。預讀規則相應的改為:
◆當讀到缺失頁面(missing page),進行同步預讀;
◆當讀到預讀頁面(PG_readahead page),進行異步預讀。
這樣一來,ahead預讀窗口就不需要了:它實際上是把預讀大小和提前量兩者作了不必要的綁定。新的標記機制允許我們靈活而精確地控制預讀的提前量,這有助于將來引入對筆記本省電模式的支持。

圖7 Linux 2.6.23預讀算法的工作動態
另一個越來越突出的問題來自于交織讀(interleaved read)。這一讀模式常見于多媒體/多線程應用。當在一個打開的文件中同時進行多個流(stream)的讀取時,它們的讀取請求會相互交織在一起,在內核看來好像是很多的隨機讀。更嚴重的是,目前的內核只能在一個打開的文件描述符中跟蹤一個流的預讀狀態。因而即使內核對兩個流進行預讀,它們會相互覆蓋和破壞對方的預讀狀態信息。對此,我們將在即將發布的2.6.24中作一定改進,利用頁面和pagecache所提供的狀態信息來支持多個流的交織讀。
預讀建議

“如何理解Linux內核的文件”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





