溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Linux系統日志分析基本教程”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
Linux 系統日志
許多有價值的日志文件都是由 Linux 自動地為你創建的。你可以在 /var/log 目錄中找到它們。下面是在一個典型的 Ubuntu 系統中這個目錄的樣子: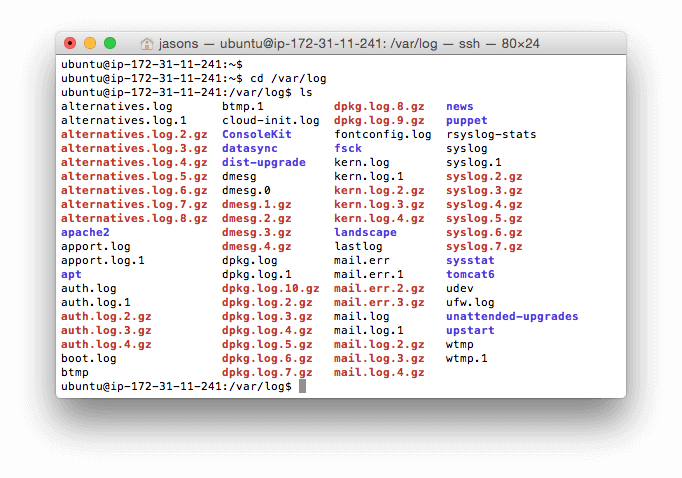
一些最為重要的 Linux 系統日志包括:
/var/log/syslog 或 /var/log/messages 存儲所有的全局系統活動數據,包括開機信息。基于 Debian 的系統如 Ubuntu 在 /var/log/syslog 中存儲它們,而基于 RedHat 的系統如 RHEL 或 CentOS 則在 /var/log/messages 中存儲它們。
/var/log/auth.log 或 /var/log/secure 存儲來自可插拔認證模塊(PAM)的日志,包括成功的登錄,失敗的登錄嘗試和認證方式。Ubuntu 和 Debian 在 /var/log/auth.log 中存儲認證信息,而 RedHat 和 CentOS 則在 /var/log/secure 中存儲該信息。
/var/log/kern 存儲內核的錯誤和警告數據,這對于排除與定制內核相關的故障尤為實用。
/var/log/cron 存儲有關 cron 作業的信息。使用這個數據來確保你的 cron 作業正成功地運行著。
Digital Ocean 有一個關于這些文件的完整教程,介紹了 rsyslog 如何在常見的發行版本如 RedHat 和 CentOS 中創建它們。
應用程序也會在這個目錄中寫入日志文件。例如像 Apache,Nginx,MySQL 等常見的服務器程序可以在這個目錄中寫入日志文件。其中一些日志文件由應用程序自己創建,其他的則通過 syslog (具體見下文)來創建。
什么是 Syslog?
Linux 系統日志文件是如何創建的呢?答案是通過 syslog 守護程序,它在 syslog 套接字 /dev/log 上監聽日志信息,然后將它們寫入適當的日志文件中。
單詞“syslog” 代表幾個意思,并經常被用來簡稱如下的幾個名稱之一:
Syslog 守護進程 — 一個用來接收、處理和發送 syslog 信息的程序。它可以遠程發送 syslog 到一個集中式的服務器或寫入到一個本地文件。常見的例子包括 rsyslogd 和 syslog-ng。在這種使用方式中,人們常說“發送到 syslog”。
Syslog 協議 — 一個指定日志如何通過網絡來傳送的傳輸協議和一個針對 syslog 信息(具體見下文) 的數據格式的定義。它在 RFC-5424 中被正式定義。對于文本日志,標準的端口是 514,對于加密日志,端口是 6514。在這種使用方式中,人們常說“通過 syslog 傳送”。
Syslog 信息 — syslog 格式的日志信息或事件,它包括一個帶有幾個標準字段的消息頭。在這種使用方式中,人們常說“發送 syslog”。
Syslog 信息或事件包括一個帶有幾個標準字段的消息頭,可以使分析和路由更方便。它們包括時間戳、應用程序的名稱、在系統中信息來源的分類或位置、以及事件的優先級。
下面展示的是一個包含 syslog 消息頭的日志信息,它來自于控制著到該系統的遠程登錄的 sshd 守護進程,這個信息描述的是一次失敗的登錄嘗試:
<34>1 2003-10-11T22:14:15.003Z server1.com sshd - - pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=10.0.2.2
Syslog 格式和字段
每條 syslog 信息包含一個帶有字段的信息頭,這些字段是結構化的數據,使得分析和路由事件更加容易。下面是我們使用的用來產生上面的 syslog 例子的格式,你可以將每個值匹配到一個特定的字段的名稱上。
代碼如下:
<%pri%>%protocol-version% %timestamp:::date-rfc3339% %HOSTNAME% %app-name% %procid% %msgid% %msg%n
下面,你將看到一些在查找或排錯時最常使用的 syslog 字段:
時間戳
時間戳 (上面的例子為 2003-10-11T22:14:15.003Z) 暗示了在系統中發送該信息的時間和日期。這個時間在另一系統上接收該信息時可能會有所不同。上面例子中的時間戳可以分解為:
2003-10-11 年,月,日。
T 為時間戳的必需元素,它將日期和時間分隔開。
22:14:15.003 是 24 小時制的時間,包括進入下一秒的毫秒數(003)。
Z 是一個可選元素,指的是 UTC 時間,除了 Z,這個例子還可以包括一個偏移量,例如 -08:00,這意味著時間從 UTC 偏移 8 小時,即 PST 時間。
主機名
主機名 字段(在上面的例子中對應 server1.com) 指的是主機的名稱或發送信息的系統.
應用名
應用名 字段(在上面的例子中對應 sshd:auth) 指的是發送信息的程序的名稱.
優先級
優先級字段或縮寫為 pri (在上面的例子中對應 ) 告訴我們這個事件有多緊急或多嚴峻。它由兩個數字字段組成:設備字段和緊急性字段。緊急性字段從代表 debug 類事件的數字 7 一直到代表緊急事件的數字 0 。設備字段描述了哪個進程創建了該事件。它從代表內核信息的數字 0 到代表本地應用使用的 23 。
Pri 有兩種輸出方式。第一種是以一個單獨的數字表示,可以這樣計算:先用設備字段的值乘以 8,再加上緊急性字段的值:(設備字段)(8) + (緊急性字段)。第二種是 pri 文本,將以“設備字段.緊急性字段” 的字符串格式輸出。后一種格式更方便閱讀和搜索,但占據更多的存儲空間。
分析 Linux 日志
日志中有大量的信息需要你處理,盡管有時候想要提取并非想象中的容易。在這篇文章中我們會介紹一些你現在就能做的基本日志分析例子(只需要搜索即可)。我們還將涉及一些更高級的分析,但這些需要你前期努力做出適當的設置,后期就能節省很多時間。對數據進行高級分析的例子包括生成匯總計數、對有效值進行過濾,等等。
我們首先會向你展示如何在命令行中使用多個不同的工具,然后展示了一個日志管理工具如何能自動完成大部分繁重工作從而使得日志分析變得簡單。
用 Grep 搜索
搜索文本是查找信息最基本的方式。搜索文本最常用的工具是 grep。這個命令行工具在大部分 Linux 發行版中都有,它允許你用正則表達式搜索日志。正則表達式是一種用特殊的語言寫的、能識別匹配文本的模式。最簡單的模式就是用引號把你想要查找的字符串括起來。
正則表達式
這是一個在 Ubuntu 系統的認證日志中查找 “user hoover” 的例子:
代碼如下:
$ grep "user hoover" /var/log/auth.log
Accepted password for hoover from 10.0.2.2 port 4792 ssh3
pam_unix(sshd:session): session opened for user hoover by (uid=0)
pam_unix(sshd:session): session closed for user hoover
構建精確的正則表達式可能很難。例如,如果我們想要搜索一個類似端口 “4792” 的數字,它可能也會匹配時間戳、URL 以及其它不需要的數據。Ubuntu 中下面的例子,它匹配了一個我們不想要的 Apache 日志。
代碼如下:
$ grep "4792" /var/log/auth.log
Accepted password for hoover from 10.0.2.2 port 4792 ssh3
74.91.21.46 - - [31/Mar/2015:19:44:32 +0000] "GET /scripts/samples/search?q=4972 HTTP/1.0" 404 545 "-" "-”
環繞搜索
另一個有用的小技巧是你可以用 grep 做環繞搜索。這會向你展示一個匹配前面或后面幾行是什么。它能幫助你調試導致錯誤或問題的東西。B 選項展示前面幾行,A 選項展示后面幾行。舉個例子,我們知道當一個人以管理員員身份登錄失敗時,同時他們的 IP 也沒有反向解析,也就意味著他們可能沒有有效的域名。這非常可疑!
代碼如下:
$ grep -B 3 -A 2 'Invalid user' /var/log/auth.log
Apr 28 17:06:20 ip-172-31-11-241 sshd[12545]: reverse mapping checking getaddrinfo for 216-19-2-8.commspeed.net [216.19.2.8] failed - POSSIBLE BREAK-IN ATTEMPT!
Apr 28 17:06:20 ip-172-31-11-241 sshd[12545]: Received disconnect from 216.19.2.8: 11: Bye Bye [preauth]
Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: Invalid user admin from 216.19.2.8
Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: input_userauth_request: invalid user admin [preauth]
Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: Received disconnect from 216.19.2.8: 11: Bye Bye [preauth]
Tail
你也可以把 grep 和 tail 結合使用來獲取一個文件的最后幾行,或者跟蹤日志并實時打印。這在你做交互式更改的時候非常有用,例如啟動服務器或者測試代碼更改。
代碼如下:
$ tail -f /var/log/auth.log | grep 'Invalid user'
Apr 30 19:49:48 ip-172-31-11-241 sshd[6512]: Invalid user ubnt from 219.140.64.136
Apr 30 19:49:49 ip-172-31-11-241 sshd[6514]: Invalid user admin from 219.140.64.136
關于 grep 和正則表達式的詳細介紹并不在本指南的范圍,但 Ryan’s Tutorials 有更深入的介紹。
日志管理系統有更高的性能和更強大的搜索能力。它們通常會索引數據并進行并行查詢,因此你可以很快的在幾秒內就能搜索 GB 或 TB 的日志。相比之下,grep 就需要幾分鐘,在極端情況下可能甚至幾小時。日志管理系統也使用類似 Lucene 的查詢語言,它提供更簡單的語法來檢索數字、域以及其它。
用 Cut、 AWK、 和 Grok 解析
Linux 提供了多個命令行工具用于文本解析和分析。當你想要快速解析少量數據時非常有用,但處理大量數據時可能需要很長時間。
Cut
cut 命令允許你從有分隔符的日志解析字段。分隔符是指能分開字段或鍵值對的等號或逗號等。
假設我們想從下面的日志中解析出用戶:
代碼如下:
pam_unix(su:auth): authentication failure; logname=hoover uid=1000 euid=0 tty=/dev/pts/0 ruser=hoover rhost= user=root
我們可以像下面這樣用 cut 命令獲取用等號分割后的第八個字段的文本。這是一個 Ubuntu 系統上的例子:
代碼如下:
$ grep "authentication failure" /var/log/auth.log | cut -d '=' -f 8
root
hoover
root
nagios
nagios
AWK
另外,你也可以使用 awk,它能提供更強大的解析字段功能。它提供了一個腳本語言,你可以過濾出幾乎任何不相干的東西。
例如,假設在 Ubuntu 系統中我們有下面的一行日志,我們想要提取登錄失敗的用戶名稱:
代碼如下:
Mar 24 08:28:18 ip-172-31-11-241 sshd[32701]: input_userauth_request: invalid user guest [preauth]
你可以像下面這樣使用 awk 命令。首先,用一個正則表達式 /sshd.*invalid user/ 來匹配 sshd invalid user 行。然后用 { print $9 } 根據默認的分隔符空格打印第九個字段。這樣就輸出了用戶名。
代碼如下:
$ awk '/sshd.*invalid user/ { print $9 }' /var/log/auth.log
guest
admin
info
test
ubnt
你可以在 Awk 用戶指南 中閱讀更多關于如何使用正則表達式和輸出字段的信息。
日志管理系統
日志管理系統使得解析變得更加簡單,使用戶能快速的分析很多的日志文件。他們能自動解析標準的日志格式,比如常見的 Linux 日志和 Web 服務器日志。這能節省很多時間,因為當處理系統問題的時候你不需要考慮自己寫解析邏輯。
下面是一個 sshd 日志消息的例子,解析出了每個 remoteHost 和 user。這是 Loggly 中的一張截圖,它是一個基于云的日志管理服務。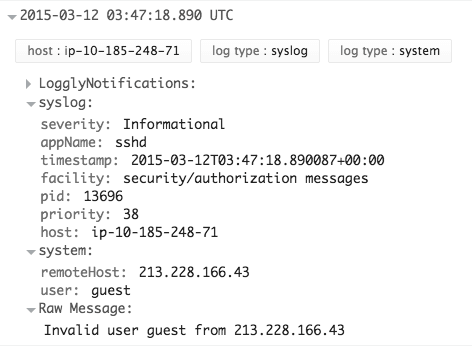
你也可以對非標準格式自定義解析。一個常用的工具是 Grok,它用一個常見正則表達式庫,可以解析原始文本為結構化 JSON。下面是一個 Grok 在 Logstash 中解析內核日志文件的事例配置:
代碼如下:
filter{
grok {
match => {"message" => "%{CISCOTIMESTAMP:timestamp} %{HOST:host} %{WORD:program}%{NOTSPACE} %{NOTSPACE}%{NUMBER:duration}%{NOTSPACE} %{GREEDYDATA:kernel_logs}"
}
}
下圖是 Grok 解析后輸出的結果:
用 Rsyslog 和 AWK 過濾
過濾使得你能檢索一個特定的字段值而不是進行全文檢索。這使你的日志分析更加準確,因為它會忽略來自其它部分日志信息不需要的匹配。為了對一個字段值進行搜索,你首先需要解析日志或者至少有對事件結構進行檢索的方式。
如何對應用進行過濾
通常,你可能只想看一個應用的日志。如果你的應用把記錄都保存到一個文件中就會很容易。如果你需要在一個聚集或集中式日志中過濾一個應用就會比較復雜。下面有幾種方法來實現:
用 rsyslog 守護進程解析和過濾日志。下面的例子將 sshd 應用的日志寫入一個名為 sshd-message 的文件,然后丟棄事件以便它不會在其它地方重復出現。你可以將它添加到你的 rsyslog.conf 文件中測試這個例子。
代碼如下:
:programname, isequal, “sshd” /var/log/sshd-messages
&~
用類似 awk 的命令行工具提取特定字段的值,例如 sshd 用戶名。下面是 Ubuntu 系統中的一個例子。
代碼如下:
$ awk '/sshd.*invalid user/ { print $9 }' /var/log/auth.log
guest
admin
info
test
ubnt
用日志管理系統自動解析日志,然后在需要的應用名稱上點擊過濾。下面是在 Loggly 日志管理服務中提取 syslog 域的截圖。我們對應用名稱 “sshd” 進行過濾,如維恩圖圖標所示。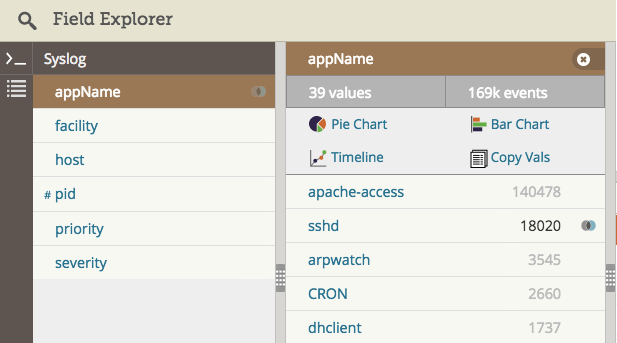
如何過濾錯誤
一個人最希望看到日志中的錯誤。不幸的是,默認的 syslog 配置不直接輸出錯誤的嚴重性,也就使得難以過濾它們。
這里有兩個解決該問題的方法。首先,你可以修改你的 rsyslog 配置,在日志文件中輸出錯誤的嚴重性,使得便于查看和檢索。在你的 rsyslog 配置中你可以用 pri-text 添加一個 模板,像下面這樣:
代碼如下:
"<%pri-text%> : %timegenerated%,%HOSTNAME%,%syslogtag%,%msg%n"
這個例子會按照下面的格式輸出。你可以看到該信息中指示錯誤的 err。
代碼如下:
<authpriv.err> : Mar 11 18:18:00,hoover-VirtualBox,su[5026]:, pam_authenticate: Authentication failure
你可以用 awk 或者 grep 檢索錯誤信息。在 Ubuntu 中,對這個例子,我們可以用一些語法特征,例如 . 和 >,它們只會匹配這個域。
代碼如下:
$ grep '.err>' /var/log/auth.log
<authpriv.err> : Mar 11 18:18:00,hoover-VirtualBox,su[5026]:, pam_authenticate: Authentication failure
你的第二個選擇是使用日志管理系統。好的日志管理系統能自動解析 syslog 消息并抽取錯誤域。它們也允許你用簡單的點擊過濾日志消息中的特定錯誤。
下面是 Loggly 中一個截圖,顯示了高亮錯誤嚴重性的 syslog 域,表示我們正在過濾錯誤: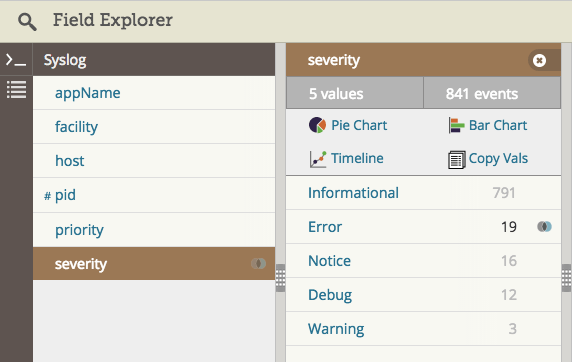
“Linux系統日志分析基本教程”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





