溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
使用celery怎么動態設置定時任務?很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
celery的beat運行過程。
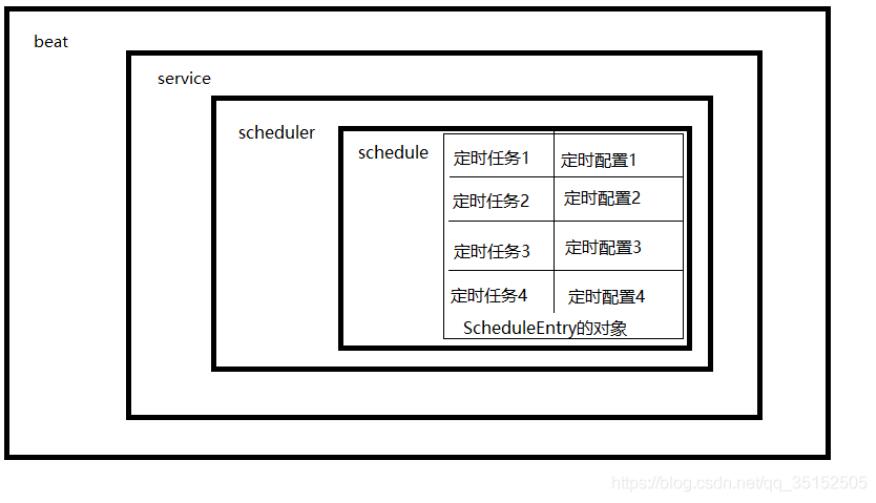
上圖是beat的主要組成結構,beat中包含了一個service對象,service中包含了一個scheduler對象,scheduler中包含了一個schedule字典,schedule中key對應的的value才是真正的定時任務,是整個beat中最小的單元。
首先分別介紹一下各個對象和它們運行的過程,beat是celery.apps.beat.Beat類創建的對象,調用beat.run()方法就可以啟動beat,下面是beat.run()方法的源碼。
def run(self):
print(str(self.colored.cyan(
'celery beat v{0} is starting.'.format(VERSION_BANNER))))
self.init_loader()
self.set_process_title()
self.start_scheduler()重點是在run()方法里調用了start_scheduler()方法,而start_scheduler()方法本質上是創建了一個service對象(celery.beat.Service類),并調用service.start()方法,下面是beat.start_scheduler()方法的源碼。
def start_scheduler(self):
if self.pidfile:
platforms.create_pidlock(self.pidfile)
service = self.Service(
app=self.app,
max_interval=self.max_interval,
scheduler_cls=self.scheduler_cls,
schedule_filename=self.schedule,
)
print(self.banner(service))
self.setup_logging()
if self.socket_timeout:
logger.debug('Setting default socket timeout to %r',
self.socket_timeout)
socket.setdefaulttimeout(self.socket_timeout)
try:
self.install_sync_handler(service)
service.start()
except Exception as exc:
logger.critical('beat raised exception %s: %r',
exc.__class__, exc,
exc_info=True)
raise調用了service.start()之后,會進入一個死循環,先使用self.scheduler.tick()獲取下一個任務a的定時點到現在時間的間隔,然后進入睡眠,睡眠結束之后判斷如果self.scheduler里的下一個任務a可以執行,就立即執行,并獲取self.scheduler里的下下一個任務b的定時點到現在時間的間隔,進入下一次循環。下面是service.start()的源碼。
def start(self, embedded_process=False):
info('beat: Starting...')
debug('beat: Ticking with max interval->%s',
humanize_seconds(self.scheduler.max_interval))
signals.beat_init.send(sender=self)
if embedded_process:
signals.beat_embedded_init.send(sender=self)
platforms.set_process_title('celery beat')
try:
while not self._is_shutdown.is_set():
interval = self.scheduler.tick()
if interval and interval > 0.0:
debug('beat: Waking up %s.',
humanize_seconds(interval, prefix='in '))
time.sleep(interval)
if self.scheduler.should_sync():
self.scheduler._do_sync()
except (KeyboardInterrupt, SystemExit):
self._is_shutdown.set()
finally:
self.sync()service.scheduler默認是celery.beat.PersistentScheduler類的實例對象,而celery.beat.PersistentScheduler其實是celery.beat.Scheduler的子類,所以scheduler.schedule是celery.beat.Scheduler類中的字典,保存的是celery.beat.ScheduleEntry類型的對象。ScheduleEntry的實例對象保存了定時任務的名稱、參數、定時信息、過期時間等信息。celery.beat.Scheduler類實現了對schedule的更新方法即update_from_dict(self, dict_)方法。下面是update_from_dict(self, dict_)方法的源碼。
def _maybe_entry(self, name, entry):
if isinstance(entry, self.Entry):
entry.app = self.app
return entry
return self.Entry(**dict(entry, name=name, app=self.app))
def update_from_dict(self, dict_):
self.schedule.update({
name: self._maybe_entry(name, entry)
for name, entry in items(dict_)
})可以看到update_from_dict(self, dict_)方法實際上是向schedule中更新了self.Entry的實例對象,而self.Entry從celery.beat.Scheduler的源碼知道是celery.beat.ScheduleEntry。
到這里整個流程就粗略的介紹完了,基本過程是這個樣子。
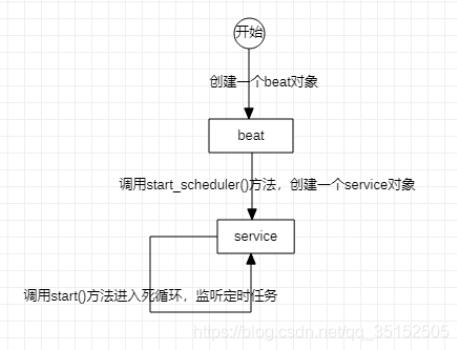
但是從前面start_scheduler()的源碼可以看到,beat在內部創建一個service之后,就直接進入死循環了,所以從外面無法拿到service對象,就不能對service里的scheduler對象操作,就不能對scheduler的schedule字典操作,所以就無法在beat運行的過程中動態添加定時任務。
前面介紹完原理,現在來講一下解決思路。主要思路就是讓start_scheduler方法中創建的service暴露出來。所以就想到手寫一個類去繼承Beat,重寫start_scheduler()方法。
import socket
from celery import platforms
from celery.apps.beat import Beat
class MyBeat(Beat):
'''
繼承Beat 添加一個獲取service的方法
'''
def start_scheduler(self):
if self.pidfile:
platforms.create_pidlock(self.pidfile)
# 修改了獲取service的方式
service = self.get_service()
print(self.banner(service))
self.setup_logging()
if self.socket_timeout:
logger.debug('Setting default socket timeout to %r',
self.socket_timeout)
socket.setdefaulttimeout(self.socket_timeout)
try:
self.install_sync_handler(service)
service.start()
except Exception as exc:
logger.critical('beat raised exception %s: %r',
exc.__class__, exc,
exc_info=True)
raise
def get_service(self):
'''
這個是自定義的 目的是為了把service暴露出來,方便對service的scheduler操作,因為定時任務信息都存放在service.scheduler里
:return:
'''
service = getattr(self, "service", None)
if service is None:
service = self.Service(
app=self.app,
max_interval=self.max_interval,
scheduler_cls=self.scheduler_cls,
schedule_filename=self.schedule,
)
setattr(self, "service", service)
return self.service在MyBeat類中添加一個get_service()方法,如果beat沒有servic對象就創建一個,如果有就直接返回,方便對service的scheduler操作。
然后在此基礎上實現對定時任務的增刪改查操作。
def add_cron_task(task_name: str, cron_task: str, minute='*', hour='*', day_of_week='*', day_of_month='*',
month_of_year='*', **kwargs):
'''
創建或更新定時任務
:param task_name: 定時任務名稱
:param cron_task: task名稱
:param minute: 以下是時間
:param hour:
:param day_of_week:
:param day_of_month:
:param month_of_year:
:param kwargs:
:return:
'''
service = beat.get_service()
scheduler = service.scheduler
entries = dict()
entries[task_name] = {
'task': cron_task,
'schedule': crontab(minute=minute, hour=hour, day_of_week=day_of_week, day_of_month=day_of_month,
month_of_year=month_of_year, **kwargs),
'options': {'expires': 3600}}
scheduler.update_from_dict(entries)
def del_cron_task(task_name: str):
'''
刪除定時任務
:param task_name:
:return:
'''
service = beat.get_service()
scheduler = service.scheduler
if scheduler.schedule.get(task_name, None) is not None:
del scheduler.schedule[task_name]
def get_cron_task():
'''
獲取當前所有定時任務的配置
:return:
'''
service = beat.get_service()
scheduler = service.scheduler
ret = [{k: {"task": v.task, "crontab": v.schedule}} for k, v in scheduler.schedule.items()]
return ret但是僅僅是這樣還不能解決問題,從前面的serive.start()的源碼看到,beat啟動后會進入一個死循環,如果直接在主線程啟動beat,必然會阻塞在死循環中,所以需要為beat創建一個子線程,這樣才影響主線程的其他操作。
flag = False beat = MyBeat(max_interval=10, app=celery_app, socket_timeout=30, pidfile=None, no_color=None, loglevel='INFO', logfile=None, schedule=None, scheduler='celery.beat.PersistentScheduler', scheduler_cls=None, # XXX use scheduler redirect_stdouts=None, redirect_stdouts_level=None) # 設置主動啟動beat是為了避免使用celery -A celery_demo worker 命令重復啟動worker def run(): ''' 啟動Beat :return: ''' beat.run() def new_thread(): ''' 創建一個線程啟動Beat 最多只能創建一個 :return: ''' global flag if not flag: t = threading.Thread(target=run, daemon=True) t.start() # 啟動成功2s后才能操作定時任務 否則可能會報錯 time.sleep(2) flag = True
可能看到上面的代碼有人會想,為什么不在主程序加載完成就啟動為beat創建一個子線程,還非要寫個函數等待主動調用?這是因為例如在使用django+celery組合時,一般啟動django和啟動celery woker是兩個獨立的進程,如果讓django在加載代碼的時候自動啟動beat的子線程,那么在使用celery -A demo_name worker 啟動celery時,會重新加載一邊django的代碼,因為celery需要掃描每個app下的tasks.py文件,加載異步任務函數,這時啟動celery woker就會也啟動一個beat子線程,可能會造成定時任務重復執行的情況。所以在這里設置成主動開啟beat子線程,目的就是為了celery worker啟動不重復創建beat線程。
完整的代碼如下:
import socket
import time
import threading
from celery import platforms
from celery.schedules import crontab
from celery.apps.beat import Beat
from celery.utils.log import get_logger
from celery_demo import celery_app
logger = get_logger('celery.beat')
flag = False
class MyBeat(Beat):
'''
繼承Beat 添加一個獲取service的方法
'''
def start_scheduler(self):
if self.pidfile:
platforms.create_pidlock(self.pidfile)
# 修改了獲取service的方式
service = self.get_service()
print(self.banner(service))
self.setup_logging()
if self.socket_timeout:
logger.debug('Setting default socket timeout to %r',
self.socket_timeout)
socket.setdefaulttimeout(self.socket_timeout)
try:
self.install_sync_handler(service)
service.start()
except Exception as exc:
logger.critical('beat raised exception %s: %r',
exc.__class__, exc,
exc_info=True)
raise
def get_service(self):
'''
這個是自定義的 目的是為了把service暴露出來,方便對service的scheduler操作,因為定時任務信息都存放在service.scheduler里
:return:
'''
service = getattr(self, "service", None)
if service is None:
service = self.Service(
app=self.app,
max_interval=self.max_interval,
scheduler_cls=self.scheduler_cls,
schedule_filename=self.schedule,
)
setattr(self, "service", service)
return self.service
beat = MyBeat(max_interval=10, app=celery_app, socket_timeout=30, pidfile=None, no_color=None,
loglevel='INFO', logfile=None, schedule=None, scheduler='celery.beat.PersistentScheduler',
scheduler_cls=None, # XXX use scheduler
redirect_stdouts=None,
redirect_stdouts_level=None)
# 設置主動啟動beat是為了避免使用celery -A celery_demo worker 命令重復啟動worker
def run():
'''
啟動Beat
:return:
'''
beat.run()
def new_thread():
'''
創建一個線程啟動Beat 最多只能創建一個
:return:
'''
global flag
if not flag:
t = threading.Thread(target=run, daemon=True)
t.start()
# 啟動成功2s后才能操作定時任務 否則可能會報錯
time.sleep(2)
flag = True
def add_cron_task(task_name: str, cron_task: str, minute='*', hour='*', day_of_week='*', day_of_month='*',
month_of_year='*', **kwargs):
'''
創建或更新定時任務
:param task_name: 定時任務名稱
:param cron_task: task名稱
:param minute: 以下是時間
:param hour:
:param day_of_week:
:param day_of_month:
:param month_of_year:
:param kwargs:
:return:
'''
service = beat.get_service()
scheduler = service.scheduler
entries = dict()
entries[task_name] = {
'task': cron_task,
'schedule': crontab(minute=minute, hour=hour, day_of_week=day_of_week, day_of_month=day_of_month,
month_of_year=month_of_year, **kwargs),
'options': {'expires': 3600}}
scheduler.update_from_dict(entries)
def del_cron_task(task_name: str):
'''
刪除定時任務
:param task_name:
:return:
'''
service = beat.get_service()
scheduler = service.scheduler
if scheduler.schedule.get(task_name, None) is not None:
del scheduler.schedule[task_name]
def get_cron_task():
'''
獲取當前所有定時任務的配置
:return:
'''
service = beat.get_service()
scheduler = service.scheduler
ret = [{k: {"task": v.task, "crontab": v.schedule}} for k, v in scheduler.schedule.items()]
return ret看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





