溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關stack和unstack怎么在Python中使用,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
Python主要應用于:1、Web開發;2、數據科學研究;3、網絡爬蟲;4、嵌入式應用開發;5、游戲開發;6、桌面應用開發。
首先,要知道以下五點:
1.stack:將數據的列“旋轉”為行
2.unstack:將數據的行“旋轉”為列
3.stack和unstack默認操作為最內層
4.stack和unstack默認旋轉軸的級別將會成果結果中的最低級別(最內層)
5.stack和unstack為一組逆運算操作
第一點和第二點以及第五點比較好懂,可能乍看第三點和第四點會不太理解,沒關系,看看具體下面的例子,你就懂了。
import pandas as pd import numpy as np data = pd.DataFrame(np.arange(6).reshape((2,3)),index=pd.Index(['Ohio','Colorado'],name='state') ,columns=pd.Index(['one','two','three'],name='number')) data
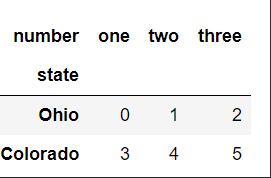
result = data.stack() result

從下圖中結果來理解上述點4,stack操作后將列索引number旋轉為行索引,并且置于行索引的最內層(外層為索引state),也就是將旋轉軸(number)的結果置于 最低級別。
result.unstack()
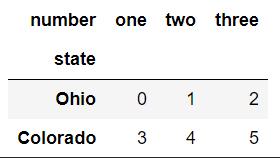
從下面結果理解上述點3,unstack操作默認將內層索引number旋轉為列索引。
同時,也可以指定分層級別或者索引名稱來指定操作級別,下面做錯同樣會得到上面的結果。
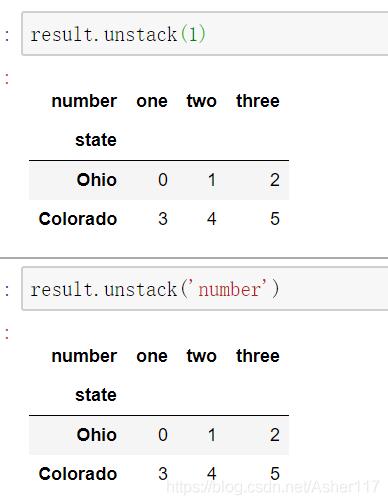
s1 = pd.Series([0,1,2,3],index=list('abcd'))
s2 = pd.Series([4,5,6],index=list('cde'))
data2 = pd.concat([s1,s2],keys=['one','two'])
data2
data2.unstack().stack()

補充:使用Pivot、Pivot_Table、Stack和Unstack等方法在Pandas中對數據變形(重塑)
Pandas是著名的Python數據分析包,這使它更容易讀取和轉換數據。在Pandas中數據變形意味著轉換表或向量(即DataFrame或Series)的結構,使其進一步適合做其他分析。在本文中,小編將舉例說明最常見的一些Pandas重塑功能。
pivot函數用于從給定的表中創建出新的派生表,pivot有三個參數:索引、列和值。具體如下:
def pivot_simple(index, columns, values): """ Produce 'pivot' table based on 3 columns of this DataFrame. Uses unique values from index / columns and fills with values. Parameters ---------- index : ndarray Labels to use to make new frame's index columns : ndarray Labels to use to make new frame's columns values : ndarray Values to use for populating new frame's values
作為這些參數的值需要事先在原始的表中指定好對應的列名。然后,pivot函數將創建一個新表,其行和列索引是相應參數的唯一值。我們一起來看一下下面這個例子:
假設我們有以下數據:

我們將數據讀取進來:
from collections import OrderedDict
from pandas import DataFrame
import pandas as pd
import numpy as np
data = OrderedDict((
("item", ['Item1', 'Item1', 'Item2', 'Item2']),
('color', ['red', 'blue', 'red', 'black']),
('user', ['1', '2', '3', '4']),
('bm', ['1', '2', '3', '4'])
))
data = DataFrame(data)
print(data)得到結果為:
item color user bm 0 Item1 red 1 1 1 Item1 blue 2 2 2 Item2 red 3 3 3 Item2 black 4 4
接下來,我們對以上數據進行變形:
df = data.pivot(index='item', columns='color', values='user') print(df)
得到的結果為:
color black blue red item Item1 None 2 1 Item2 4 None 3
注意:可以使用以下方法對原始數據和轉換后的數據進行等效查詢:
# 原始數據集 print(data[(data.item=='Item1') & (data.color=='red')].user.values) # 變換后的數據集 print(df[df.index=='Item1'].red.values)
結果為:
['1'] ['1']
在以上的示例中,轉化后的數據不包含bm的信息,它僅包含我們在pivot方法中指定列的信息。下面我們對上面的例子進行擴展,使其在包含user信息的同時也包含bm信息。
df2 = data.pivot(index='item', columns='color') print(df2)
結果為:
user bm color black blue red black blue red item Item1 None 2 1 None 2 1 Item2 4 None 3 4 None 3
從結果中我們可以看出:Pandas為新表創建了分層列索引。我們可以用這些分層列索引來過濾出單個列的值,例如:使用df2.user可以得到user列中的值。
有如下例子:
data = OrderedDict((
("item", ['Item1', 'Item1', 'Item1', 'Item2']),
('color', ['red', 'blue', 'red', 'black']),
('user', ['1', '2', '3', '4']),
('bm', ['1', '2', '3', '4'])
))
data = DataFrame(data)
df = data.pivot(index='item', columns='color', values='user')得到的結果為:
ValueError: Index contains duplicate entries, cannot reshape
因此,在調用pivot函數之前,我們必須確保我們指定的列和行沒有重復的數據。如果我們無法確保這一點,我們可以使用pivot_table這個方法。
pivot_table方法實現了類似pivot方法的功能,它可以在指定的列和行有重復的情況下使用,我們可以使用均值、中值或其他的聚合函數來計算重復條目中的單個值。
首先,我們先來看一下pivot_table()這個方法:
def pivot_table(data, values=None, index=None, columns=None, aggfunc='mean',
fill_value=None, margins=False, dropna=True,
margins_name='All'):
"""
Create a spreadsheet-style pivot table as a DataFrame. The levels in the
pivot table will be stored in MultiIndex objects (hierarchical indexes) on
the index and columns of the result DataFrame
Parameters
----------
data : DataFrame
values : column to aggregate, optional
index : column, Grouper, array, or list of the previous
If an array is passed, it must be the same length as the data. The list
can contain any of the other types (except list).
Keys to group by on the pivot table index. If an array is passed, it
is being used as the same manner as column values.
columns : column, Grouper, array, or list of the previous
If an array is passed, it must be the same length as the data. The list
can contain any of the other types (except list).
Keys to group by on the pivot table column. If an array is passed, it
is being used as the same manner as column values.
aggfunc : function or list of functions, default numpy.mean
If list of functions passed, the resulting pivot table will have
hierarchical columns whose top level are the function names (inferred
from the function objects themselves)
fill_value : scalar, default None
Value to replace missing values with
margins : boolean, default False
Add all row / columns (e.g. for subtotal / grand totals)
dropna : boolean, default True
Do not include columns whose entries are all NaN
margins_name : string, default 'All'
Name of the row / column that will contain the totals
when margins is True.
接下來我們來看一個示例:
data = OrderedDict((
("item", ['Item1', 'Item1', 'Item1', 'Item2']),
('color', ['red', 'blue', 'red', 'black']),
('user', ['1', '2', '3', '4']),
('bm', ['1', '2', '3', '4'])
))
data = DataFrame(data)
df = data.pivot_table(index='item', columns='color', values='user', aggfunc=np.min)
print(df)結果為:
color black blue red item Item1 None 2 1 Item2 4 None None
實際上,pivot_table()是pivot()的泛化,它允許在數據集中聚合具有相同目標的多個值。
事實上,變換一個表只是堆疊DataFrame的一種特殊情況,假設我們有一個在行列上有多個索引的DataFrame。堆疊DataFrame意味著移動最里面的列索引成為最里面的行索引,反向操作稱之為取消堆疊,意味著將最里面的行索引移動為最里面的列索引。例如:
from pandas import DataFrame import pandas as pd import numpy as np # 建立多個行索引 row_idx_arr = list(zip(['r0', 'r0'], ['r-00', 'r-01'])) row_idx = pd.MultiIndex.from_tuples(row_idx_arr) # 建立多個列索引 col_idx_arr = list(zip(['c0', 'c0', 'c1'], ['c-00', 'c-01', 'c-10'])) col_idx = pd.MultiIndex.from_tuples(col_idx_arr) # 創建DataFrame d = DataFrame(np.arange(6).reshape(2,3), index=row_idx, columns=col_idx) d = d.applymap(lambda x: (x // 3, x % 3)) # Stack/Unstack s = d.stack() u = d.unstack() print(s) print(u)
得到的結果為:
c0 c1 r0 r-00 c-00 (0, 0) NaN c-01 (0, 1) NaN c-10 NaN (0, 2) r-01 c-00 (1, 0) NaN c-01 (1, 1) NaN c-10 NaN (1, 2) c0 c1 c-00 c-01 c-10 r-00 r-01 r-00 r-01 r-00 r-01 r0 (0, 0) (1, 0) (0, 1) (1, 1) (0, 2) (1, 2)
上述就是小編為大家分享的stack和unstack怎么在Python中使用了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





