溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Hadoop是一個由Apache基金會所開發的分布式系統基礎架構。用戶可以在不了解分布式底層細節的情況下,開發分布式程序。充分利用集群的威力進行高速運算和存儲。具有可靠、高效、可伸縮的特點。
Hadoop的核心是YARN,HDFS和Mapreduce
下圖是hadoop生態系統,集成spark生態圈。在未來一段時間內,hadoop將于spark共存,hadoop與spark都能部署在yarn、mesos的資源管理系統之上。
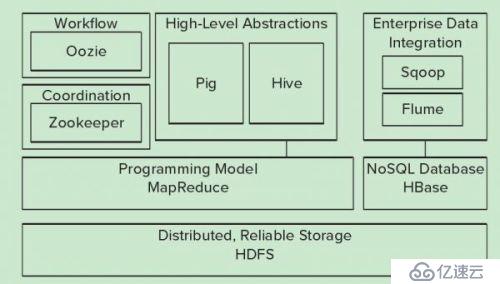
源自于Google的GFS論文,發表于2003年10月,HDFS是GFS克隆版。
HDFS是Hadoop體系中數據存儲管理的基礎。它是一個高度容錯的系統,能檢測和應對硬件故障,用于在低成本的通用硬件上運行。
HDFS簡化了文件的一致性模型,通過流式數據訪問,提供高吞吐量應用程序數據訪問功能,適合帶有大型數據集的應用程序。
它提供了一次寫入多次讀取的機制,數據以塊的形式,同時分布在集群不同物理機器上。
源自于google的MapReduce論文,發表于2004年12月,HadoopMapReduce是google MapReduce 克隆版。
MapReduce是一種分布式計算模型,用以進行大數據量的計算。它屏蔽了分布式計算框架細節,將計算抽象成map和reduce兩部分,
其中Map對數據集上的獨立元素進行指定的操作,生成鍵-值對形式中間結果。Reduce則對中間結果中相同“鍵”的所有“值”進行規約,以得到最終結果。
MapReduce非常適合在大量計算機組成的分布式并行環境里進行數據處理。
源自Google的Bigtable論文,發表于2006年11月,HBase是GoogleBigtable克隆版。
HBase是一個建立在HDFS之上,面向列的針對結構化數據的可伸縮、高可靠、高性能、分布式和面向列的動態模式數據庫。
HBase采用了BigTable的數據模型:增強的稀疏排序映射表(Key/Value),其中,鍵由行關鍵字、列關鍵字和時間戳構成。
HBase提供了對大規模數據的隨機、實時讀寫訪問,同時,HBase中保存的數據可以使用MapReduce來處理,它將數據存儲和并行計算完美地結合在一起。
源自Google的Chubby論文,發表于2006年11月,Zookeeper是Chubby克隆版
解決分布式環境下的數據管理問題:統一命名,狀態同步,集群管理,配置同步等
Hadoop的許多組件依賴于Zookeeper,它運行在計算機集群上面,用于管理Hadoop操作。
由facebook開源,最初用于解決海量結構化的日志數據統計問題。
Hive定義了一種類似SQL的查詢語言(HQL),將SQL轉化為MapReduce任務在Hadoop上執行。通常用于離線分析。
HQL用于運行存儲在Hadoop上的查詢語句,Hive讓不熟悉MapReduce開發人員也能編寫數據查詢語句,然后這些語句被翻譯為Hadoop上面的MapReduce任務。
由yahoo!開源,設計動機是提供一種基于MapReduce的ad-hoc(計算在query時發生)數據分析工具
Pig定義了一種數據流語言—PigLatin,它是MapReduce編程的復雜性的抽象,Pig平臺包括運行環境和用于分析Hadoop數據集的腳本語言(Pig Latin)。
其編譯器將Pig Latin翻譯成MapReduce程序序列將腳本轉換為MapReduce任務在Hadoop上執行。通常用于進行離線分析。
Sqoop是SQL-to-Hadoop的縮寫,主要用于傳統數據庫和Hadoop之前傳輸數據。數據的導入和導出本質上是Mapreduce程序,充分利用了MR的并行化和容錯性。
Sqoop利用數據庫技術描述數據架構,用于在關系數據庫、數據倉庫和Hadoop之間轉移數據。
Cloudera開源的日志收集系統,具有分布式、高可靠、高容錯、易于定制和擴展的特點。
它將數據從產生、傳輸、處理并最終寫入目標的路徑的過程抽象為數據流,在具體的數據流中,數據源支持在Flume中定制數據發送方,從而支持收集各種不同協議數據。
同時,Flume數據流提供對日志數據進行簡單處理的能力,如過濾、格式轉換等。此外,Flume還具有能夠將日志寫往各種數據目標(可定制)的能力。
總的來說,Flume是一個可擴展、適合復雜環境的海量日志收集系統。當然也可以用于收集其他類型數據
Oozie是一個可擴展的工作體系,集成于Hadoop的堆棧,用于協調多個MapReduce作業的執行。它能夠管理一個復雜的系統,基于外部事件來執行,外部事件包括數據的定時和數據的出現。
Oozie工作流是放置在控制依賴DAG(有向無環圖 DirectAcyclic Graph)中的一組動作(例如,Hadoop的Map/Reduce作業、Pig作業等),其中指定了動作執行的順序。
Oozie使用hPDL(一種XML流程定義語言)來描述這個圖。
YARN是下一代MapReduce,即MRv2,是在第一代MapReduce基礎上演變而來的,主要是為了解決原始Hadoop擴展性較差,不支持多計算框架而提出的。
yarn是下一代 Hadoop 計算平臺,yarn是一個通用的運行時框架,用戶可以編寫自己的計算框架,在該運行環境中運行。
用于自己編寫的框架作為客戶端的一個lib,在運用提交作業時打包即可。該框架為提供了以下幾個組件:
資源管理:包括應用程序管理和機器資源管理
資源雙層調度
容錯性:各個組件均有考慮容錯性
擴展性:可擴展到上萬個節點
Spark是一個Apache項目,它被標榜為“快如閃電的集群計算”。它擁有一個繁榮的開源社區,并且是目前最活躍的Apache項目。
最早Spark是UC BerkeleyAMP lab所開源的類Hadoop MapReduce的通用的并行計算框架。
Spark提供了一個更快、更通用的數據處理平臺。和Hadoop相比,Spark可以讓你的程序在內存中運行時速度提升100倍,或者在磁盤上運行時速度提升10倍
Kafka是Linkedin于2010年12月份開源的消息系統,它主要用于處理活躍的流式數據。
活躍的流式數據在web網站應用中非常常見,這些數據包括網站的pv、用戶訪問了什么內容,搜索了什么內容等。
這些數據通常以日志的形式記錄下來,然后每隔一段時間進行一次統計處理。
Apache Ambari 的作用來說,就是創建、管理、監視 Hadoop 的集群,是為了讓 Hadoop 以及相關的大數據軟件更容易使用的一個web工具。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





