溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文章向大家介紹使用golang怎么實現一個布谷鳥過濾器的基本知識點總結和需要注意事項,具有一定的參考價值,需要的朋友可以參考一下。
golang可以做服務器端開發,但golang很適合做日志處理、數據打包、虛擬機處理、數據庫代理等工作。在網絡編程方面,它還廣泛應用于web應用、API應用等領域。
實現原理
簡單工作原理
可以簡單的把布谷鳥過濾器里面有兩個 hash 表T1、T2,兩個 hash 表對應兩個 hash 函數H1、H2。
具體的插入步驟如下:
當一個不存在的元素插入的時候,會先根據 H1 計算出其在 T1 表的位置,如果該位置為空則可以放進去。
如果該位置不為空,則根據 H2 計算出其在 T2 表的位置,如果該位置為空則可以放進去。
如果T1 表和 T2 表的位置元素都不為空,那么就隨機的選擇一個 hash 表將其元素踢出。
被踢出的元素會循環的去找自己的另一個位置,如果被暫了也會隨機選擇一個將其踢出,被踢出的元素又會循環找位置;
如果出現循環踢出導致放不進元素的情況,那么會設置一個閾值,超出了某個閾值,就認為這個 hash 表已經幾乎滿了,這時候就需要對它進行擴容,重新放置所有元素。
下面舉一個例子來說明:
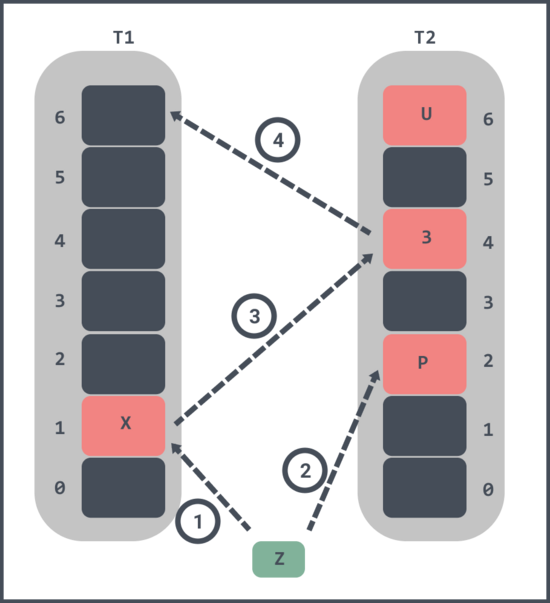
如果想要插入一個元素Z到過濾器里:
首先會將Z進行 hash 計算,發現 T1 和 T2 對應的槽位1和槽位2都已經被占了;
隨機將 T1 中的槽位1中的元素 X 踢出,X 的 T2 對應的槽位4已經被元素 3 占了;
將 T2 中的槽位4中的元素 3 踢出,元素 3 在 hash 計算之后發現 T1 的槽位6是空的,那么將元素3放入到 T1 的槽位6中。
當 Z 插入完畢之后如下:
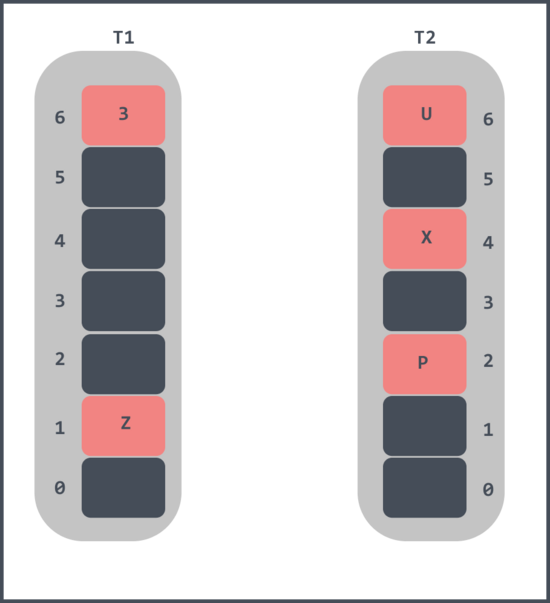
布谷鳥過濾器
布谷鳥過濾器和上面的實現原理結構是差不多的,不同的是上面的數組結構會存儲整個元素,而布谷鳥過濾器中只會存儲元素的幾個 bit ,稱作指紋信息。這里是犧牲了數據的精確性換取了空間效率。
上面的實現方案中,hash 表中每個槽位只能存放一個元素,空間利用率只有50%,而在布谷鳥過濾器中每個槽位可以存放多個元素,從一維變成了二維。論文中表示:
With k = 2 hash functions, the load factor α is 50% when the bucket size b = 1 (i.e., the hash table is directly mapped), but increases to 84%, 95% or 98% respectively using bucket size b = 2, 4 or 8.
也就是當有兩個 hash 函數的時候,使用一維數組空間利用率只有50%,當每個槽位可以存放2,4,8個元素的時候,空間利用率就會飆升到 84%,95%,98%。
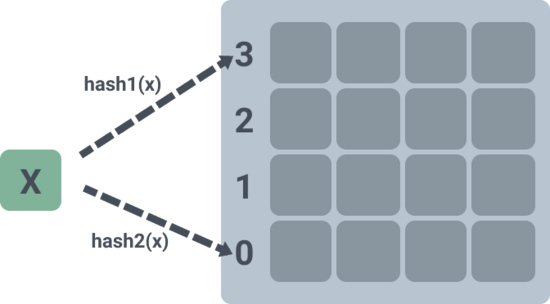
如下圖,表示的是一個二維數組,每個槽位可以存放 4 個元素,和上面的實現有所不同的是,沒有采用兩個數組來存放,而是只用了一個:
說完了數據結構的改變,下面再說說位置計算的改變。
我們在上面簡單實現的位置計算公式是這樣做的:
p1 = hash2(x) % 數組長度 p2 = hash3(x) % 數組長度
而布谷鳥過濾器計算位置公式可以在論文中看到是這樣:
f = fingerprint(x); i1 = hash(x); i2 = i1 ⊕ hash( f);
我們可以看到在計算位置 i2 的時候是通過 i1 和元素 X 對應的指紋信息取異或計算出來。指紋信息在上面已經解釋過了,是元素 X 的幾個 bit ,犧牲了一定精度,但是換取了空間。
那么這里為什么需要用到異或呢?因為這樣可以用到異或的自反性: A ⊕ B ⊕ B = A ,這樣就不需要知道當前的位置是 i1 還是 i2,只需要將當前的位置和 hash(f) 進行異或計算就可以得到另一個位置。
這里有個細節需要注意的是,計算 i2 的時候是需要先將元素 X 的 fingerprint 進行 hash ,然后才取異或,論文也說明了:
If the alternate location were calculated by “i⊕fingerprint” without hashing the fingerprint, the items kicked out from nearby buckets would land close to each other in the table, if the size of the fingerprint is small compared to the table size.
如果直接進行異或處理,那么很可能 i1 和 i2 的位置相隔很近,尤其是在比較小的 hash 表中,這樣無形之中增加了碰撞的概率。
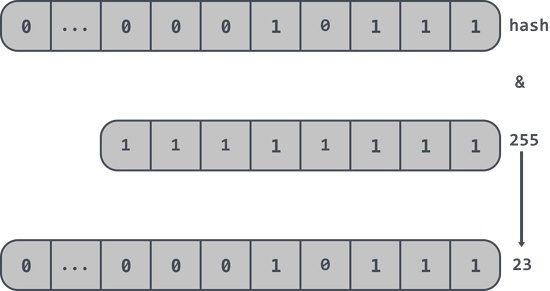
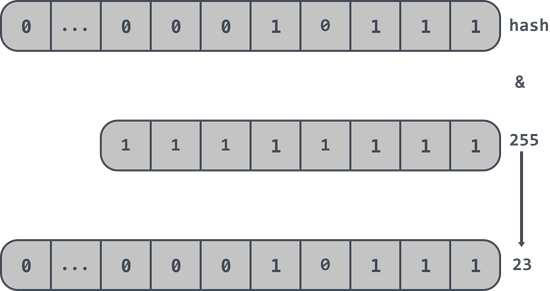
除此之外還有一個約束條件是布谷鳥過濾器強制數組的長度必須是 2 的指數,所以在布谷鳥過濾器中不需要對數組的長度取模,取而代之的是取 hash 值的最后 n 位。
如一個布谷鳥過濾器中數組的長度2^8即256,那么取 hash 值的最后 n 位即: hash & 255 這樣就可以得到最終的位置信息。如下最后得到位置信息是 23 :
代碼實現
數據結構
const bucketSize = 4
type fingerprint byte
// 二維數組,大小是4
type bucket [bucketSize]fingerprint
type Filter struct {
// 一維數組
buckets []bucket
// Filter 中已插入的元素
count uint
// 數組buckets長度中對應二進制包含0的個數
bucketPow uint
}在這里我們假定一個指紋 fingerprint 占用的字節數是 1byte ,每個位置有 4 個座位。
初始化
var (
altHash = [256]uint{}
masks = [65]uint{}
)
func init() {
for i := 0; i < 256; i++ {
// 用于緩存 256 個fingerprint的hash信息
altHash[i] = (uint(metro.Hash74([]byte{byte(i)}, 1337)))
}
for i := uint(0); i <= 64; i++ {
// 取 hash 值的最后 n 位
masks[i] = (1 << i) - 1
}
}這個 init 函數會緩存初始化兩個全局變量 altHash 和 masks。因為 fingerprint 長度是 1byte ,所以在初始化 altHash 的時候使用一個 256 大小的數組取緩存對應的 hash 信息,避免每次都需要重新計算;masks 是用來取 hash 值的最后 n 位,稍后會用到。
我們會使用一個 NewFilter 函數,通過傳入過濾器可容納大小來獲取過濾器 Filter:
func NewFilter(capacity uint) *Filter {
// 計算 buckets 數組大小
capacity = getNextPow2(uint64(capacity)) / bucketSize
if capacity == 0 {
capacity = 1
}
buckets := make([]bucket, capacity)
return &Filter{
buckets: buckets,
count: 0,
// 獲取 buckets 數組大小的二進制中以 0 結尾的個數
bucketPow: uint(bits.TrailingZeros(capacity)),
}
}NewFilter 函數會通過 getNextPow2 將 capacity 調整到 2 的指數倍,如果傳入的 capacity 是 9 ,那么調用 getNextPow2 后會返回 16;然后計算好 buckets 數組長度,實例化 Filter 返回;bucketPow 返回的是二進制中以 0 結尾的個數,因為 capacity 是 2 的指數倍,所以 bucketPow 是 capacity 二進制的位數減 1。
func (cf *Filter) Insert(data []byte) bool {
// 獲取 data 的 fingerprint 以及 位置 i1
i1, fp := getIndexAndFingerprint(data, cf.bucketPow)
// 將 fingerprint 插入到 Filter 的 buckets 數組中
if cf.insert(fp, i1) {
return true
}
// 獲取位置 i2
i2 := getAltIndex(fp, i1, cf.bucketPow)
// 將 fingerprint 插入到 Filter 的 buckets 數組中
if cf.insert(fp, i2) {
return true
}
// 插入失敗,那么進行循環插入踢出元素
return cf.reinsert(fp, randi(i1, i2))
}
func (cf *Filter) insert(fp fingerprint, i uint) bool {
// 獲取 buckets 中的槽位進行插入
if cf.buckets[i].insert(fp) {
// Filter 中元素個數+1
cf.count++
return true
}
return false
}
func (b *bucket) insert(fp fingerprint) bool {
// 遍歷槽位的 4 個元素,如果為空則插入
for i, tfp := range b {
if tfp == nullFp {
b[i] = fp
return true
}
}
return false
}getIndexAndFingerprint 函數會獲取 data 的指紋 fingerprint,以及位置 i1;
然后調用 insert 插入到 Filter 的 buckets 數組中,如果 buckets 數組中對應的槽位 i1 的 4 個元素已經滿了,那么嘗試獲取位置 i2 ,并將元素嘗試插入到 buckets 數組中對應的槽位 i2 中;
對應的槽位 i2 也滿了,那么 調用 reinsert 方法隨機獲取槽位 i1、i2 中的某個位置進行搶占,然后將老元素踢出并循環重復插入。
下面看看 getIndexAndFingerprint 是如何獲取 fingerprint 以及槽位 i1:
func getIndexAndFingerprint(data []byte, bucketPow uint) (uint, fingerprint) {
// 將 data 進行hash
hash := metro.Hash74(data, 1337)
// 取 hash 的指紋信息
fp := getFingerprint(hash)
// 取 hash 高32位,對 hash 的高32位進行取與獲取槽位 i1
i1 := uint(hash>>32) & masks[bucketPow]
return i1, fingerprint(fp)
}
// 取 hash 的指紋信息
func getFingerprint(hash uint64) byte {
fp := byte(hash%255 + 1)
return fp
}getIndexAndFingerprint 中對 data 進行 hash 完后會對其結果取模獲取指紋信息,然后再取 hash 值的高 32 位進行取與,獲取槽位 i1。masks 在初始化的時候已經看過了, masks[bucketPow] 獲取的二進制結果全是 1 ,用來取 hash 的低位的值。
假如初始化傳入的 capacity 是1024,那么計算到 bucketPow 是 8,對應取到 masks[8] = (1 << 8) - 1 結果是 255 ,二進制是 1111,1111 ,和 hash 的高 32 取與 得到最后 buckets 中的槽位 i1 :
func getAltIndex(fp fingerprint, i uint, bucketPow uint) uint {
mask := masks[bucketPow]
hash := altHash[fp] & mask
return i ^ hash
}getAltIndex 中獲取槽位是通過使用 altHash 來獲取指紋信息的 hash 值,然后取異或后返回槽位值。需要注意的是,這里由于異或的特性,所以傳入的不管是槽位 i1,還是槽位 i2 都可以返回對應的另一個槽位。
下面看看循環踢出插入 reinsert:
const maxCuckooCount = 500
func (cf *Filter) reinsert(fp fingerprint, i uint) bool {
// 默認循環 500 次
for k := 0; k < maxCuckooCount; k++ {
// 隨機從槽位中選取一個元素
j := rand.Intn(bucketSize)
oldfp := fp
// 獲取槽位中的值
fp = cf.buckets[i][j]
// 將當前循環的值插入
cf.buckets[i][j] = oldfp
// 獲取另一個槽位
i = getAltIndex(fp, i, cf.bucketPow)
if cf.insert(fp, i) {
return true
}
}
return false
}這里會最大循環 500 次獲取槽位信息。因為每個槽位最多可以存放 4 個元素,所以使用 rand 隨機從 4 個位置中取一個元素踢出,然后將當次循環的元素插入,再獲取被踢出元素的另一個槽位信息,再調用 insert 進行插入。
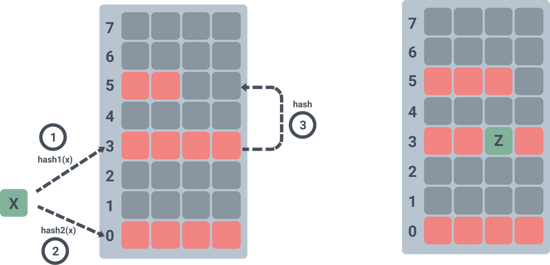
上圖展示了元素 X 在插入到 hash 表的時候,hash 兩次發現對應的槽位 0 和 3 都已經滿了,那么隨機搶占了槽位 3 其中一個元素,被搶占的元素重新 hash 之后插入到槽位 5 的第三個位置上。
查詢數據
查詢數據的時候,就是看看對應的位置上有沒有對應的指紋信息:
func (cf *Filter) Lookup(data []byte) bool {
// 獲取槽位 i1 以及指紋信息
i1, fp := getIndexAndFingerprint(data, cf.bucketPow)
// 遍歷槽位中 4 個位置,查看有沒有相同元素
if cf.buckets[i1].getFingerprintIndex(fp) > -1 {
return true
}
// 獲取另一個槽位 i2
i2 := getAltIndex(fp, i1, cf.bucketPow)
// 遍歷槽位 i2 中 4 個位置,查看有沒有相同元素
return cf.buckets[i2].getFingerprintIndex(fp) > -1
}
func (b *bucket) getFingerprintIndex(fp fingerprint) int {
for i, tfp := range b {
if tfp == fp {
return i
}
}
return -1
}刪除數據
刪除數據的時候,也只是抹掉該槽位上的指紋信息:
func (cf *Filter) Delete(data []byte) bool {
// 獲取槽位 i1 以及指紋信息
i1, fp := getIndexAndFingerprint(data, cf.bucketPow)
// 嘗試刪除指紋信息
if cf.delete(fp, i1) {
return true
}
// 獲取槽位 i2
i2 := getAltIndex(fp, i1, cf.bucketPow)
// 嘗試刪除指紋信息
return cf.delete(fp, i2)
}
func (cf *Filter) delete(fp fingerprint, i uint) bool {
// 遍歷槽位 4個元素,嘗試刪除指紋信息
if cf.buckets[i].delete(fp) {
if cf.count > 0 {
cf.count--
}
return true
}
return false
}
func (b *bucket) delete(fp fingerprint) bool {
for i, tfp := range b {
// 指紋信息相同,將此槽位置空
if tfp == fp {
b[i] = nullFp
return true
}
}
return false
}缺點
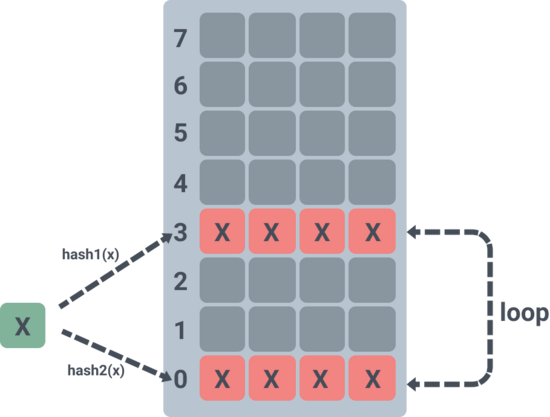
實現完布谷鳥過濾器后,我們不妨想一下,如果布谷鳥過濾器對同一個元素進行多次連續的插入會怎樣?
那么這個元素會霸占兩個槽位上的所有位置,最后在插入第 9 個相同元素的時候,會一直循環擠兌,直到最大循環次數,然后返回一個 false:
如果插入之前做一次檢查能不能解決問題呢?這樣確實不會出現循環擠兌的情況,但是會出現一定概率的誤判情況。
由上面的實現我們可以知道,在每個位置里設置的指紋信息是 1byte,256 種可能,如果兩個元素的 hash 位置相同,指紋相同,那么這個插入檢查會認為它們是相等的導致認為元素已存在。
事實上,我們可以通過調整指紋信息的保存量來降低誤判情況,如在上面的實現中,指紋信息是 1byte 保存8位信息誤判概率是0.03,當指紋信息增加到 2bytes 保存16位信息誤判概率會降低至 0.0001。
以上就是小編為大家帶來的使用golang怎么實現一個布谷鳥過濾器的全部內容了,希望大家多多支持億速云!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





